







Visual-Language Pretraining(VLP)是多模态领域的核心研究点之一,也是目前的一个热点研究方向。学术界提出了五花八门的VLP模型结构、训练方法方法。这些VLP方法哪种效果最好呢?微软近期发表的一篇论文_An Empirical Study of Training End-to-End Vision and Language Transformers(2022)_进行了大量的实验,对不同VLP模型、各个模块不同配置的效果。
本文以这篇论文为基础,详细介绍VLP的各个组成部分,以及各个部分的不同配置对效果的影响。
1 VLP中的五大模块
学术界关于Visual-Language模型的论文有几十上百篇,但是它们大多数都遵循同一个框架,包含五大模块,分别为Vision Encoder、Text Encoder、Multimodal Fusion、是否包含Decoder以及预训练任务(如下图)。不同的VLP论文主要对这5个模块进行不同的设计。
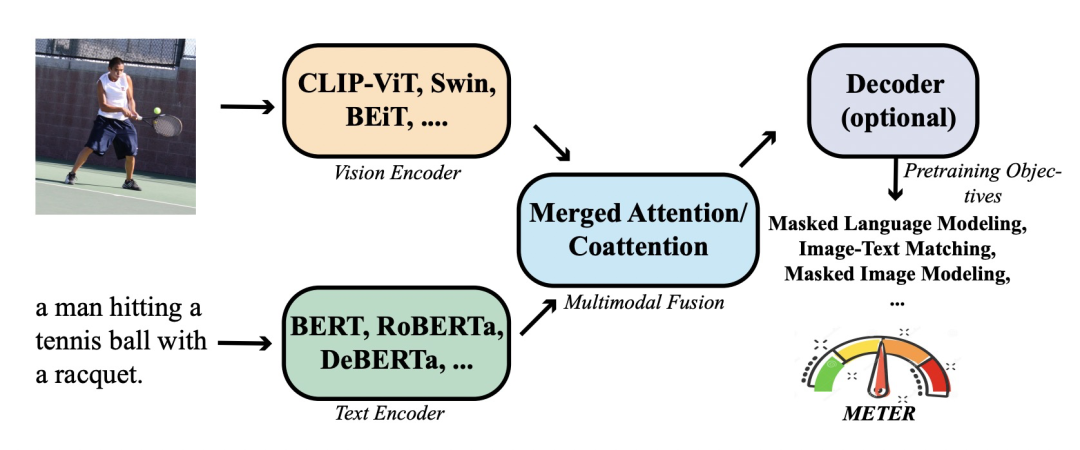
下面,我们回顾一下历史的VLP工作,看看各个模块都有哪些设计方式。
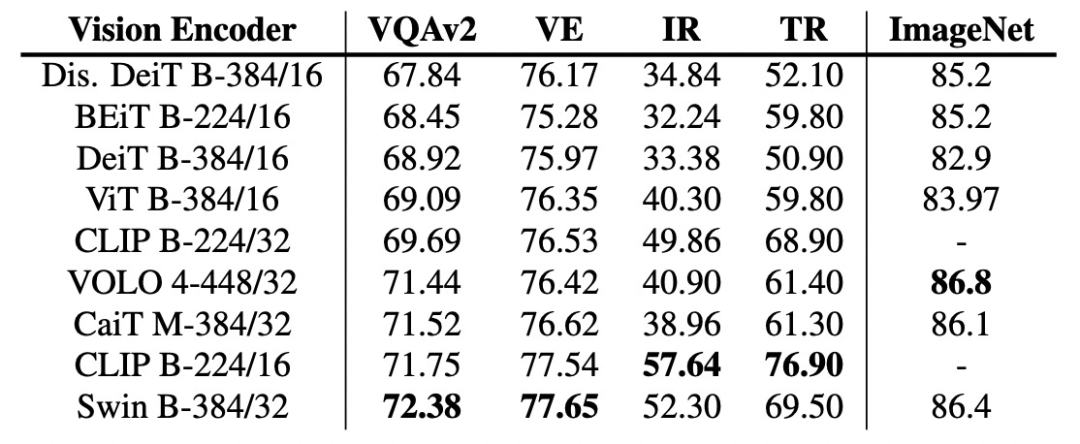
- Visual Encoder:Visual Encoder主要包括3种类型。第一种类型为使用object detection模型(一般为Faster R-CNN)识别图像中的目标区域,并生成每个目标区域的特征表示,输入到后续模型中。例如下图是_Unicoder-VL: A Universal Encoder for Vision and Language by Cross-modal Pre-training(AAAI 2020)_中的一个例子,对图中的各个目标region识别后生成表示,融入到主模型Bert中。第二种方式是利用CNN模型提取grid feature作为图像侧输入。第三种方式是ViT采用的将图像分解成patch,每个patch生成embedding输入到模型中。随着Vision-Transformer的发展,第三种方式逐渐成为主流方法。本文主要研究的Visual Encoder是第三种,相比前两种方式运行效率更高,不需要依赖object detection模块或前置的CNN特征提取模块。
