







最近已有不少大厂都在秋招宣讲了,也有一些在 Offer 发放阶段。
节前,我们邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。
针对新手如何入门算法岗、该如何准备面试攻略、面试常考点、大模型技术趋势、算法项目落地经验分享等热门话题进行了深入的讨论。
总结链接如下:
《AIGC 面试宝典》圈粉无数!
《大模型面试宝典》(2024版) 发布!
喜欢本文记得收藏、关注、点赞。更多实战和面试交流
在现代数据分析中,Python凭借其强大的数据处理能力和丰富的库资源成为首选工具。ChatGPT,作为先进的自然语言处理模型,正逐步成为Python数据分析与挖掘的强大辅助工具。
通过ChatGPT的自然语言处理能力,用户可以轻松生成代码、解释数据模型和优化算法,极大地提升了数据分析的效率和准确性。无论是数据清洗、特征工程还是建模预测,ChatGPT都能提供智能建议,助力数据分析人员更快地实现数据洞察和商业价值。
传统数据分析 VS ChatGPT+数据分析
模式对比
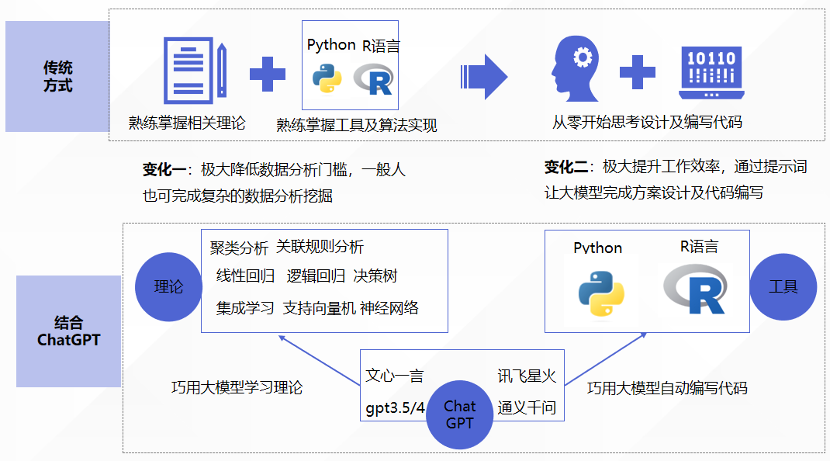
从对比可知,结合ChatGPT的交互式分析体验降低专业门槛,允许非专业认识以提问的形式探索数据,实时获取定制化的分析结果,增强了数据分析的灵活性和响应速度。同时节省人力成本和缩短周期,传统的数据分析需要专业人员投入大量时间和精力进行清洗、整理、建模和解读数据,而ChatGPT可以减轻这些负担,让专业人士更多地专注于策略制定和高层次问题解决。
ChatGPT辅助理论学习
ChatGPT辅助Python数据挖掘在理论学习方面具有显著优势。其强大的自然语言处理能力,使得复杂的数据挖掘概念、算法原理得以用简洁明了的语言阐述,降低了学习门槛。同时,ChatGPT能够根据学习者的反馈动态调整教学内容,提供个性化学习路径,加速理论学习进程。此外,ChatGPT还能模拟真实场景,帮助学习者在实践中巩固理论知识,提升数据挖掘技能。
以下是通过ChatGPT给小白介绍什么是一元线性回归原理的案例。
在ChatGPT输入以下问题:
作为数据挖掘专家,请用通俗易懂的语言给小白介绍线性回归原理,不要用Markdown,公式用LaTeX显示。
以下是ChatGPT给出的答复:
好的,我会尽量用简单的语言来解释线性回归的原理。线性回归的原理:假设我们有一堆数据,比如一组关于房子大小和价格的信息。我们想知道,房子的大小对价格有没有影响,而且影响程度是多少。
线性回归就像是在尝试找到一条直线,通过这条直线来最好地拟合已知的数据点。这条直线的方程可以表示为:
其中,是我们想预测的结果(比如房价),是已知的变量(比如房子的大小),是直线的斜率,是截距。
这个方程告诉我们,房价()与房子大小()之间存在一种线性关系。斜率表示这个关系的斜度,截距表示直线和轴的交点。
那么,当我们有了这条直线后,如果有新的房子大小,我们就可以用这个方程来预测它的价格。简而言之,线性回归就是试图用一条直线来最好地描述已知数据,并利用这条直线来预测未知数据的方法。
从ChatGPT给出的答复可知,一元线性回归就是一条直线(),我们希望利用变量和的已知数据,求出斜率和截距的值。
ChatGPT辅助代码生成
ChatGPT在辅助Python数据分析代码生成方面同样具有显著优势。首先,ChatGPT根据用户需求自动生成Python数据分析代码,极大提高了编码效率。其次,其强大的上下文理解能力使得代码生成过程更加连贯,减少了重复输入和错误。此外,ChatGPT还能根据用户反馈进行代码优化,确保生成的代码既高效又易于维护。此外,它还能在代码中添加注释和文档,提高代码的可读性和可维护性。这些优势使得数据分析人员可以节省大量编写和调试代码的时间,能够更专注于数据分析本身,而非编写代码,从而加速数据分析进程,提升工作效率。
以下是通过ChatGPT自动生成决策树算法代码。
在ChatGPT输入以下问题:
