







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
实验相关内容
1.数据分析实验
#非均衡数据的处理
提示:以下是本篇文章正文内容,下面案例可供参考
2.数据集介绍
数据集包括了 2013 年 9 月份两天时间内的信用卡交易数据,284807 笔交易中,一共有 492 笔是欺诈行为。输入数据一共包括了 28 个特征 V1,V2,……V28 对应的取值,以及交易时间 Time 和交易金额 Amount。为了保护数据隐私,我们不知道 V1 到 V28 这些特征代表的具体含义,只知道这 28 个特征值是通过 PCA 变换得到的结果。另外字段 Class 代表该笔交易的分类,Class=0 为正常(非欺诈),Class=1 代表欺诈
3.实验目标
目标是针对这个数据集构建一个信用卡欺诈分析的分类器,采用的是逻辑回归。
4.整个流程

- 了解逻辑回归分类,以及如何在 sklearn 中使用它;
- 信用卡欺诈属于二分类问题,欺诈交易在所有交易中的比例很小,对于这种数据不平衡的情况,到底采用什么样的模型评估标准会更准确;
- 完成信用卡欺诈分析的实战项目,并通过数据可视化对数据探索和模型结果评估进一步加强了解。
实验前讲解
- 如何使用 sklearn 中的逻辑回归工具:
- 在 sklearn 中,使用 LogisticRegression() 函数构建逻辑回归分类器,函数里有一些常用的构造参数:
-
penalty:惩罚项,取值为 l1 或 l2,默认为 l2。当模型参数满足高斯分布的时候,使用
l2,当模型参数满足拉普拉斯分布的时候,使用 l1; -
solver:代表的是逻辑回归损失函数的优化方法。有 5 个参数可选,分别为
liblinear、lbfgs、newton-cg、sag 和 saga。默认为
liblinear,适用于数据量小的数据集,当数据量大的时候可以选用 sag 或 saga 方法; -
max_iter:算法收敛的最大迭代次数,默认为 10; n_jobs:拟合和预测的时候 CPU 的核数,默认是1,也可以是整数,如果是-1 则代表 CPU 的核数。当我们创建好之后,就可以使用 fit 函数拟合,使用 predict 函数预测。*
- 模型评估指标
这里先介绍下数据预测的四种情况:TP、FP、TN、FN。*

- 准确率 Accuracy = (TP+TN)/(TP+TN+FN+FP);
- 精确率 P = TP/ (TP+FP); 召回率 R = TP/ (TP+FN),也称为查全率。
- F1 作为精确率 P 和召回率 R 的调和平均,数值越大代表模型的结果越好。
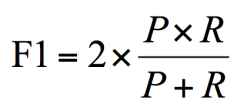
*
使用步骤
代码如下(示例):
```python
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import itertools
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, precision_recall_curve
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
import warnings
warnings.filterwarnings('ignore')
# 混淆矩阵可视化
def plot_confusion_matrix(cm, classes, normalize = False, title = 'Confusion matrix"', cmap = plt.cm.Blues) :
plt.figure()
plt.imshow(cm, interpolation = 'nearest', cmap = cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation = 0)
plt.yticks(tick_marks, classes)
thresh = cm.max() / 2.
for i 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1470
1470











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