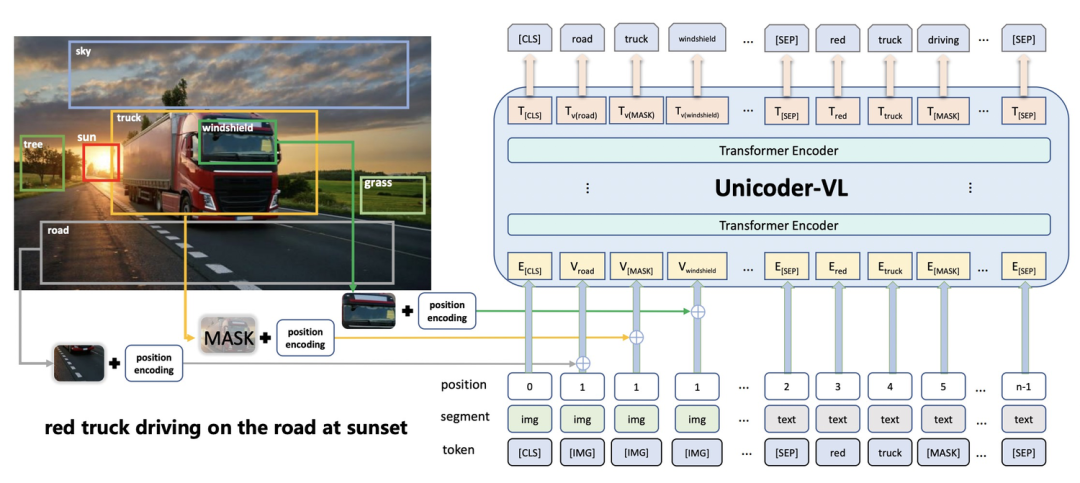
-
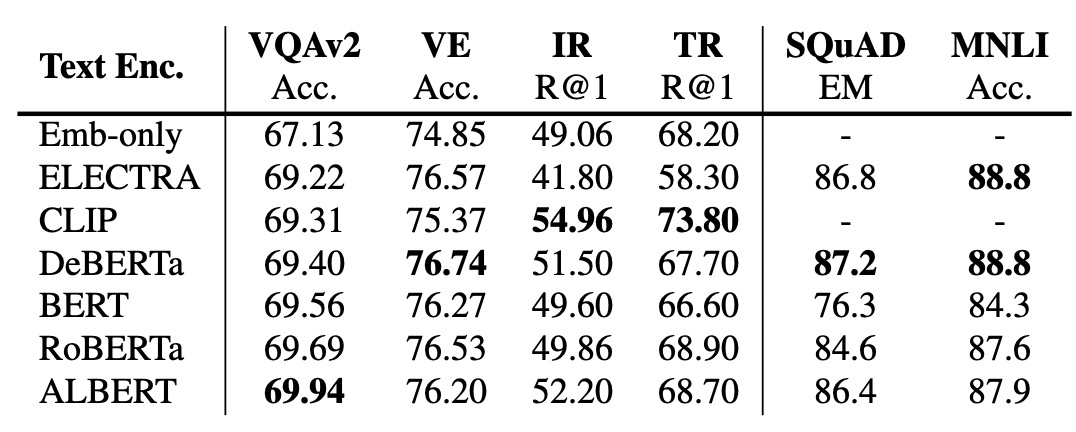
Text Encoder:包括诸如BERT、RoBERTa、ELECTRA、ALBERT、DeBERTa等经典预训练语言模型结构。
-
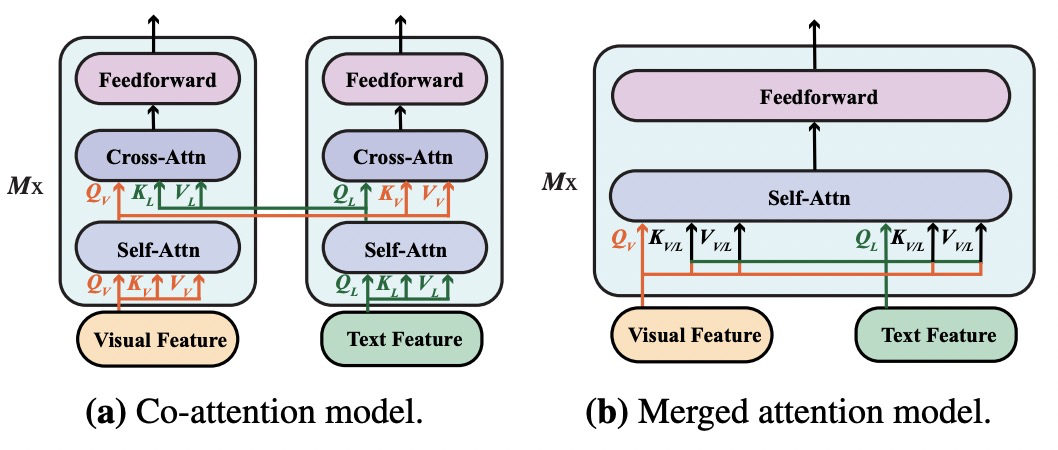
Multimodel Fusion:主要指的是如何融合图像侧和文本侧Encoder输出的表示。主流方法包括2种。一种被称为co-attention,图像侧和文本侧分别使用Transformer编码,在每个Transformer模块中间加入图像和文本之间的cross attention。另一种方式被称为merged attention model,图像侧和文本侧的信息在最开始就被拼接到一起,输入到Transformer模型中。其中,merged attention model方法的参数量相对更少。两种Multimodel Fusion方法如下图。
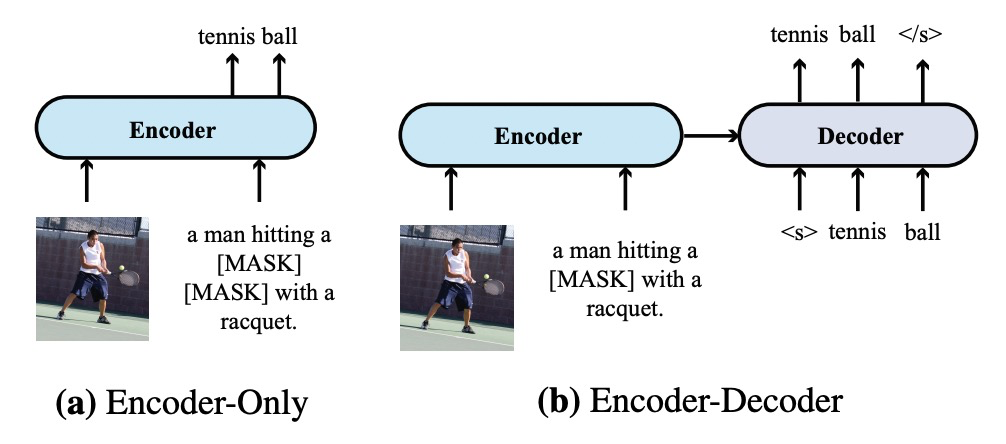
- 模型结构:模型结构方面主要包括Encoder-only和Encoder-Decoder两种类型。一般比较常见的是Encoder-only结构。对于Encoder-Decoder结构,将Encoder得到的多模态表示输入到Decoder中,递归解析出后续单词。两种模型结构如下图。
