






1 前置知识 :Pyhton的类与继承
1.1 类
class Student:
#变量
name = None
age = None
gender = None
__current_voltage = None
#方法
def printitem(self):
print(__current_voltage )
self.__makelow()
def __init__(self,name,age,gender):
self.name=name
self.age=age
self.gender=gender
def __makelow(self): #私有成员方法
print(self.name)
1.1.1 成员变量与成员方法
类内的成员变量可以自己定义,也可以继承来自于父类的成员变量。在方法中使用成员函数时,需要传入self,即成员方法的第一个形参一定是self,在方法内访问成员变量要使用self.变量
私有成员变量和私有成员方法都是在其前加上__。这样一来,这些变量和方法不能被类的对象使用,只能被其他的成员方法调用,如上方代码段中的 printitem函数所示。
1.1.2 特殊的成员方法 __init__( )
构造函数,在创建对象时默认调用。如上述代码的类中,在创建对象时输入
stu_1 = Student("kuanHao",20,"man")
将会自动调用构造函数,将这三个参数分别赋予给对象的三个成员变量。
1.2 继承
以线性模型的模型代码为例:
class LinearModel(torch.nn.Module):
def _init_(self):
super(LinearModel,self)._init_()
self.linear = torch.nn.Linear(1,1)
def forward(self,x):
y_pred = self.linear(x)
return y_pred
model = LinearModel()创建LinearModel类继承于torch.nn.Module类,继承后子类的对象可以调用父类中的方法和变量。
1.2.1 super函数
Python中类的初始化都是__init__(), 所以父类和子类的初始化方式都是__init__(), 但是如果子类初始化时没有这个函数,那么他将直接调用父类的__init__(); 如果子类指定了__init__(), 就会覆盖父类的初始化函数__init__(),如果想在进行子类的初始化的同时也继承父类的__init__(), 就需要在子类中显示地通过super()来调用父类的__init__()函数。即如上述代码所示,在对__init__()方法重写时,先来一句super.__init__(),即先调用一次父类的初始化函数,后面再对自己新增的linear内容进行定义。
第二句,torch.nn.Linear()是pytorch内的一个类,即构造一个该类的对象self.linear,(1,1)是该模型输入和输出的维度都是1。
1.2.1 可调用 callable
类的成员方法 __call__(self,*args,**kwargs) 定义后可以使对象像函数一样可调用
先解释下参数的问题:
args表示在调用时,传入的参数(不带名字的)自动转换为一个元组,kwargs表示传入的带名字参数自动转换为一个字典。 实例如下: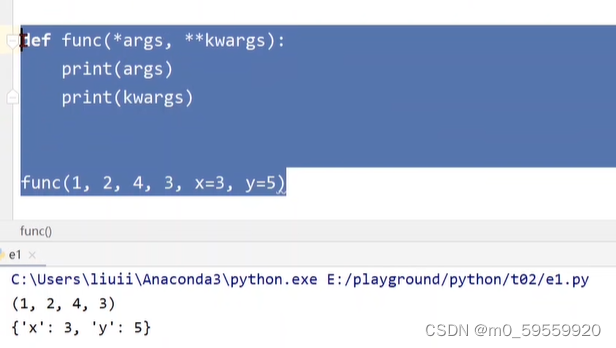
当一个类定义了__call__()方法后,便可以执行 对象() 这样的操作

而在torch.nn.module类中定义的call方法会使对象传入的值x进行一个 wx+b的操作
2.线性回归问题
2.1 prepare dataset
2.1.1 torchvision包
train_set = torchvision.datasets.MNIST(root='../dataset/mnist',train=Ture,download=True)
root:数据集的保存路径
train:若为True则为训练集,False则为测试集
download:是否已下载
2.2 Design model using class
2.3 Construct loss and optimizer(优化器)
损失函数
criterion = torch.nn.MSELoss(size_average=False) #不对cost取平均
criterion是建立的一个对象,她是callable的,因此在后续进行criterion(y_hite,y),即可求其cost
优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
model.parameters方法会检查model内需要被训练的参数
lr为学习率
2.4 Training cycle
3.分类问题
根据输入的数据,判断输出为每一类型的概率,属于某类型的概率最高则分为此类
3.2 logistic函数
针对二分类问题:

分类问题中模型的输出是输入数据属于某一类的概率,即输出的范围是[0,1]。因此引入Logistic函数(函数):
。
饱和函数:一旦x超过某一阈值,其导数将逐渐趋近于0,这类函数称为Sigmoid函数,上述的Logistic函数就是一类最典型的Sigmoid函数,常作为激活函数使用。

3.3 损失函数
二分类中使用的损失函数为BCE Loss(cross-entropy 交叉熵):
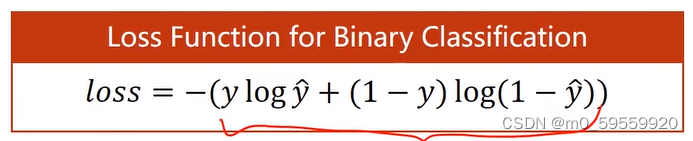















 760
760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









