







# 本文作者全文手打,这不点个赞再走【doge】
# 如果有知识点遗漏欢迎在评论区留言
正文开始:
Chapter 12
Fundamental problem-solving and programming skills
Some key words definition
1. Abstraction
Abstraction involves filtering out information that is not necessary to solve a problem
2. Decompostion
Breaking problems down into sub-problems in order to explain a process more clearly
3. Algorithm
A sequence of defined steps that can be carried out to perform a task
4. Structured English
A subset of the English languages that consists of command statements used to descibe an algorithm
5. Pseudocode
A way of using keywords and identifiers to descirbe an algorithm without following the syntax of a particular programming language
6. Flowchart
Shapes linked together to represent the sequential steps of an algorithm
Four Structures
7. Assignment
A value is given a name(identifier) or the value associated with a given identifier is changed
8. Sequence
A number of steps are performed, one after the other
9. Selection
Under certain conditions some steps are performed, otherwise different (or no) steps are performed
10. Repetition
A sequence of steps are performed a number of times. This is also known as iteration or looping
11. Variable
A storage location for a data value that has an identifier
12. Roger value
A value used to terminate a sequence of values
13. Stepwise Refinment
Breaking down the steps of an outline solution into snaller abd smaller steps
14. Procedure
A sequence of steps that given an identifier and can be called to perform a sub-task
15. Function
A sequence of steps that is given an identifier and returns a single value, function call is a part of an expression
16. Local and Global Variables
Local: A variable that is accessible only within the module in which it is declared
Global: A variable that is accessible from all modules
Chapter 13 Data type and structure
Data type
- Integer
- Real
- Char
- String
- Boolean
- Date
- record
- arrays

Some inportant conceptions in array:
- Array index: Row or column number of an individual array element
- Upper bound: The highest number index of an array dimension
- Lower bound: The smallest number index of an array dimension
Linear search: Checking each element of an array in turn for a required value
BY REFERENCE AND VALUE: (后面会补充)
By reference (convey location of variables)
By value (顾名思义)
Pesudcode
BYREF <name> : <datatype>
BYVAL <name> : <datatype>
Expension
Bubble sort: A sort method where adjacent pairs of values are compared and swapped

