






一.僵尸进程的由来和解决方案:
概念: 僵尸进程是当子进程比父进程先结束,而父进程有没有回收子进程,释放子进程占用的资源此时子进程将成为一个僵尸进程。如果父进程先退出,子进程被init接管,子进程退出后init会回收其占用的相关资源。
危害: 由于子进程的结束和父进程的运行是一个异步过程,即父进程永远无法预测子进程到底什么时候结束,那么会不会因为父进程 太忙来不及wait进程,或者说不知道子进程什么时候结束,而丢失子进程的状态信息呢?不会UNIX提供一个种机制可以保证只要父进程想知道子进程结束时的状态信息,就可以得到。这种机制就是: 在每个进程退出的时候,内核释放该进程所有的资源,包括打开的文件,占用的内存等。但是仍然为其保留一定的信息(包括进程号the process ID,退出状态the termination status of the process,运行时间the amount of CPU time taken by the process等)。直到父进程通过wait / waitpid来取时才释放. 但这样就导致了问题,如果进程不调用wait / waitpid的话,那么保留的那段信息就不会释放,其进程号就会一直被占用,但是系统所能使用的进程号是有限的,如果大量的产生僵尸进程,将因为没有可用的进程号而导致系统不能产生新的进程.
用大白话说就是: 儿子和父亲一起在砌砖,但是儿子把自己的任务目标达成了干完了以后,就去休息了,但是父亲不知道儿子的任务目标是否达成,于是就把儿子剩下的砖拿过来砌自己这面墙,到后面他自己的任务完成以后但是儿子的砖又不够了,这样就造成了资源的不合理规划以及浪费。
解决方案: 1.当子进程结束暂时无其他任务任务可调度,用命令Kille -ps 父进程PID杀死(不推荐)
2.父进程通过wait和waitpid等函数等待进程结束,当然这会导致父进程挂起.
3.如果父进程很忙,那么可以用signal函数为sigchld安装handler,因为子进程结束后,父进程会收到该信号,可以在handler中调用wait回收。
4. 如果父进程不关心子进程什么时候结束,那么可以用signal(SIGCHLD,SIG_IGN) 通知内核,自己对子进程的结束不感兴趣,那么子进程结束后,内核会回收, 并不再给父进程发送信号.
二.HashMap1.7和1.8区别:
1.数据结构不一样:1.7是数组+链表,1.8则是数组+链表+红黑树结构(当链表长度大于8,转为红黑树).
2.扩容方法不一样:JDK1.8中resize()方法在表为空时,创建表,在表不为空时,扩容;JDK1.7中resize()方法负责扩容,inflateTable()负责创建表.
3.对于null值的定义不一样:1.7中对于键位null的情况调用putForNullKey()方法,1.8中null值既可以为KEY值,也可以为VALUE值.
4.添加元素时采用的方式不一样:1.7新增节点采用头插法,1.8中新增节点采用尾插法,这也是为什么1.8不容易出现环型链表的原因.
5.扩容策略不一样:1.7中是只要不小于阈值就直接扩容2倍;而1.8的扩容策略会更优化,当数组容量未达到64时,以2倍进行扩容,超过64之后若桶中元素个数不小于7就将链表转换为红黑树,但如果红黑树中的元素个数小于6就会还原为链表,当红黑树中元素不小于32的时候才会再次扩容.
