










1.引言
** 本项目由GitHub项目改进,建议直接拉取到 2.2相关模块 开始阅读 **
1.1项目背景
| 临近毕业,毕业生都是在手机APP和电脑网站查询自己相应的招聘岗位,在这种情况下查看招聘岗位不但费时,而且费眼睛,还不能将已经查看过的数据进行可视化统计,所以想知道招聘岗位的具体情况很是麻烦。|
|-----------------------------------------------------------------------------------------------|-
1.2项目意义
|此项目完成之后将大大节约我们查找招聘岗位的时间,它的重大意义是让我们查看工作岗位信息数据进行了数据化、规范化、自动化、可视化管理。它可以帮助我们了解行业的薪资分布、城市岗位分布、岗位要求关键字、岗位经验要求等等一系列的数据。|
|----------------------------------------------------------------------------------------------------------------|–|
1.3实现功能
|项目需要实现:①可由用户选择爬取哪种或哪些岗位的招聘信息、②可由用户选择爬取招聘信息的城市(全国可选)、③将爬取的数据存储到mysql或者csv文件中、④将mysql或csv文件中的数据取出并以字典的形式存在、⑤将数据进行可视化、⑥将可视化的数据进行分类。|
|--------------------------------------------------------------------------------------------------------------------------------|–|
2.系统结构
2.1相关技术
2.1.1系统开发语言:python
-
- 本系统采用的语言是python。
-
- Python是一种跨平台的计算机程序设计语言。 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。
-
- Python特点:
-
-
- 3.1 简单:Python是一种代表简单主义思想的语言。阅读一个良好的Python程序就感觉像是在读英语一样。它使你能够专注于解决问题而不是去搞明白语言本身。
-
-
-
- 3.2 易学:Python极其容易上手,因为Python有极其简单的说明文档。
-
-
-
- 3.3 速度快:Python 的底层是用 C语言写的,很多标准库和第三方库也都是用 C 写的,运行速度非常快。
-
-
-
- 3.4 免费、开源:Python是FLOSS(自由/开放源码软件)之一。使用者可以自由地发布这个软件的拷贝、阅读它的源代码、对它做改动、把它的一部分用于新的自由软件中。FLOSS是基于一个团体分享知识的概念。
-
-
-
- 3.5 高层语言:用Python语言编写程序的时候无需考虑诸如如何管理你的程序使用的内存一类的底层细节。
-
-
-
- 3.6 可移植性:由于它的开源本质,Python已经被移植在许多平台上(经过改动使它能够工作在不同平台上)。
-
-
-
- 3.7 解释性:一个用编译性语言比如C或C++写的程序可以从源文件(即C或C++语言)转换到一个你的计算机使用的语言(二进制代码,即0和1)。这个过程通过编译器和不同的标记、选项完成。
-
-
-
- 3.8 运行程序的时候,连接/转载器软件把你的程序从硬盘复制到内存中并且运行。而Python语言写的程序不需要编译成二进制代码。你可以直接从源代码运行
程序。
- 3.8 运行程序的时候,连接/转载器软件把你的程序从硬盘复制到内存中并且运行。而Python语言写的程序不需要编译成二进制代码。你可以直接从源代码运行
-
-
-
- 3.9 在计算机内部,Python解释器把源代码转换成称为字节码的中间形式,然后再把它翻译成计算机使用的机器语言并运行。这使得使用Python更加简单。也使得Python程序更加易于移植。
-
-
-
- 3.10 面向对象:Python既支持面向过程的编程也支持面向对象的编程。在“面向过程”的语言中,程序是由过程或仅仅是可重用代码的函数构建起来的。在“面向对象”的语言中,程序是由数据和功能组合而成的对象构建起来的。
-
-
-
- 3.11 可扩展性:如果需要一段关键代码运行得更快或者希望某些算法不公开,可以部分程序用C或C++编写,然后在Python程序中使用它们。
-
-
-
- 3.12 可嵌入性:可以把Python嵌入C/C++程序,从而向程序用户提供脚本功能。
-
-
-
- 3.13 丰富的库:Python标准库确实很庞大。它可以帮助处理各种工作,包括正则表达式、文档生成、单元测试、线程、数据库、网页浏览器、CGI、FTP、电子邮件、XML、XML-RPC、HTML、WAV文件、密码系统、GUI(图形用户界面)、Tk和其他与系统有关的操作。这被称作Python的“功能齐全”理念。除了标准库以外,还有许多其他高质量的库,如wxPython、Twisted和Python图像库等等。
-
-
-
- 3.14 规范的代码:Python采用强制缩进的方式使得代码具有较好可读性。而Python语言写的程序不需要编译成二进制代码。
-
2.1.2 MySQL数据库
|MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,属于 Oracle 旗下产品。MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。|
|---------------------------------------------------------------------------------------------------------------------------------------------------------------|–|
|MySQL的特点有很多:比如可移植性强、支持多种操作系统等等。 |
2.1.3 Pycharm开发工具
|PyCharm是一种Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制。此外,该IDE提供了一些高级功能,以用于支持Django框架下的专业Web开发。|
|--------------------------------------------------------------------------------------------------------------------------------------------|–|
| 特点:PyCharm拥有一般IDE具备的功能,比如, 调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制 | |
2.1.4 cookie技术
|Cookie 并不是它的原意“甜饼”的意思, 而是一个保存在客户机中的简单的文本文件, 这个文件与特定的 Web 文档关联在一起, 保存了该客户机访问这个Web 文档时的信息, 当客户机再次访问这个 Web 文档时这些信息可供该文档使用。由于“Cookie”具有可以保存在客户机上的神奇特性, 因此它可以帮助我们实现记录用户个人信息的功能, 而这一切都不必使用复杂的CGI等程序。|