作为数据挖掘专家,请利用scikit-learn自带的iris数据集,使用DecisionTreeClassifier类构建决策树,要求自变量为petal length (cm)和petal width (cm),因变量为target。
以下是ChatGPT给出的答复:
当使用scikit-learn库构建决策树时,可以通过DecisionTreeClassifier类来实现。下面是一个简单的例子,展示如何使用iris数据集中的petal length (cm)和petal width (cm)作为自变量,target作为因变量来构建决策树。
导入所需的库
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score加载iris数据集
iris = load_iris()
X = iris.data[:, 2:] # 使用petal length (cm)和petal width (cm)作为自变量
y = iris.target # 因变量划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
创建决策树模型
model = DecisionTreeClassifier(random_state=42)
在训练集上训练模型
model.fit(X_train, y_train)
在测试集上进行预测
y_pred = model.predict(X_test)
计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"决策树在测试集上的准确率: {accuracy}")
这个例子首先加载iris数据集,然后选择使用petal length (cm)和petal width (cm)作为自变量(X),target作为因变量(y)。接着,将数据集划分为训练集和测试集,使用DecisionTreeClassifier类创建一个决策树模型,并在训练集上训练模型。最后,在测试集上进行预测,并计算模型的准确率。
如果想对生成的决策树进行可视化,在ChatGPT继续提问。
在ChatGPT输入以下问题:
如何对决策树进行可视化,不需要再重复建模。
以下是ChatGPT给出的答复:
要可视化决策树,你可以使用graphviz库,它可以将决策树转换为图形格式。首先,确保你已经安装了graphviz库。你可以使用以下命令安装:
pip install graphviz
然后,可以使用以下代码将决策树可视化:
from sklearn.tree import export_graphviz
import graphviz导出决策树结构为DOT格式
dot_data = export_graphviz(model, out_file=None,
feature_names=[“petal length (cm)”, “petal width (cm)”],
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
使用Graphviz库可视化DOT格式的决策树
graph = graphviz.Source(dot_data)
graph.render(“iris_decision_tree”) # 可选:保存可视化结果到文件
graph.view(“iris_decision_tree”) # 打开可视化结果
在上述代码中,export_graphviz函数将决策树导出为DOT格式的文本,然后使用graphviz.Source类将这个文本可视化。render方法可用于保存可视化结果到文件,而view方法则用于在默认的图形查看器中打开可视化结果。。















 447
447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