三.SQL优化方法:
查询SQL尽量不要使用select*,而是具体字段
反例:SELECT * FROM student
正例:SELECT id,NAME FROM student
理由:
字段多时,大表能达到100多个字段甚至达200多个字段
只取需要的字段,节省资源、减少网络开销
select * 进行查询时,很可能不会用到索引,就会造成全表扫描避免在where子句中使用or来作为连接条件
反例:SELECT * FROM student WHERE id=1 OR salary=30000
正例:
# 分开两条sql写
SELECT * FROM student WHERE id=1
SELECT * FROM student WHERE salary=30000
理由:
使用or可能会使索引失效,从而全表扫描
对于or没有索引的salary这种情况,假设它走了id的索引,但是走到salary查询条件时,它还得全表扫描。也就是说整个过程需要三步:全表扫描+索引扫描+合并。如果它一开始就走全表扫描,直接一遍扫描就搞定。虽然mysql是有优化器的,处于效率与成本考虑,遇到or条件,索引还是可能失效的使用varchar代替char
反例:`deptname` char(100) DEFAULT NULL COMMENT '部门名称'
正例:`deptname` varchar(100) DEFAULT NULL COMMENT '部门名称'
理由:
varchar变长字段按数据内容实际长度存储,存储空间小,可以节省存储空间
char按声明大小存储,不足补空格
其次对于查询来说,在一个相对较小的字段内搜索,效率更高尽量使用数值代替字符串类型
主键(id):primary key优先使用数值类型int,tinyint
性别(sex):0-代表女,1-代表男;数据库没有布尔类型,mysql推荐使用tinyint
支付方式(payment):1-现金、2-微信、3-支付宝、4-信用卡、5-银行卡
服务状态(state):1-开启、2-暂停、3-停止
商品状态(state):1-上架、2-下架、3-删除查询尽量避免返回大量数据
如果查询返回数据量很大,就会造成查询时间过长。同时,大量数据返回也可能没有实际意义,通常采用分页,一页习惯10/20/50/100条。
使用explain分析的SQL执行计划
EXPLAIN
SELECT * FROM student WHERE id=1;
/*SQL很灵活,一个需求可以很多实现,那哪个最优呢?SQL提供了explain关键字,它可以分析你的SQL执行计划,看它是否最佳。Explain主要看SQL是否使用了索引*/是否使用了索引及其扫描类型
type:
1.全表扫描,没有优化,最慢的方式.
2.index索引全扫描.
3.range索引范围扫描,常用语<,<=,>=,between等操作
4.ref 使用非唯一索引扫描或唯一索引前缀扫描,返回单条记录,常出现在关联查询中
5.eq_ref 类似ref,区别在于使用的是唯一索引,使用主键的关联查询
6.const/system 单条记录,系统会把匹配行中的其他列作为常数处理,如主键或唯一索引查询
7.null MySQL不访问任何表9或索引,直接返回结果.
8.删除冗余和重复的索引
9.不要超过5个以上的表连接:
- 关联的表个数越多,编译的时间和开销也就越大
- 每次关联内存中都生成一个临时表
- 应该把连接表拆开成较小的几个执行,可读性更高
- 如果一定需要连接很多表才能得到数据,那么意味着这是个糟糕的设计了
- 阿里规范中,建议多表联查三张表以下
10.inner join、left join、right join、,优先使用inner join
三种连接如果结果相同,优先使用inner join,如果使用left join左边表尽量小
inner join 内连接,只保留两张表中完全匹配的结果集
left join会返回左表所有的行,即使在右表中没有匹配的记录
right join会返回右表所有的行,即使在左表中没有匹配的记录
理由:
如果inner join是等值连接,返回的行数比较少,所以性能相对会好一点
同理,使用了左连接,左边表数据结果尽量小,条件尽量放到左边处理,意味着返回的行数可能比较少。这是mysql优化原则,就是小表驱动大表,小的数据集驱动大的数据集,从而让性能更优
四.synchronized的作用和运行机制:
synchronized的三种应用方式:
- 修饰实例方法,作用于当前实例加锁,进入同步代码前要获得当前实例的锁.
- 修饰静态方法,作用于当前类对象加锁,进入同步代码前要获得当前类对象的锁.
- 修饰代码块,指定加锁对象,对给对象加锁,进入同步代码库前要获得给对象的锁.