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|–|
2.1.5 其他技术
|CSS、HTML5、JS。|
|-------------|–|
2.2相关模块
2.2.1 configures模块
|configures模块主要用于存放配置文件以及cookie文件等。|
|----------------------------------|–|
2.2.2 lagou_data模块
|lagou_data模块主要是存放csv文件,csv文件是将爬取的数据进行一个保存。|
|------------------------------------------|–|
2.2.3 report模块
|report模块主要是实现可视化功能,里面涉及一些html5、css、js等一系列文件。|
|--------------------------------------------|–|
2.2.4 utils模块
|utils模块主要是存放一些基础类以及数据库类|
|-----------------------|–|
2.2.5主模块
|主模块主要是存放爬虫的类以及可视化类和依赖库的文本|
|-------------------------|–|
|图1系统模块结构 |
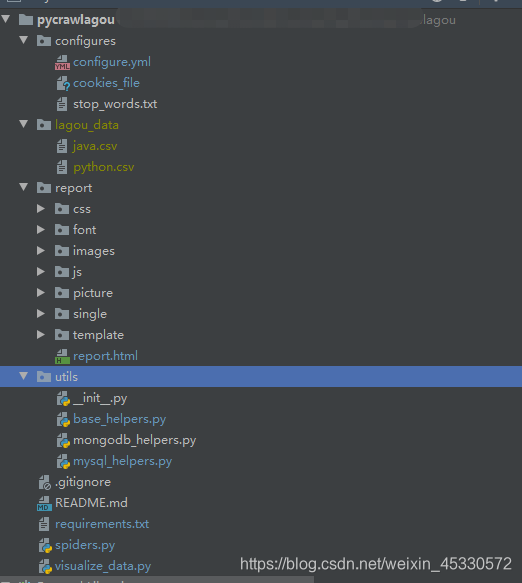
2.2.6数据库模块
2.2.6.1数据库代码
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for java
-- ----------------------------
DROP TABLE IF EXISTS `java`;
CREATE TABLE `java` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`jobId` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`jobUrl` text CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`jobName` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`salary` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`experience` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`education` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`jobType` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`city` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`address` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`advantage` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL,
`requirement` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL,
`company_name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`company_nickname` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`company_field` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`company_investment` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`company_scale` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`company_size` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`company_link` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`source` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 2 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for python
-- ----------------------------
DROP TABLE IF EXISTS `python`;
CREATE TABLE `python` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`jobId` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`jobUrl` text CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`jobName` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`salary` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`experience` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`education` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`jobType` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`city` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`address` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`advantage` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL,
`requirement` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL,
