







1. 前言
在上篇文章中「LLM Agent在Text2SQL应用上的实践」介绍了基于AI Agent来优化LLM的Text2SQL转换效果的实践,除此之外我们还可以使用RAG(Retrieval-Augmented Generation)来优化大模型应用的效果。
本文将从以下4个方面探讨通过RAG来优化LLM的Text2SQL转换效果。
1. RAG概述
2. 基于LangChain的RAG实现
3. RAG优化Text2SQL应用的实践
4. 后续计划
Text2SQL 系列
技术交流
技术要学会分享、交流,不建议闭门造车。一个人走的很快、一堆人可以走的更远。
建立了大模型技术交流群,大模型学习资料、数据代码、技术交流提升, 均可加知识星球交流群获取,群友已超过2000人,添加时切记的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:技术交流
方式②、添加微信号:mlc2060,备注:技术交流

2. RAG概述
2.1 RAG概念
RAG(Retrieval-Augmented Generation)检索增强生成,即大模型LLM在回答问题或生成文本时,会先从大量的文档中检索出相关信息,然后基于这些检索出的信息进行回答或生成文本,从而可以提高回答的质量,而不是任由LLM来发挥。
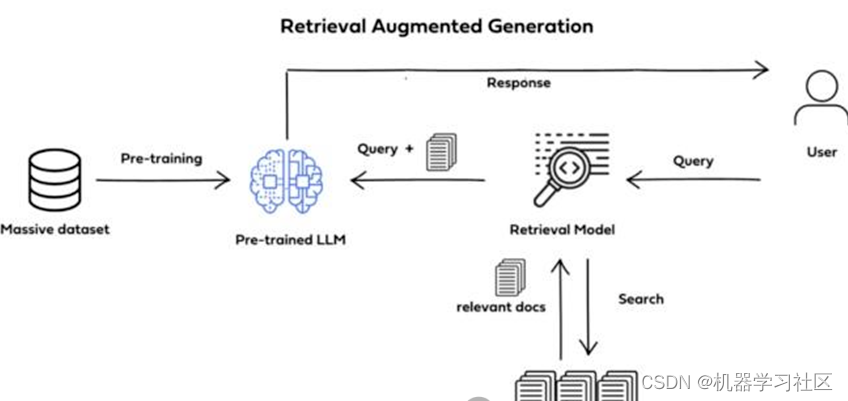
RAG技术使得开发者没有必要为每个特定的任务重新训练整个大模型,只需要外挂上相关知识库就可以,即可为模型提供额外的信息输入,提高回答的准确性。RAG技术工作流程如下图所示。
2.2 RAG能解决LLM的哪些问题
即使在LLM有较强的解决问题的能力,仍然需要RAG技术的配合,因为能够帮助解决LLM存在的以下几个问题。
(1)模型幻觉问题:LLM文本生成的底层原理是基于概率进行生成的,在没有已知事实作为支撑的情况下,不可避免的会出现一本正经的胡说八道的情况。而这种幻觉问题的区分是比较困难的,因为它要求使用者自身具备相应领域的知识。
(2)知识的局限性:模型自身的知识完全源于它的训练数据,而现有的主流大模型(ChatGPT、文心一言、通义千问…)的训练集基本都是构建于网络公开的数据,对于一些实时性的、非公开的或离线的数据是无法获取到的,这部分知识也就无从具备。
(3)数据安全问题:开源的大模型是没有企业内部数据和用户数据的,如果企业想在保证数据安全的前提下使用LLM,一种比较好的解决办法就是把数据放在本地,企业数据的业务计算全部放在本地完成。而在线的LLM只是完成一个归纳总结的作用。
2.3 RAG架构
简单来讲,RAG就是通过检索获取相关的知识并将其融入Prompt,让大模型能够参考相应的知识从而给出合理回答。
因此,可以将RAG的核心理解为“检索+生成”,前者主要是利用向量数据库的高效存储和检索能力,召回目标知识;后者则是利用大模型和Prompt工程,将召回的知识合理利用,生成目标答案。
完整的RAG应用流程主要包含两个阶段:
(1)数据准备阶段:数据提取–>文本分割–>向量化(embedding)–>数据入库;
(2)应用阶段:用户提问–>数据检索(检索)–>注入Prompt(增强)–>LLM生成答案(生成)。
下面我们详细介绍一下各环节的技术细节和注意事项:
2.3.1 数据准备阶段
数据准备一般是一个离线的过程,主要是将私域数据向量化后构建索引并存入数据库的过程。主要包括:数据提取、文本分割、向量化、数据入库等环节。
- 数据提取
o 数据加载:包括多格式数据加载、不同数据源获取等,根据数据自身情况,将数据处理为同一个范式。
o 数据处理:包括数据过滤、压缩、格式化等。
o 元数据获取:提取数据中关键信息,例如文件名、Title、时间等。
- 文本分割
文本分割主要考虑两个因素:
(1)embedding模型的Tokens限制情况;
(2)语义完整性对整体的检索效果的影响。
一些常见的文本分割方式如下:
o 句分割:以”句”的粒度进行切分,保留一个句子的完整语义。常见切分符包括:句号、感叹号、问号、换行符等。
o 固定长度分割:根据embedding模型的token长度限制,将文本分割为固定长度(例如256/512个tokens),这种切分方式会损失很多语义信息,一般通过在头尾增加一定冗余量来缓解。
- 向量化(Embedding)
向量化是一个将文本数据转化为向量矩阵的过程,该过程会直接影响到后续检索的效果。目前常见的Embedding模型基本能满足大部分需求,但对于特殊场景(例如涉及一些罕见专有词或字等)或者想进一步优化效果,则可以选择开源Embedding模型微调或直接训练适合自己场景的Embedding模型。
- 数据入库
数据向量化后构建索引,并写入数据库的过程可以概述为数据入库过程,适用于RAG场景的数据库包括:FAISS、Chromadb、Milvus、ES等。一般可以根据业务场景、硬件、性能需求等多因素综合考虑,选择合适的数据库。
2.3.2 应用阶段
在应用阶段,我们根据用户的提问,通过高效的检索方法,召回与提问最相关的知识,并融入Prompt;大模型参考当前提问和相关知识,生成相应的答案。关键环节包括:数据检索、注入Prompt等。
- 数据检索(Retrieval)
常见的数据检索方法包括:相似性检索、全文检索等,根据检索效果,一般可以选择多种检索方式融合,提升召回率。
o 相似性检索:即计算查询向量与所有存储向量的相似性得分,返回得分高的记录。常见的相似性计算方法包括:余弦相似性、欧氏距离、曼哈顿距离等。
o 全文检索:全文检索是一种比较经典的检索方式,在数据存入时,通过关键词构建倒排索引;在检索时,通过关键词进行全文检索,找到对应的记录,比如ES。
- 注入Prompt(Augmented)
Prompt作为大模型的直接输入,是影响模型输出准确率的关键因素之一。在RAG场景中,Prompt一般包括任务描述、背景知识(检索得到)、任务指令(一般是用户提问)等,根据任务场景和大模型性能,也可以在Prompt中适当加入其他指令优化大模型的输出。
- LLM生成(Generation)
在这个阶段,我们将经过检索增强的提示内容输入到大语言模型(LLM)中,以生成所需的输出。这个过程是RAG的核心,它利用LLM的强大生成能力,结合前两个阶段的信息,从而生成准确、丰富且与上下文相关的输出。
3. 基于LangChain的RAG实现
3.1 LangChain中RAG模块
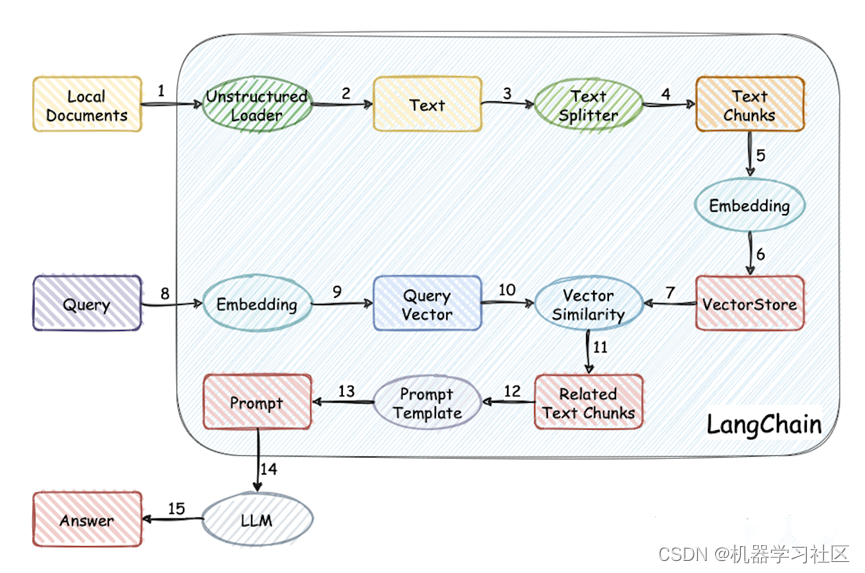
LangChain有许多组件用于帮助构建RAG应用程序。为了熟悉这些内容,我们将在网络文本数据源上构建一个简单的问答应用程序。在此过程中,我们将介绍一个典型的问答架构,讨论相关LangChain组件的使用,其工作流程如图。
3.2 基于LangChain实现RAG
我们将在Lilian Weng的「LLM Powered Autonomous Agents」博客文章基础上构建一个QA应用程序,该应用程序允许我们就文章内容提出问题。
1. 加载文档
首先需要收集并加载数据,可以利用LangChain提供的众多 DocumentLoader之一来加载这些数据。这里的Document是一个包含文本和元数据的字典,为了加载文本,我们可以使用LangChain的 WebBaseLoader来加载Web url,只有加载类为“post-content”、“post-title”或“post-header”的HTML标记内容。
import bs4
from langchain_community.document_loaders import WebBaseLoader
# Only keep post title, headers, and content from the full HTML.
bs4_strainer = bs4.SoupStrainer(class_=("post-title", "post-header", "post-content"))