synchronized的运行机制:
1.synchronized块是这样一个代码块,其中的代码必须获得对象sync Object。synchronized修饰的类或对象的所有操作都是原子的,因为在执行操作之前必须先获得类或对象的锁,直到执行完才能释放,这中间的过程无法被中断。

2.synchronized是实现线程同步的关键字,可以说在并发控制中是必不可少的部分。Mark Word,用于存储对象自身运行时的数据,如哈希码(Hash Code),GC分代年龄,锁状态标志,偏向线程ID、偏向时间戳等信息,它会根据对象的状态复用自己的存储空间。
3.如果当前monitor的进入数为0时,线程就会进入monitor。synchronize自动释放锁,而Lock必须手动释放,并且代码中出现异常会导致unlock代码不执行,所以Lock一般在Finally中释放,而synchronize释放锁是由JVM自动执行的。
五.Redis使用方式:
主从结构示意图:
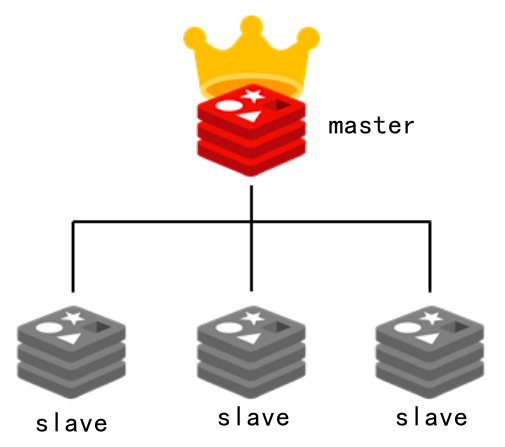
Redis的replication机制:
(1)redis采用异步方式复制数据到slave节点。
(2)一个master node是可以配置多个slave node的。
(3)slave node做复制的时候,是不会block master node的正常工作的。
(4)slave node在做复制的时候,也不会block对自己的查询操作,它会用旧的数据集来提供服务; 但是复制完成的时候,需要删除旧数据集,加载新数据集,这个时候就会暂停对外服务了。
(5)slave node主要用来进行横向扩容,做读写分离,扩容的slave node可以提高读的吞吐量
Redis哨兵模式:
概念:哨兵(Sentinel)是Redis的主从架构模式下,实现高可用性(high availability)的一种机制。由一个或多个Sentinel实例(instance)组成的Sentinel系统(system)可以监视任意多个主服务器,以及这些主服务器属下的所有从服务器,并在被监视的主服务器进入下线状态时,自动将下线主服务器属下的某个从服务器升级为新的主服务器,然后由新的主服务器代替已下线的主服务器继续处理命令请求.
Redis集群高可用:
概念:Redis单价模式可靠性保证不是很好,容易出现单点故障,同时其性能也受限于CPU的处理能力,实际开发中Redis必然是高可用的,Sentinel模式做到了高可用。
六.Spring cloud项目中的事务控制
概念:事务控制必须保证同一个连接,spring打个注解就解决了,但分布式里控制不住,可能是在自己微服务里同时调用三个微服务,不同数据库不同虚拟机不同ip地址,肯定控制不住.

CAP原则

在分布式事务中:
1.如果保证CP,就意味着要让所有子系统的数据操作要么全部成功,要么全部失败,不允许有不一致的情况发生。但是强一致性会造成性能下降。
2.如果保证AP,就意味着可以牺牲一定的一致性,允许在各个子系统中存在有的数据操作成功,有的数据操作失败的情况,只要通过后续处理,能够达到最终一致即可。
解决方案:
- XA
- TCC
- Seata 框架 AT 事务
- SAGA
- 可靠消息最终一致性
- 最大努力通知
Seata介绍:
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案
2019 年 1 月,阿里巴巴中间件团队发起了开源项目 Fescar(Fast & EaSy Commit And Rollback),和社区一起共建开源分布式事务解决方案。Fescar 的愿景是让分布式事务的使用像本地事务的使用一样,简单和高效,并逐步解决开发者们遇到的分布式事务方面的所有难题.
Seata 的 AT 模式(Automatic Transaction)是一种无侵入的分布式事务解决方案,是一个开源的分布式事务框架.
.