`company_name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`company_nickname` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`company_field` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`company_investment` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`company_scale` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`company_size` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`company_link` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`source` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 2 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
2.2.6.2数据库表设计
| 字段名 | 数据类型 | 长度 | 是否可null | 备注 |
|---|---|---|---|---|
| id | int | 11 | 否 | Id主键 |
| jobId | varchar | 255 | 否 | 岗位id |
| jobUrl | text | 0 | 否 | 岗位url(自动存储长度为0) |
| jobName | varchar | 255 | 是 | 岗位名称 |
| salary | varchar | 255 | 是 | 薪资 |
| experience | varchar | 255 | 是 | 工作经验 |
| education | varchar | 255 | 是 | 学历要求 |
| jobType | varchar | 255 | 是 | 工作性质 |
| city | varchar | 255 | 是 | 城市 |
| address | varchar | 255 | 是 | 公司地址 |
| advantage | text | 0 | 是 | 福利(优势)(自动存储长度为0) |
| requirement | text | 0 | 是 | 招聘要求(自动存储长度为0) |
| company_name | varchar | 255 | 是 | 公司全称 |
| company_nickname | varchar | 255 | 是 | 公司别称 |
| company_field | varchar | 255 | 是 | 公司涉及领域 |
| company_investment | varchar | 255 | 是 | 公司融资情况 |
| company_scale | varchar | 255 | 是 | 公司阶段 |
| company_size | varchar | 255 | 是 | 公司规模 |
| company_link | varchar | 255 | 是 | 公司链接 |
| source | varchar | 255 | 是 | 来源 |
3.相关代码
因涉及到原作者的代码,所以这里只展示我本人修改过的部分代码,由于篇幅和排版问题,本人修改过的其他代码将在CSDN给出,其他代码请移步到GitHub上面进行获取,GitHub链接将在本文最后给出,谢谢理解!
3.1 configures.yml
# MySqlDB 配置, 若爬虫配置save_method为database, 需要设置MySqlDB
mysql_db:
db_host: '127.0.0.1' # 服务器
db_port: 3306 # 端口
db_username: 'root' # 用户
db_password: '123456' # 密码
# 爬虫配置
lagou:
keyword: [python, java] # 搜索关键字, 为空则代表按照左侧导航栏分类进行全网爬取
username: # 拉勾登录账号
password: # 拉勾登录密码
sleep_interval: 1 # 关键动作时间的时间间隔, 时间尽量不要太快, 避免触发反爬虫机制
save_method: mysql_db # 保存方法, 分别为file, mysql, mongodb
save_file_path: lagou_data # 若保存为 file, 指定具体文件保存路径
# 可视化配置
visualize:
keyword: [java, python] # 关键字, 指定数据分类, 为空则代表按照统计所有数据
save_method: mysql_db # 获取数据的方法, 分别为file, mysql, mongodb
3.2 base_helpers.py
# 默认常用城市
COMMON_CITIES = ['深圳', '广州']
#COMMON_CITIES = ['全国', '北京', '上海', '深圳', '广州', '杭州', '成都', '南京', '武汉', '西安', '厦门', '长沙', '苏州', '天津']
3.3 mysql_helpers.py
import MySQLdb
import MySQLdb.cursors
#配置数据库初始方法,除了数据库名称以外,均有默认值。
class MySQLHelper(object):
def __init__(self, database, db_username='root', db_password='123456', db_host='127.0.0.1', db_port=3306):
self.database = database
self.db_username = db_username
self.db_password = db_password
self.db_host = db_host
self.db_port = db_port
self.conn = self.connect_db()
print("connection successfully to MySQL")
# 连接数据库
def connect_db(self):
conn = MySQLdb.connect(host=self.db_host, user=self.db_username, passwd=self.db_password,
database=self.database, charset="utf8")
return conn
# 关闭数据库
def connect_close(self):
self.conn.close()
# 插入一条数据
def insert_one(self, data, keyword):
cursor = self.conn.cursor()
# 将数据字典里的keys用逗号分开成为一个新的字符串 作为插入数据库的字段名
keys = ','.join(data.keys())