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs={"parse_only": bs4_strainer},
)
docs = loader.load()
2. 文档切分
由于原始状态下的Document可能过长,无法适应大语言模型(LLM)的上下文窗口,所以我们需要将其分成更小的部分。LangChain内置许多该功能的文本分割器。在这个简单的示例中,我们可以使用RecursiveCharacterTextSplitter,递归地分割文档,直到每个块的大小合适。这是推荐用于一般文本用例的文本拆分器。设置chunk_size约为1000和chunk_overlap约为200,增加一定的冗余量,以保持块之间的文本连续性。
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200, add_start_index=True
)
all_splits = text_splitter.split_documents(docs)
3. 向量存储
需要为每个块生成向量embedding,并将其存储在向量数据库或向量存储中。为了生成向量embedding,我们可以使用OpenAI的embedding模型。同时,我们可以使用Chroma向量数据库来存储这些embedding。通过调用.from_documents()方法生成向量存储对象。
from langchain_community.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings()
4. 检索(Retrieval)
在检索过程中,系统接受用户问题,搜索与该问题相关的文档,将检索到的文档和初始问题传递给模型,并返回答案。最常见的检索器类型是VectorStoreRetriever,它使用向量存储的相似性搜索功能来简化检索。使用VectorStore.as_retriever(),任何VectorStore都可以很容易地转换为Retriever。
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 6})
5. 增强(Augmented)
接下来,需要使用检索到的上下文信息来增强我们的提示。为此,我们需要准备一个提示模板。在LangChain中,我们可以使用ChatPromptTemplate来创建一个提示模板。这个模板会告诉LLM如何使用检索到的上下文来回答问题。
from langchain import hub
prompt = hub.pull("rlm/rag-prompt")
生成的ChatPromptTemplate为:
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
6. LLM****生成回答(Generation)
最后,需要构建一个RAG流程链,将检索器、提示模板和LLM连接起来。定义好RAG链后,我们就可以调用它进行生成。这里使用OpenAI的gpt-3.5-turbo模型,其他LangChain LLM或ChatModel也可以进行替代。
from langchain.chat_models import ChatOpenAI
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.output_parser import StrOutputParser
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("What is Task Decomposition?")
输出结果:
'Task decomposition is a technique used to break down complex tasks into smaller and simpler steps.
