







最近这一两周不少互联网公司都已经开始秋招提前批面试了。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
总结如下:
《大模型面试宝典》(2024版) 发布!
《AIGC 面试宝典》圈粉无数!
喜欢本文记得收藏、关注、点赞
问题1、LoRA原理
LoRA (Low-Rank Adaptation) 是一种用于大语言模型(LLM)微调的技术,旨在通过减少参数更新数量来降低计算和内存成本。其基本思想是将模型权重分解为两个低秩矩阵的乘积,仅微调其中的一个低秩矩阵,而保持原有的大型模型权重不变。
在微调阶段,固定大型模型的权重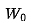 ,引入两个低秩矩阵 A 和 B,使得微调后的权重为
,引入两个低秩矩阵 A 和 B,使得微调后的权重为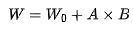 。A 的维度小且稀疏,因此
。A 的维度小且稀疏,因此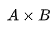 的计算负担相对较小。
的计算负担相对较小。
LoRA 在 NLP 任务中非常有效,因为它能够以较少的参数调整实现性能提升,并在保持原始模型权重的同时进行高效微调。
问题2、对Seq2Seq模型的理解
Seq2Seq(Sequence-to-Sequence)模型是一种编码器-解码器架构,广泛应用于机器翻译、文本摘要等序列生成任务。其工作流程如下:
-
编码器 (Encoder) 将输入序列编码为一个固定长度的隐状态向量(通常称为上下文向量)。
-
解码器 (Decoder) 基于该上下文向量逐步生成目标序列,每一步都会利用上一步生成的输出作为输入来预测下一步的输出。
Seq2Seq 可以基于 RNN、LSTM 或 Transformer 等架构实现。对于长文本,Seq2Seq 通过编码器-解码器的交互来捕捉全局信息,并生成流畅的输出。
问题3、self-attention原理
Self-Attention 是 Transformer 中的核心机制,用于捕捉序列中元素之间的依赖关系。它的工作原理如下:
-
每个输入序列中的元素都被映射到 Query (Q)、Key (K) 和 Value (V) 三个向量。
-
然后,计算 Query 和所有 Key 的点积,以获得注意力得分,代表了各个元素之间的相关性。
-
通过 softmax 将这些得分标准化,然后将其加权应用到对应的 Value 上,形成每个元素的最终表示。
Self-Attention 的优点在于能够处理长距离的依赖关系,并且可以并行计算,克服了 RNN 中的顺序依赖问题。
问题4、位置编码,LLM用的是什么?为什么这么设计?
由于 Transformer 模型没有顺序感知的能力,因此需要引入位置编码(Positional Encoding)来为模型提供输入序列的位置信息。常见的做法包括:
-
正弦-余弦编码 (Sinusoidal Positional Encoding):通过为每个位置生成不同频率的正弦和余弦函数来编码位置。它的优点是模型可以学习到不同位置之间的相对距离。
-
绝对位置编码 (Absolute Positional Encoding):将位置作为额外的输入向量直接加入到输入序列的嵌入中。
-
旋转位置编码 (ROPE):这是一种旋转式编码,通过旋转矩阵给嵌入添加位置信息,主要用于提升模型在处理不同输入长度时的能力。
LLM 使用位置编码是为了在序列建模时引入位置信息,确保模型理解元素的顺序。Sinusoidal 编码设计的原因是其平滑性和连续性允许模型捕捉输入中相对位置信息。
问题5、RAG了解吗?讲下RAG链路?RAG为什么有用?
RAG (Retrieval-Augmented Generation) 是一种结合检索机制和生成模型的方法。RAG 主要包括两个部分:
-
检索器 (Retriever):从一个大型文档库或知识库中检索相关的文档片段,通常使用向量召回方法,比如基于 dense embedding 的最近邻搜索。
-
生成器 (Generator):基于检索到的文档片段生成答案或文本。
RAG 的链路是:
-
接受输入查询。
-
检索器根据输入查询找到与之相关的上下文文档片段。
-
生成器基于检索到的上下文生成最终输出。
RAG 之所以有用,是因为它可以在生成模型的基础上加入额外的外部知识,提高了模型在知识密集型任务中的表现。相比纯粹的生成模型,RAG 更加灵活且易于扩展,因为它可以动态地使用检索到的上下文。
问题6、RAG向量召回怎么做的?
RAG 的向量召回通常基于密集向量检索技术。具体步骤如下:
-
将文档集合预处理为向量嵌入,通常使用深度学习模型如 BERT 来生成嵌入。
-
对于每个输入查询,生成相应的查询向量嵌入。
-
使用向量相似性搜索算法(如 FAISS)在文档嵌入空间中找到与查询向量最相似的文档向量。
-
返回相似度最高的文档,并作为上下文输入给生成器。
问题7、代码题:删除链表倒数第n个节点
class ListNode: def __init__(self, val=0, next=None): self.val = val self.next = next
def removeNthFromEnd(head: ListNode, n: int) -> ListNode: # 创建一个哑节点,以处理边界条件 dummy = ListNode(0) dummy.next = head first = dummy second = dummy
# 让第一个指针先移动 n + 1 步 for _ in range(n + 1): first = first.next
# 同时移动两个指针,直到第一个指针到达链表末尾 while first is not None: first = first.next second = second.next
# 删除倒数第 n 个节点 second.next = second.next.next
这个算法的关键在于使用两个指针,使得第二个指针最终指向要删除节点的前一个节点,从而可以完成节点的删除。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