# 将数据字典里的values配置成一个符合数据库插入数据的一个新的字符串 如:'a','b'............
value_str = '\',\''.join(data.values())
values = '\'' + value_str + '\''
db_sql = f"INSERT INTO {keyword} ({keys}) VALUES ({values})"
# 执行sql语句并提交事务,如遇错误,则事务回滚 避免数据产生问题
try:
cursor.execute(db_sql)
# 提交到数据库执行
self.conn.commit()
except Exception as error:
# 发生错误时回滚
self.conn.rollback()
return error
# 根据keyword 也就是表名查询一条语句
def find_one(self, keyword, data_id):
cursor = self.conn.cursor()
db_sql = "SELECT * FROM {0} WHERE JobId = {1};".format(keyword, data_id)
cursor.execute(db_sql)
library = cursor.fetchall()
cursor.close()
return library
# 根据keyword 也就是表名查询该表下所有数据
def find_all(self, keyword):
cursor = self.conn.cursor(cursorclass=MySQLdb.cursors.DictCursor)
db_sql = "SELECT * FROM {0};".format(keyword)
cursor.execute(db_sql)
libraries = cursor.fetchall()
cursor.close()
return libraries
# 测试数据
# if __name__ == '__main__':
# mysql_db = MySQLHelper(database='pythonworkdb')
# data = dict({'jobId': '733354', 'jobUrl': 'https://www.lagou.com/jobs/7319354.html?
# show=e7f08420b611400a9104c5557b890291', 'jobName': 'java开发工程师', 'salary': '15k-25k', 'experience': '经验3-5年'
# , 'education': '本科及以上', 'jobType': '全职', 'city': '深圳 ', 'address':
# '深圳-宝安区-新安-留芳路6号庭威产业园1号楼202', 'advantage': '员工旅游,五险一金,发展空间大',
# 'requirement': '工作职责:\n1.负责公司后台关键业务的微服务开发和微服务基础架构的开发;\n2.指导新员工完成开发任务能力要求。
# \n\n岗位要求:\n1.本科及以上学历,2-5年工作经验\n2.熟练掌握java se的大部分类库\n3.精通面向对象编程,
# 熟练掌握8种以上的设计模式,# 熟悉这些设计模式的优缺点和应用场景,
# 能够熟练使用设计模式构建高质量、可维护性、可扩展性好的代码\n4.熟练使用java8 stream\n5
# .熟练掌握java的多线程和并发编程技术\n6. 熟悉jvm内核机制\n7.熟悉Spring的Ioc和AOP特性,
# 了解Spring源码者优先\n8.熟悉微服务架构的优缺点,熟悉RESTful API设计风格,有过微服务开发经验者优先\n9.
# 有强大的抗压能力和自我驱动力,能够独立分析解决问题,热衷于提升效率,追求个人技术成长', 'company_name'
# : '深圳尚米网络技术有限公司', 'company_nickname': '尚米网络', 'company_field': '移动互联网,电商',
# 'company_investment': '', 'company_scale': '不需要融资', 'company_size': '150-500人', 'company_link':
# 'http://www.shangminet.com/', 'source': 'lagou'})
# #data = list(a.values())
# mysql_db.insert_one(data=data, keyword='python')
3.4 visualize_data.py
3.4.1 read_data_to_frame
def read_data_to_frame(self, keyword, save_method):
"""获取数据并转传成 DataFrame"""
if save_method == 'file':
for key in keyword:
if key:
base_dir = os.path.dirname(__file__)
data_files = [os.path.join(base_dir, 'lagou_data', f'{key}.csv')]
else:
data_files = glob.glob(os.path.join('lagou_data', '*.csv'))
for data_file in data_files:
with open(data_file, 'r', encoding='utf-8') as f:
reader = csv.DictReader(f)
for row in reader:
self.data.append(dict(row))
# 如果存储数据方式是mysql数据库,则运行该段代码
if save_method == 'mysql_db':
mysql_db = MySQLHelper(database='pythonworkdb')
# 将所有数据取出
for key in keyword:
data = mysql_db.find_all(key)
# 将数据一条一条取出并存为字典
for row in data:
data_dict = dict(row)