It involves transforming big tasks into multiple manageable tasks, allowing for a more systematic and organized approach to problem-solving.
Thanks for asking!'
原文内容如图:

4. RAG优化Text2SQL应用的实践
4.1 现有问题
依然以上篇文中「大模型LLM在Text2SQL上的应用实践」的数据库Chinook为例,需求为统计“连续两个月都下订单的客户有哪些?”,示例代码可参考上文。
结果如下:
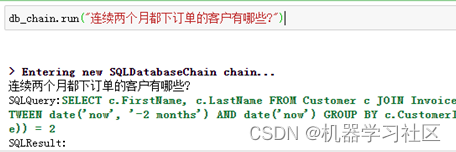
可以看出生成的SQL不准确,只统计了最近两个月中都下订单的客户,和统计需求不相符。那如何解决这个问题?
4.2 RAG解决方案
尽管SQL Toolkit包含处理数据库所需的工具,但通常情况下,一些额外的工具可能对扩展代理的功能有用。当试图在解决方案中使用特定领域的知识以提高其整体性能时,这一点尤其有用。
我们使用问题列表few-shot examples作为外部知识库,为了参考该知识库,我们需要一个利用向量数据库的自定义检索工具,以便检索语义上与用户问题相似的示例。
1. 创建的问题列表few-shot example如下:
few_shots = {
"How many employees are there?": "SELECT COUNT(*) FROM employee;",
"在订单表中,连续两个月都下订单的客户有哪些?":"SELECT DISTINCT a.'CustomerId', a.'FirstName', a.'LastName' FROM 'Customer' a JOIN 'Invoice' b ON a.'CustomerId' = b.'CustomerId' JOIN 'Invoice' c ON a.'CustomerId' = c.'CustomerId' AND ((strftime('%Y-%m', b.'InvoiceDate') = strftime('%Y-%m', date(c.'InvoiceDate', '-1 month'))) OR (strftime('%Y-%m', b.'InvoiceDate') = strftime('%Y-%m', date(c.'InvoiceDate', '+1 month'))))",
"同一客户的订单中连续两笔订单金额都大于1的客户有哪些?":"SELECT DISTINCT c.'CustomerId', c.'FirstName', c.'LastName' FROM 'Invoice' a JOIN 'Invoice' b ON a.'CustomerId' = b.'CustomerId' AND a.'InvoiceId' < b.'InvoiceId' JOIN 'Customer' c ON a.'CustomerId' = c.'CustomerId' WHERE a.'Total' > 1 AND b.'Total' > 1 AND NOT EXISTS ( SELECT 1 FROM 'Invoice' i WHERE i.'CustomerId' = a.'CustomerId' AND i.'InvoiceId' > a.'InvoiceId' AND i.'InvoiceId' < b.'InvoiceId')",
}
2. 可以使用问题列表创建一个检索器,将目标SQL查询分配为元数据:
from langchain.schema import Document
from langchain_community.embeddings.openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
embeddings = OpenAIEmbeddings()
few_shot_docs = [
Document(page_content=question, metadata={"sql_query": few_shots[question]})
for question in few_shots.keys()
]
vector_db = FAISS.from_documents(few_shot_docs, embeddings)
retriever = vector_db.as_retriever()
3. 现在可以创建自定义工具,并将其作为新工具附加到create_sql_agent函数中:
from langchain_community.agent_toolkits import create_retriever_tool
# description注意要加 in Chinese,使用中文检索,切记!
tool_description = """
This tool will help you understand similar examples to adapt them to the user question in Chinese.
Input to this tool should be the user question.
"""
retriever_tool = create_retriever_tool(
retriever, name="sql_get_similar_examples", description=tool_description
)
custom_tool_list = [retriever_tool]
4. 创建代理,根据我们的示例调整标准SQL Agent的后缀。尽管处理此问题的最直接方法是仅将其包含在上一步骤的“tool_description”中,但这通常是不够的,我们需要在agent prompt中使用构造函数的“suffix”参数来指定它。
from langchain.agents import AgentType, create_sql_agent
from langchain_community.agent_toolkits import SQLDatabaseToolkit
from langchain_community.chat_models import ChatOpenAI
from langchain_community.utilities import SQLDatabase
db = SQLDatabase.from_uri("sqlite:///xxxx/Chinook.db")
llm = ChatOpenAI(model_name="gpt-4", temperature=0)
toolkit = SQLDatabaseToolkit(db=db, llm=llm)
# 注意要加 in Chinese,使用中文检索,切记!
custom_suffix = """
I should first get the similar examples in Chinese I know.