- Pretraining Objectives:历史工作提出了很多预训练阶段的目标任务,主要可以分为3大类。第一类是Masked Language Modeling(MLM),随机遮盖掉部分token,使用其他的token以及图像信息预测被遮盖住的token,类似于Bert中的MLM。第二类是Masked Image Modeling,对输入的部分图像region或patch进行mask,然后预测被mask掉部分的目标类别,或者基于回归任务还原被mask掉部分的像素。第三类是Image-Text Matching(ITM)任务,预测image和text的pair对是否匹配,对比学习的预训练方法也可以放在这个类别中。此外,还有一些文中没有详细介绍的预训练任务,例如Word-Region Aligment、Visual Question Answering等。
下表汇总了一些SOTA VLP模型这5个模块的配置。

2 哪种VLP模型配置最好
文中进行了详细的对比实验,分析VLP模型5个模块采用不同配置的效果差异。最后,文中也列出了各种SOTA VLP模型的效果。本文验证VLP效果的主要任务是VQA任务,即给定一张图片和一个关于这个图片的文本问题,模型预测对应的文本答案,数据集为VQAv2。下面我们分别介绍文中的各个实验。
实验1**:探索不同Text/Image Encoder对效果的影响**。不进行VLP预训练对比不同Text Encoder、Vision Encoder效果。使用文本、图像单模态的模型各自的参数初始化对应Encoder,在Encoder输出基础上接多层随机初始化Transformer,然后直接在下游任务上Finetune,效果如下表。从表中数据可以看出,在不进行预训练的情况下,各个Text Encoder效果差距不大,RoBERTa效果最稳定;对于Vision Encoder来说,Swin Transformer取得了最好的效果。
文中提出两个训练技巧。首先,对于随机初始化的参数和使用预训练初始化的参数要使用不同的学习率,前者的学习率设置的大一些对效果有帮助。其次,finetune阶段增大图像分辨率会带来效果显著提升。