# 将字典里的id 即数据库自增id去除,以备后面可视化数据
del data_dict['id']
# 将数据添加到data中
self.data.append(data_dict)
self.frame = DataFrame(self.data)
3.5 spiders.py
3.5.1 main
if __name__ == '__main__':
try:
configure_file = sys.argv[1]
except:
configure_file = 'configures/configure.yml'
configures = yaml_configure_parser(configure_file)
mongo_db_configures = configures.get('mongo_db', {})
mysql_db_configures = configures.get('mysql_db', {})
webdriver_option_configures = configures.get('webdriver_option', {})
lagou_configures = configures.get('lagou', {})
if mongo_db_configures.get('host', ''):
mongo_db = MonGoDBHelper(database='jobs', **mongo_db_configures)
else:
mongo_db = None
#构造一个mysql类对象
if mysql_db_configures.get('db_host', ''):
mysql_db = MySQLHelper(database='pythonworkdb')
else:
mysql_db = None
lagou_spider = LaGouSpider(proxy_server=webdriver_option_configures['proxy_server'],
headless=webdriver_option_configures['headless'],
executable_path=webdriver_option_configures['executable_path'],
sleep_interval=lagou_configures['sleep_interval'],
save_method=lagou_configures['save_method'],
save_file_path=lagou_configures['save_file_path'],
mysql_db=mysql_db,
)
lagou_spider.run(username=lagou_configures['username'], password=lagou_configures['password'],
keyword=lagou_configures['keyword'])
3.5.2 run
def run(self, username, password, keyword=[]):
"""运行入口"""
self.login(username, password)
# common_cities, all_cities = self.get_cities()
# if not common_cities: common_cities = COMMON_CITIES
# if not all_cities: all_cities = ALL_CITIES
common_cities = COMMON_CITIES
all_cities = ALL_CITIES
logger.info(f'获取常用城市:{common_cities}')
logger.info(f'获取全部城市:{all_cities}')
time.sleep(self.sleep_interval)
# 根据配置文件中的岗位名称进行遍历爬取数据
for key in keyword:
if key:
categories = [key]
logger.info(f'获取key:{keyword}')
logger.info(f'获取key:{key}')
else:
# categories = self.get_categories()
# if not categories: categories = CATEGORIES
categories = CATEGORIES
logger.info(f'获取全部搜索分类:{categories}')
for category in categories:
for common_city in common_cities:
districts = self.get_districts(common_city)
logger.info(f'获取城市:{common_city}的行政区域:{districts}')
# 当触发爬虫验证机制, 需要关闭浏览器重新开始, 正常则继续下一个
while True:
running = self.main(keyword=category, city=common_city)
if running:
break
else:
continue
for district in districts:
while True:
running = self.main(keyword=category, city=common_city, district=district)
if running:
break
else:
continue
self.mysql_db.connect_close()
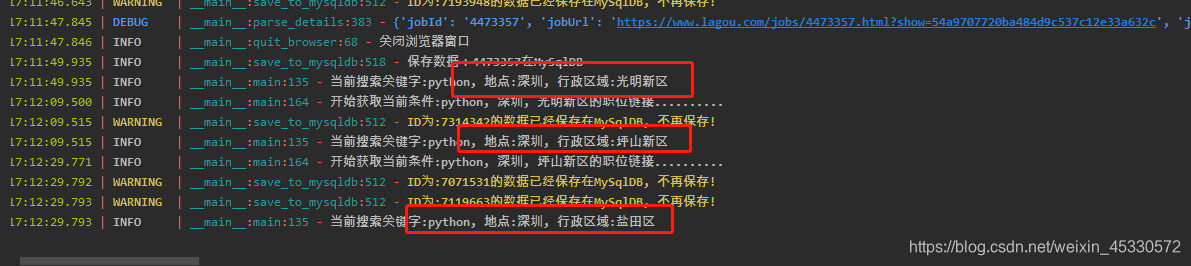
3.5.3 save_to_mysqldb
# 查询数据是否已经被保存,如已保存,不保存该数据 否则保存数据到
数据库中
def save_to_mysqldb(self, keyword, data_id, url):
saved_data = self.mysql_db.find_one(keyword=keyword, data_id=data_id)
if saved_data:
logger.warning(f'ID为:{data_id}的数据已经保存在MySqlDB, 不再保存!')