If the examples are enough to construct the query, I can build it.
Otherwise, I can then look at the tables in the database to see what I can query.
Then I should query the schema of the most relevant tables
"""
agent = create_sql_agent(
llm=llm,
toolkit=toolkit,
verbose=True,
agent_type=AgentType.OPENAI_FUNCTIONS,
extra_tools=custom_tool_list,
suffix=custom_suffix,
)
5. 执行提问:
agent.run("连续两个月都有下订单的客户有哪些?")
结果如下:
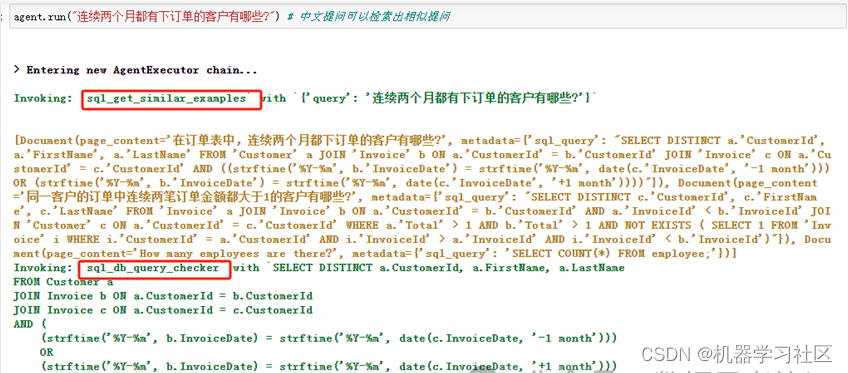

效果:生成的SQL与结果基本满足我们的需求。首先使用sql_get_similar_examples工具来检索类似的示例。由于该问题与few-shot examples中的示例相似,因此不需要使用Toolkit中的任何其他工具,从而节省了时间和tokens。
6. 换个相似的问题提问:
agent.run("找出哪些客户连续两个月都有下订单?")
结果如下:
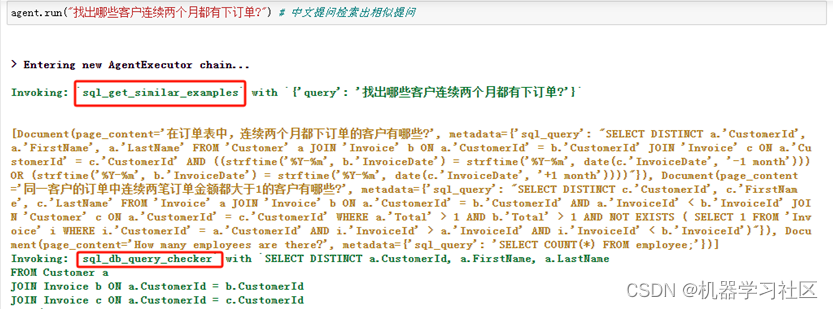

效果: 生成的SQL与结果基本满足我们的需求。
5. 后续计划
本文详细介绍了检索增强生成(RAG)的概念,并演示如何利用LangChain实现RAG流程,以及通过RAG来扩展SQL Agent的功能,进一步优化Text2SQL应用的效果。可以看到RAG为解决LLM在处理特定、最新和专有信息方面的不足提供了一个有效且灵活的方法,使其生成更精确、更贴合上下文的答案,有效减少误导性信息的产生。后续我们可以将数据管理中的元数据信息作为域内专业知识提供给大模型,借助RAG进一步提示LLM应用的效果。
参考文献:
https://arxiv.org/abs/2312.10997
https://python.langchain.com/docs/use_cases/question_answering
https://python.langchain.com/docs/use_cases/qa_structured/sql
https://zhuanlan.zhihu.com/p/668082024
https://zhuanlan.zhihu.com/p/666771841















 2308
2308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









