







基于kafka表引擎
实现步骤
- 创建引擎表
- 创建本地表
- 创建物化视图(作用是基于引擎表建立向本地表的映射)
创建引擎表
CREATE TABLE kafka_engine_table (`name` String, `age` UInt64 ) ENGINE = Kafka () SETTINGS kafka_broker_list = '192.168.5.135:13502',
kafka_topic_list = 'clickhouse',
kafka_group_name = 'clickhouse',
kafka_format = 'JSONEachRow',
kafka_skip_broken_messages = 1;

-
参数说明
- kafka_broker_list:Kafka服务的broker列表,用逗号分隔
- kafka_topic_list:Kafka topic,多个topic用逗号分隔
- kafka_group_name:消费者group名称
- kafka_format:CSV / JSONEachRow / AvroConfluent
- 可选参数:
- kafka_skip_broken_messages:填写大于等于0的整数,表示忽略解析异常的Kafka数据的条数。如果出现了N条异常后,后台线程结束,Materialized View会被重新安排后台线程去监听数据(默认值:0)
- kafka_num_consumers:单个Kafka Engine 的消费者数量,通过增加该参数,可以提高消费数据吞吐,但总数不应超过对应topic的partitions总数
- kafka_row_delimiter:消息分隔符
- kafka_schema:对于kafka_format需要schema定义的时候,其schema由该参数确定
- kafka_max_block_size:该参数控制Kafka数据写入目标表的Block大小,超过该数值后,就将数据刷盘
- kafka_commit_every_batch:批量提交时的每批次大小(默认值:0)
- kafka_thread_per_consumer:kafka_thread_per_consumer:为每个消费者提供独立的线程(默认值:0)。启用后,每个使用者将并行并行地刷新数据;否则,来自多个使用者的行将被压缩以形成一个块
-
重点说明:
kafka_skip_broken_messages很重要,如果此参数不设置或者设置为0的话会导致数据无法被监听。
创建本地表
# 这里是基于mergeTree引擎创建的,当然也可以指定其他参数,比如分区等信息
CREATE TABLE kafka_table (`name` String, `age` UInt64) ENGINE = MergeTree() ORDER BY age;

创建物化视图
CREATE MATERIALIZED VIEW kafka_view TO kafka_table AS select * from kafka_engine_table;
# 语法:CREATE MATERIALIZED VIEW 物化视图名称 TO 目标表 AS 基于引擎表的SQL语句

演示
- 向kafka中为
clickhouse的topic发送测试数据

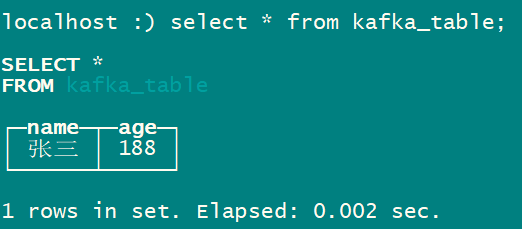
- 查询本地表中的数据















 1069
1069











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