else:
data = self.parse_details(url)
error = self.mysql_db.insert_one(data, keyword)
if error is not None:
logger.error(error)
logger.info(f'保存数据:{data_id}在MySqlDB')
4.实验结果

| 图2 即将开始爬取数据 |
|---|
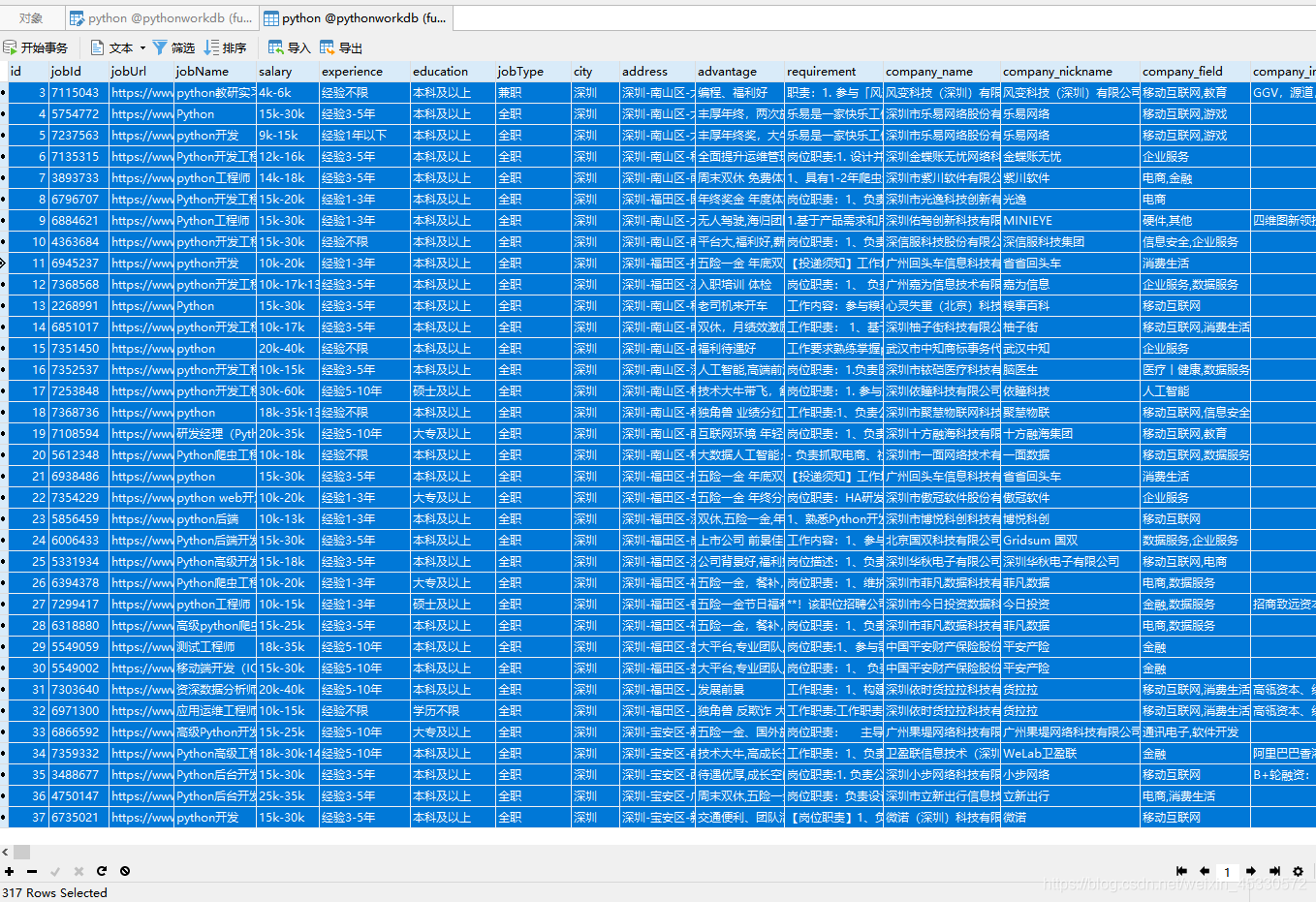
| 图3数据库数据317条 |
|---|

| 图4开始爬取数据并保存数据 |
|---|
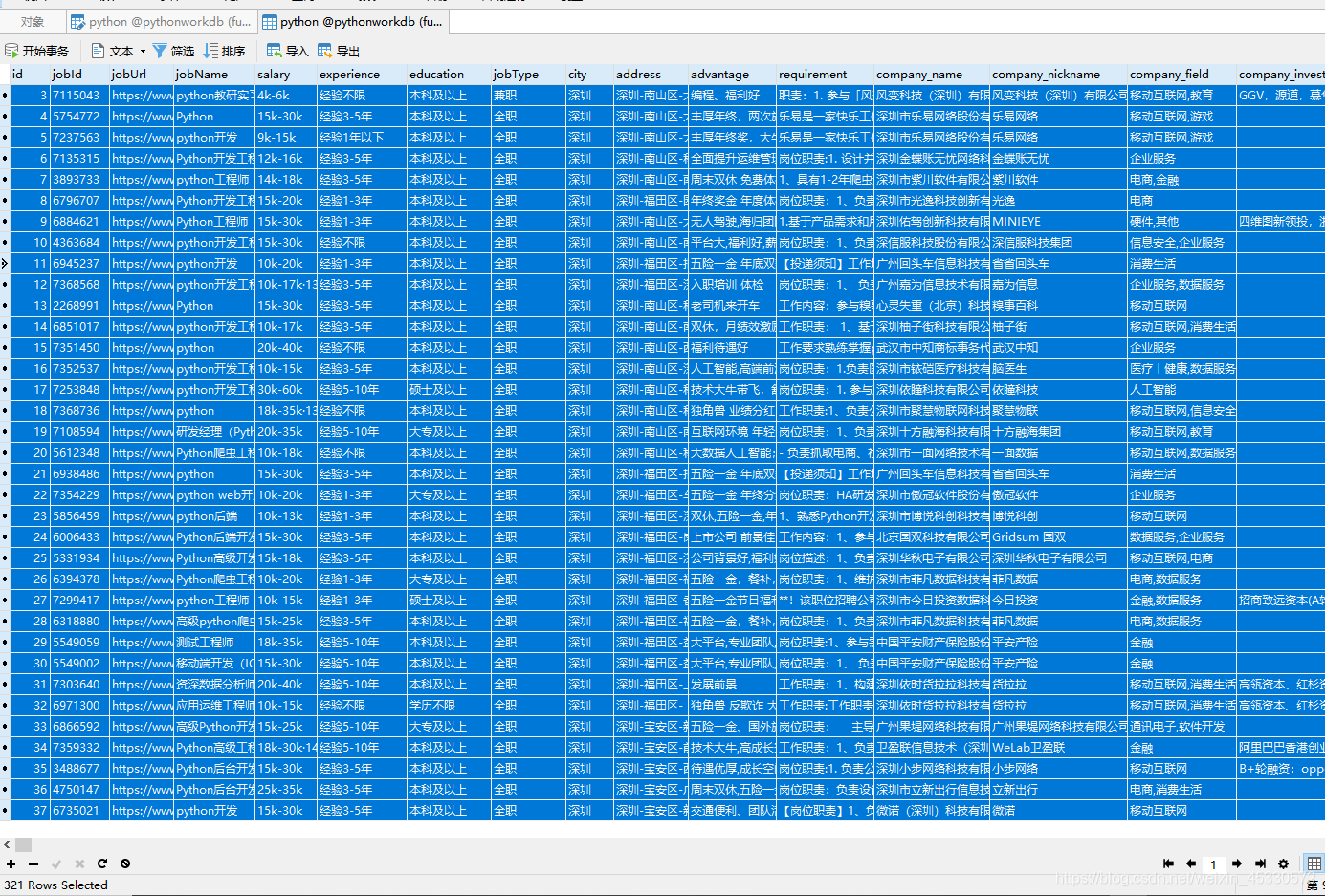
| 图5数据库数据321条 |
|---|
 |