实验2:探索Multimodal Fusion模块对效果的影响**。实验结果表明,co-attention要比merged attention效果更好。这表明VLP任务中最好对于不同模态使用一套独立的参数。文中也提到,这个结论在region-based方法中并不适用。

实验3:Encoder-only和Encoder-Decoder对比**。从上表结果来看,Encoder-only模型的效果更好。但是Encoder-Decoder模型更灵活,可以解决image captioning等和文本生成有关的任务。
实验4:不同预训练任务的效果对比**。通过下面的任务可以看出,MLM任务和ITM任务都对模型效果有显著提升,其中MLM带来的提升更大。而MIM任务,即mask部分图像再预测,加入预训练后效果反而出现下降。

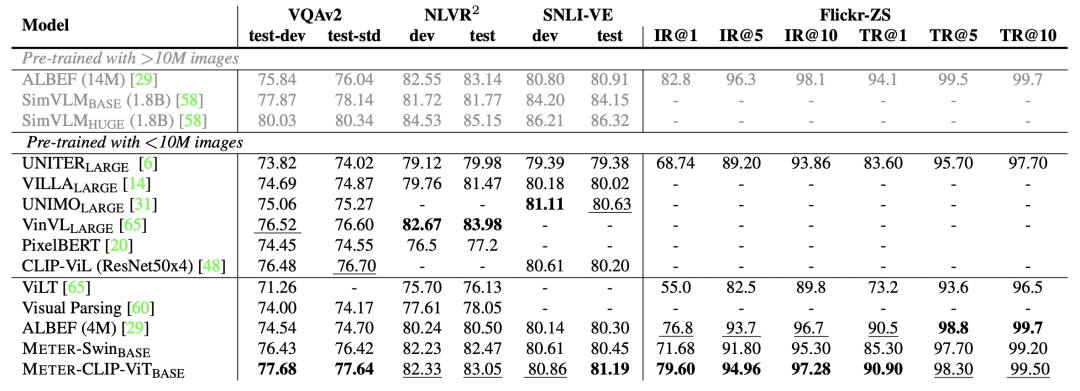
最后,文中也对比了各个SOTA方法的效果。文中采用最优配置进行模型训练,得到了VLP预训练框架METER,取得了非常显著的效果。
总结
这篇论文对VLP历史工作总结的比较全面(虽然有一些近期工作没有被纳入进来),并且通过大量实验验证了不同VLP模块配置对最终图文任务效果的影响,是一个多模态入门者比较好的参考资料。
技术交流
目前已开通了技术交流群,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式①、发送如下图片至微信,长按识别,后台回复:加群;
- 方式②、微信搜索公众号:机器学习社区,后台回复:加群;
- 方式③、可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。

研究方向包括:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+学校/公司+昵称(如Transformer或者目标检测+上交+卡卡),根据格式备注,可更快被通过且邀请进群。














 2694
2694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









