






1.通用的解决方案:
【按住Ctrl键不送松】,同时用鼠标点击【方法名】,查看文档
2.TypeError: POST data should be bytes, an iterable of bytes, or a file object. It cannot be of type str.
问题描述:【类型错误】就是数据的类型应该是bytes类型,而不是str类型
解决方案:
data = data.encode('utf-8')
3.爬取得到的HTML在一行显示
调试步骤:通过print(type(html))查看html的类型, 可以查出是bytes类型,就需要解码
解决方案:
html = html.decode()
4.有时候使用爬虫会被网站封了IP,所以需要去模拟浏览器
解决方案:
header = {"User-Agent": "mozilla/4.0 (compatible; MSIE 5.5; Windows NT)"}
req = request.Request(url=base_url,data=bytes(data,encoding='utf-8'),headers=header)
5.当服务器返回json格式的数据乱码
调试步骤:
1.通过print(type(json_data))查看数据的类型,
2.可以查出是str类型,就是说返回的字符串中有bytes类型的数据
解决方案:把json字符串转换为字典
json_data = json.loads(json_data)
6.怎么只输出json数据的value或者某个key对应的value,不要[{}]
问题描述: 想要jsonkey/value的一部分
典型案例:
例如:
json_data=
{'errno': 0,
'data': [{'k': 'good',
'v': 'adj. 好的;'
},
{'k': 'good morning',
'v': 'int. 早安;'
}
]
}
要求: 只想要输出good: adj. 好的,而不要其他的格式
1.可以通过json_data['data'],只输出json数据json_data中‘data’对应的值,也就是
[{'k': 'good',
'v': 'adj. 好的;'
},
{'k': 'good morning',
'v': 'int. 早安;'
}
]
2.遍历输出每个'k'和'v'的值
# 遍历输出每个'k'和'v'的值
for item in json_data['data']:
print(item['k'], ": ", item['v'])
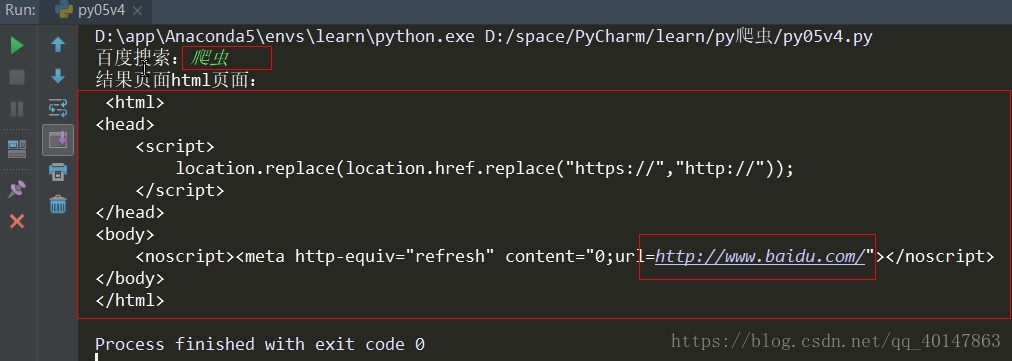
7.返回的页面是一个链接,而不是链接的页面
问题描述: 百度搜索,我们输入搜索内容,返回的是一个包括原地址链接的html,而不是访问该链接 的html,且返回的html中:location.replace(location.href.replace("https://","http://"));
问题实例截图:
解决方案: 如果使用的是http改成https,
如果使用的是https改成http,就可以了















 720
720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









