










多输入模型 Multiple-Dimension 数学原理分析以及源码源码详解 深度学习 Pytorch笔记 B站刘二大人(6/10)
数学推导
在之前实现的模型普遍都是单输入单输出模型,显然,在现实场景中更多的是多输入多输入模型。在本文中将主要推导,多输入模型中的内部数据传输变化,以及内部矩阵运算过程
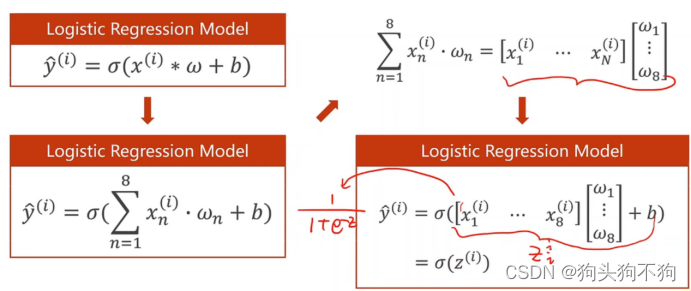
使用Mini-batch 模块,多个维度线性层共同使用一组权重w的线性组合,共享权重可以极大减小运算量。转化为矩阵运算的意义是希望通过转化为矩阵实现并行运算,进行gpu的挂载
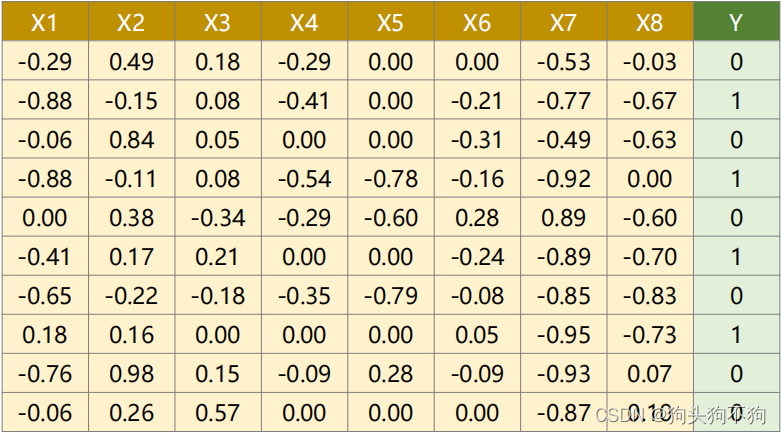
在本次的实践数据中使用的是糖尿病病人的数据集,通过维度为8的输入数据,即利用8种病人自身的评价指标的数据,对该样本病人是否患有糖尿病进行判断。
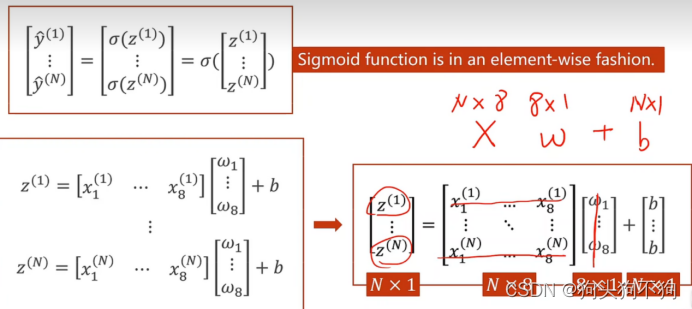
假设输入训练数据量为N,则输入数据为一个8*N的矩阵,如上图所示。
在之前的文章中已经进行了强调,要将数据运算的过程视为矩阵的运算,因此需要维度为8的权重向量w与原始数据进行矩阵乘法,N8的矩阵与81的矩阵右乘,则得到N*1的矩阵,加上偏置量b,通过激活函数sigmoid转化为概率,通过概率进行判别。
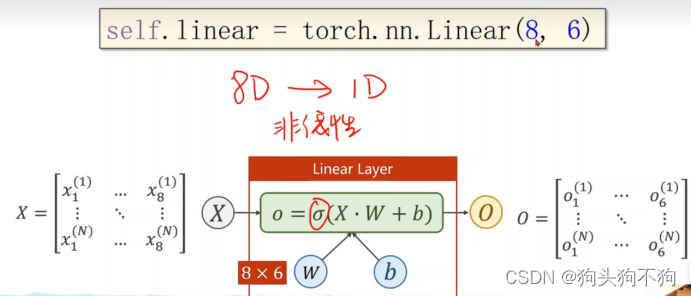
虽然在原理上,是直接通过8*1的权重矩阵w进行构造,但是实际构造为了提高准确性,通常会将单个线性层拆分为多层,例如在本文的代码实现中就将 8 -> 1 层的网络结构转换为 8 -> 6 -> 4 -> 1 的多层网络结构。

将8维空间的数据转化为1维,通过多个线性层与激活函数的组合,模拟多个空间非线性变换,从而达到不同的设计目的。一般隐层越多,学习能力越强,但是必须考虑泛化能力
数据下载
链接:https://pan.baidu.com/s/1IJpTM1_gd4Tln01A5JYOSA?pwd=ws2r
提取码:ws2r
代码解读与实现
代码细节,loadtxt函数dtype选择 .float32类型 ,原因:绝大部分的显卡仅支持float32位的数据
其次本次代码在进行损失计算中,选用的是average = True,意味着将损失将取平均值,损失值和梯度将较大,优化器的迭代步长可以适当调大
''' coding:utf-8 '''
"""
作者:shiyi
日期:年 09月 03日
通过pytorch模块复现多输入线性模型
"""
# prepare dataset
import torch
import numpy as np
xy = np.loadtxt('D:\\pytorch_prac\\dataset\\diabetes.csv.gz', delimiter=',', dtype=np.float32) # 使用float32位的数据,以支持绝大部分GPU的数据格式
x_data = torch.from_numpy(xy[:, :-1]) # 读取输入数据,xy[:,:-1] 意思是读取 除了最后1列 的其余所有行数据
y_data = torch.from_numpy(xy[:, [-1]]) # 读取标签数据,xy[:,[-1]]意思是读取 最后1列 所有行的数据
# design model using class
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x)) # 注意全部都用x,防止传输出错
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model() # 实例化
# Construct loss and optimizer
cirterison = torch.nn.BCELoss(size_average=True)
opimizer = torch.optim.ASGD(model.parameters(), lr=0.05)
# Training cycle
for epoch in range(3000):
# Forward
y_pred = model(x_data)
loss = cirterison(y_pred, y_data)
print(epoch, loss.item())
# Bcakward
opimizer.zero_grad()
loss.backward()
# Update
opimizer.step()
# Test Model
x_test = torch.Tensor([[4.0, 5.0, 3.0, 4.0, 1.0, 6.0, 7.0, 8.0]])
y_test = model(x_test)
print('y_pred =', y_test.item())
与其余的模型不同的是,本次的多输入模型训练的损失始终难以下降到一个令人满意的程度,这与损失构造算法和优化器类型都存在关系,可以尝试更换通过matplotlib库画出图形进行比对和优化
优化代码与结果
(更新中,我真是擅长给自己挖坑呢。。。。)















 1985
1985











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