| 图6根据不同地区爬取数据 |
| – |
 |
| 图7爬取不同城市的数据 |
| – |
 |
| 图8爬取另一个关键字(岗位)数据 |
| – |
 |
| 图9 程序正常结束,数据爬取完成 |
| – |

| 图10 数据可视化(实验报告每次只爬取一页数据,所以数据比较少) |
|---|
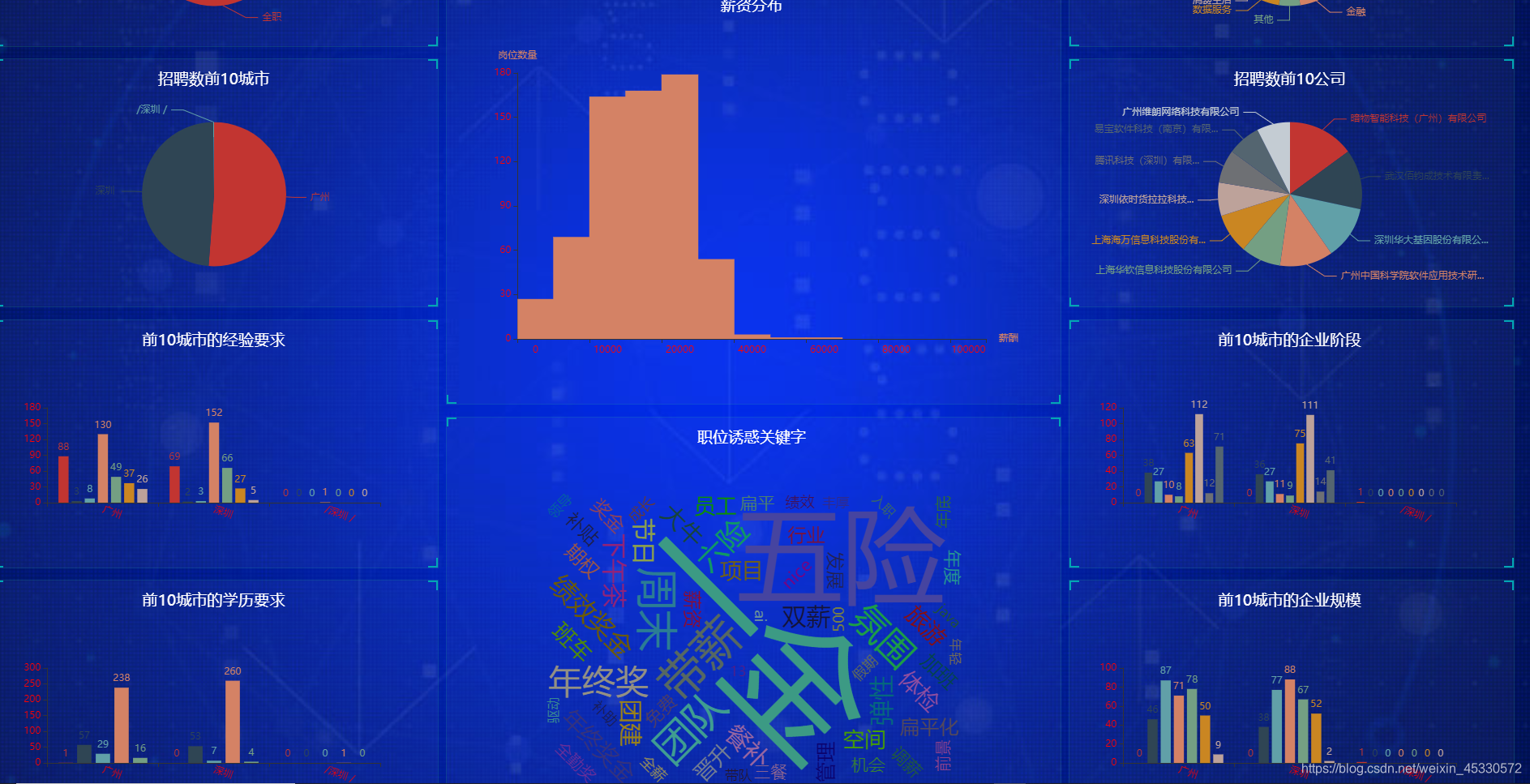 |
| 图11数据可视化2 |
|---|
 |
| 图12数据可视化3 |
| – |
5.总结与展望
通过这次实验,可以说把整个学期的课程知识都串联在了一起又重温了一遍,本次实验项目由于原作者是在Linux操作系统下完成的,所以本人在Windows操作系统中遇到了不少问题,其中最多的就是编码问题,其他问题还行,所幸所有问题都已经解决完毕。在本次实验的过程中,也学习到了很多新的知识,比如获取了数据库之后如何将数据转换成字典,再供数据解析方法使用、在项目拉取下来之后应把依赖库独立放到一个文件夹中以免“污染”原依赖库等等。
本次实验不足之处也有许多,比如:没有完成大量IP代理池进行爬取信息的功能,请大家见谅。
希望以后能自己编写一个完整的python爬虫项目并用本人最熟悉的java语言进行再次编写。
6.参考文献
[1].百度百科
Github项目链接:https://github.com/ScarecrowFu/crawllagou















 4257
4257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