微服务系统中,各服务之间无法相互感知事务是否执行成功,这时就需要一个专门的服务,来协调各个服务的运行状态。这个服务称为 TC(Transaction Coordinator),事务协调器。
订单系统开始执行保存订单之前,首先启动 TM(Transaction Manager,事务管理器),由 TM 向 TC 申请开启一个全局事务。
全局事务开启后,开始执行创建订单的业务。首先执行保存订单,这时会先启动一个 RM(Resource Manager,资源管理器),并将 XID 传递给 RM 。

具体的执行流程如下:
1.用户服务的TM向TC申请开启一个全局事务,全局事务创建成功生成一个全局唯一的XID。
2.用户服务的RM向TC注册分支事务,该分支事务在服务执行新增用户逻辑,并将其纳入XID对应全局事务的管辖。
3.用户服执行分支事务,向用户表插入一条记录。
4.逻辑执行到远程调用积分服务时(XID在微服务调用链路的上下文中传播)。积分服务的RM像TC注册分支事务,该分支事务执行增加积分的逻辑,并将其纳入XID对应全局事务的管辖。
5.积分服务执行分支事务,向积分服务表插入一条记录,执行完毕后,返回用户服务。
6.用户服务分支事务执行完毕。
7.TM向TC发起针对XID的全局提交或回滚决议。
8.TC调度XID下管辖的全部分支事务完成提交或回滚请求。
分布式事务概念:
分布式系统会把一个应用系统分析拆分为可独立的部署的多个服务,因此需要服务与服务之间远程协作才能完成事务的操作,这种分布式系统环境由不同的服务之间通过网络远程协作完成事务称之为分布式事务,例如用户注册送积分事务、创建订单库存事务、银行转账事务等都是分布式事务。通过本地事务去完成分布式事务是行不通的例:
张三 建设银行 本地事务数据库成功了账户-100元
李四 中国银行 若远程调用也成功了账户+100元,但是由于网络远程回滚时由于信号等其他原因,导致远程调用超时,会在本地张三本地事务出现异常,导致本地事务回滚,也就是张三会+100元,但李四的账户已经+100元了,这种情况下就是分布式事务产生的问题。
分布式系统的特点:CAP,分别表示一致性,可用性,分区容忍性。
C一致性是指写操作后的读操作可以读取到最新的数据状态,当数据分布在多个节点上,从任意结点读取到的数据都是最新的状态。
一致性的特点:1.由于存在数据同步的过程,写操作的响应会有一定的延迟。
2.为了保证数据一致性会对资源暂时锁定,待数据同步完成释放锁定资源。
3.如果请求数据同步失败的结点则会返回错误信息,一定不会返回旧数据。
A-可用性是指任何事务操作都可以得到响应的结果,且不会出现响应超时或响应错误。
可用性的特点:
1.所有请求都有响应,且不会出现超时或响应错误。
P-分区容忍性是指分布式系统的各各结点部署在不同的子网,这就是网络分区,不可避免的会出现由于网络问题而导致结点之间的通信失败,此时认可对外提供服务,这就叫分区容忍性。
分布性分区容忍性的特点:1.分区容忍性是分布式系统具备的基本能力。用异步代替同步,松耦合。
CAP组合方式:
在所有分布式系统中,三者不可共存,P是基本具备能力,C和A不可共存。
1.AP:放弃一致性,追求分区容忍性和可用性,这是很多分布式系统设计的选择。
2.CP放弃可用性,追求一致性和分区容忍性,我们的zookeeper其实就是追求强一次性,又比如跨行转账,一次转账请求要等待双方银行系统都完成整个事务才算完成。
3.CA放弃分区容忍性,即不进行分区,不考虑由于网络不通或结点挂掉的问题,可以实现一致性和可用性。那么系统将不是一个标准的分布式系统,我们最常用的关系型数据库就满足了CA。
BASE理论
1.理解强一致性和最终一致性
CAP理论告诉我们分布式系统最多只能同时满足一致性,可用性和分区容忍性这三项中的两项,其中AP在实际应用中较多,就比如商品退款这个功能,在用户发起退款后,网页上会提示1-3个工作日退回到指定银行卡,这就是强调的最终数据的一致性,可以经过这个时间节点后实现数据的一致性。
2.BASE理论介绍:
BASE是Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)三个短语的缩写。BASE理论是对CAP中AP的一个拓展,通过牺牲强一致性来获得可用性,当出现故障允许部分不可用但要保证核心功能可用,允许数据在一段时间内是不一致的,但最终达到一致状态,满足BASE理论的事务,我们称之为“柔性事务”
特点:基本可用-分布式系统在出现故障时,允许损失部分可用功能,保证其核心功能可用,如:电商网站交易付款出现问题了,商品依然可以正常浏览。
软状态:由于不要求强一致性,所以BASE允许系统中存在中间状态,这个状态不影响系统可用性,如订单的“支付中”,“数据同步中”等状态,待数据最终一致后状态改变为“成功”状态。
最终一致:最终一致是指通过一段时间后,所有节点数据都将会达到一致,如订单的“支付中”状态,最终会变为“支付成功”或者“支付失败”,使订单状态与实际交易结果达成一致,但需要一定时间的延迟、等待。















 1610
1610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









