







节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学,针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
今天我介绍一位很励志的同学,分享给大家他面试算法岗的面试题,希望对后续找工作的有所帮助。喜欢记得点赞、收藏、关注。更多技术交流&面经学习,可以文末加入我们交流群。
我某985研二,目前已获得美团大厂实习 offer,本文章主要记录了研找实习的坎坷历程,希望对大家有帮助!!!
1. 自我介绍
在自我介绍环节,我清晰地阐述了个人基本信息、教育背景、工作经历和技能特长,展示了自信和沟通能力。
2. 技术问题
2.1 如何解决过拟合和欠拟合?
-
过拟合(Overfitting):
-
增加数据量:通过增加训练数据来减少模型对特定数据的过度拟合。
-
简化模型:减少模型的复杂度,可以通过减少特征数量、降低多项式次数等方式。
-
正则化:引入正则化项,如L1或L2正则化,以惩罚模型复杂度。
-
欠拟合(Underfitting):
-
增加特征:添加更多有意义的特征,提高模型的表达能力。
-
增加模型复杂度:选择更复杂的模型,如增加层数、节点数等。
-
减小正则化:减小正则化的程度,以允许模型更好地适应数据。
2.2 L1正则化和L2正则化的区别?
-
L1正则化:
-
增加的正则化项为权重向量的绝对值之和。
-
促使模型参数变得稀疏,即某些权重变为零,从而实现特征选择的效果。
-
L2正则化:
-
增加的正则化项为权重向量的平方和。
-
通过减小权重的同时保持它们都非零,对权重进行平滑调整。
-
区别:
-
L1正则化倾向于产生稀疏权重,对于特征选择有利;
-
L2正则化则更倾向于在所有特征上产生较小但非零的权重。
2.3 介绍一下 RAG?
检索增强 LLM ( Retrieval Augmented LLM ),简单来说,就是给 LLM 提供外部数据库,对于用户问题 ( Query ),通过一些信息检索 ( Information Retrieval, IR ) 的技术,先从外部数据库中检索出和用户问题相关的信息,然后让 LLM 结合这些相关信息来生成结果。
2.4 RAG 解决了哪些问题?
-
长尾知识: 对于一些相对通用和大众的知识,LLM 通常能生成比较准确的结果,而对于一些长尾知识,LLM 生成的回复通常并不可靠。
-
私有数据: ChatGPT 这类通用的 LLM 预训练阶段利用的大部分都是公开的数据,不包含私有数据,因此对于一些私有领域知识是欠缺的。
-
数据新鲜度: LLM 通过从预训练数据中学到的这部分信息就很容易过时。
-
来源验证和可解释性: 通常情况下,LLM 生成的输出不会给出其来源,比较难解释为什么会这么生成。而通过给 LLM 提供外部数据源,让其基于检索出的相关信息进行生成,就在生成的结果和信息来源之间建立了关联,因此生成的结果就可以追溯参考来源,可解释性和可控性就大大增强。
2.5 RAG 中包含哪些关键模块?
-
数据和索引模块
-
查询和检索模块
-
响应生成模块
2.6 RAG检索召回率低,一般都有哪些解决方案?
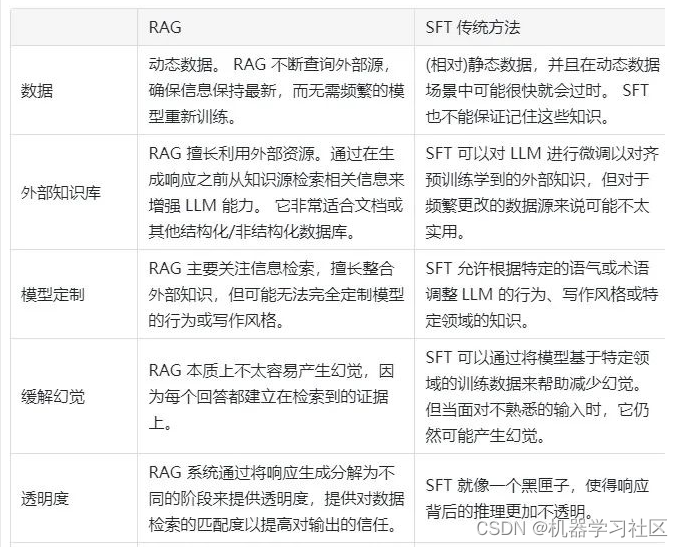
2.7 对比一下 RAG vs SFT ?
3. Leetcode 题
具体题意记不清了,但是类似 【5. 最长回文子串】
- 题目内容
给你一个字符串 s,找到 s 中最长的回文子串。
如果字符串的反序与原始字符串相同,则该字符串称为回文字符串。
示例 1:
输入:s = “babad” 输出:“bab” 解释:“aba” 同样是符合题意的答案。示例 2:
输入:s = “cbbd” 输出:“bb”
提示:
1 <= s.length <= 1000 s 仅由数字和英文字母组成
- 代码实现
class Solution:
def longestPalindrome(self, s: str) -> str:
if not s or len(s) < 1:
return ""
start = 0
end = 0
for i in range(0,len(s)):
len1 = self.expandAroundCenter(s,i,i)
len2 = self.expandAroundCenter(s,i,i+1)
s_len = len1 if len1>=len2 else len2
if s_len > end-start:
start = i - math.floor((s_len-1)/2)
end = i + math.floor(s_len/2)
return s[start:end+1]
def expandAroundCenter(self,s,left,right):
while left>=0 and right<len(s) and s[left] == s[right]:
left = left - 1
right = right + 1
return right - left - 1
技术交流
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了算法岗面试与技术交流群, 想要进交流群、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:技术交流
方式②、添加微信号:mlc2060,备注:技术交流+CSDN
用通俗易懂的方式讲解系列
- 用通俗易懂的方式讲解:不用再找了,这是大模型最全的面试题库
- 用通俗易懂的方式讲解:这是我见过的最适合大模型小白的 PyTorch 中文课程
- 用通俗易懂的方式讲解:一文讲透最热的大模型开发框架 LangChain
- 用通俗易懂的方式讲解:基于 LangChain + ChatGLM搭建知识本地库
- 用通俗易懂的方式讲解:基于大模型的知识问答系统全面总结
- 用通俗易懂的方式讲解:ChatGLM3 基础模型多轮对话微调
- 用通俗易懂的方式讲解:最火的大模型训练框架 DeepSpeed 详解来了
- 用通俗易懂的方式讲解:这应该是最全的大模型训练与微调关键技术梳理
- 用通俗易懂的方式讲解:Stable Diffusion 微调及推理优化实践指南
- 用通俗易懂的方式讲解:大模型训练过程概述
- 用通俗易懂的方式讲解:专补大模型短板的RAG
- 用通俗易懂的方式讲解:大模型LLM Agent在 Text2SQL 应用上的实践
- 用通俗易懂的方式讲解:大模型 LLM RAG在 Text2SQL 上的应用实践
- 用通俗易懂的方式讲解:大模型微调方法总结
- 用通俗易懂的方式讲解:涨知识了,这篇大模型 LangChain 框架与使用示例太棒了
- 用通俗易懂的方式讲解:掌握大模型这些优化技术,优雅地进行大模型的训练和推理!
- 用通俗易懂的方式讲解:九大最热门的开源大模型 Agent 框架来了
















 1447
1447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