Connect four game project:
1. 简易版
2. UI 版 (见之前发的pygame文章) https://blog.csdn.net/m0_59654229/article/details/121044218
Text files:
Pseudocode:
OPENFILE <FILENAME> FOR WRITE
WRITEFILE <FILENAME>, <STRINGVALUE> // MUST BE A STRING
CLOSEFILE <FILENAME>
Python:
handle = open('<file path>', '<open mode>')
or
with open('<file path>', '<open mode>') as handle:
!!! Abstract Data
Definition: A collection of data with associated operations
1. Stacks
elements in stacks:
- BaseOfStackPointer (BOSP)
- TopOfStackPointer (TOSP)
Intial statement:
TOSP is under BOSP which is -1 (BOSP is 0)
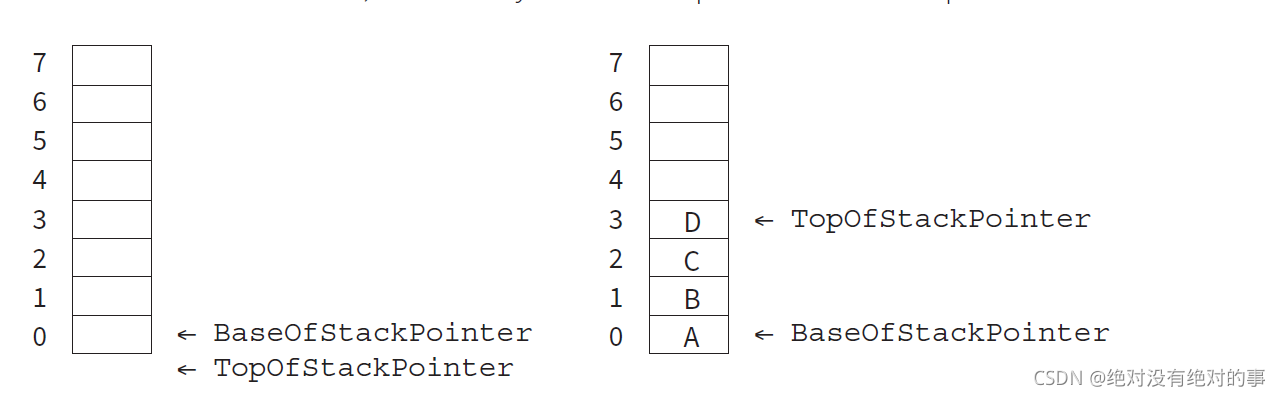
Characteristic:
FIFO (first in first off)
Representation in Pseudocode:
TYPE Node
DECLARE Name: STRING
DECLARE Pointer: INTEGER
DECLARE Stack1: ARRAY[0:7] OF Node
PROCEDURE PUSH_STACK(BYVALUE Element: STRING)
IF FreePointer = 0
THEN
REPORT ERROR
ELSE
Stack[FreePointer].Name <-- NewName (Node type)
TempPointer <-- FreePointer # Temporary storage variable
FreePointer <-- Stack[FreePointer].Pointer # Update FreePointer
Stack.[TempPointer].Pointer <-- TOSP
TOSP <-- TempPointer # 顶部指针移动
ENDPROCEDURE
For same theroy, we can write the procedure of pop. (you can try it by yourself at first)
TYPE Node
DECLARE Name: STRING
DECLARE Pointer: INTEGER
DECLARE Stack1: ARRAY[0:7] OF Node
PRODECURE POP_STACK ()
IF TOSP = 0 // detect if the stack is empty
THEN
REPORT ERROR
ELSE
OUTPUT Stack[TOSP].Name
TempPointer <-- TOSP
TOSP <-- Stack[TOSP].Pointer
Stack[TempPointer].Pointer <-- FreePointer
FreePointer <-- TempPointer
ENDIF
ENDPROCEDURE
# Like pop the last in name in the stack, and change the TOSP. And assign the stack.pointer points to the next node
2. Queues
elements in queues:
- FrontOfQueuePointer or Head Pointer
- EndOfQuenePointer or Tail Pointer
Inital statement:
HeadPointer and TailPointer are -1 which means the queue is empty

Characteristic:
FILO (first in last off)
Representation in Pseudocode:
PROCEDURE AddName(BYVALUE NewName : STRING)
IF FreePointer = 0 // detect if the queue is fully filled
THEN
REPORT ERROR
ELSE
CurrentPointer <-- FreePointer
Queue[CurrentPointer].Name <-- NewName
FreePointer <-- Queue[CurrentPointer].Pointer
IF HeadPointer = 0
THEN
HeadPointer <-- CurrentPointer
ENDIF
Queue[CurrentPointer].Pointer <-- FreePointer # 学案应该是写错了
TailPointer <-- CurrentPointer
ENDIF
ENDPROCEDURE
Other form:
Circular Queue

Linked list
- An element of a linked list is called node
- A node contain several items and a pointer
- Pointer is a variable that stores the address of node it points to
- Null pointer: A pointer that does not point anything (usually use ∅ )
- Start pointer: A variable that stores the address of the first element of a linked list
Example <picture>
Operation in linked list:
1. push and pop
2. The node isn't changed, the only thing that changed is pointer
In Pseudocode:
Using the index in array to acheive the function of pointer.
Example:
It usually has two arrays to represent a linked list which means there are two start pointers:
1. The array represent the present element(s) that are in linked list
2. The array represent the empty element(s) that are in linked list
Example <picture>
Chapter 14
Programming and data representation
Language in programming:
- Python (the best langeage, not one of the best languages. [doge])
- Java
- VB
Rules of precedence : Defined the order of calculations to be performed
Using python language to acheive four structures
1. Selection:
IF-THEN
if <condition>:
<statement(s)>
IF-THEN-ELSE
if <condition>:
<statement(s)>
else:
<statement(s)>
Nested if
if <condition>:
<statement(s)>
if <condition>:
<statement(s)>
CASE statement
if <condition>:
<statement(s)>
elif <condition>:
<statement(s)>
else:
<statement(s)>
2. Iteration
Post-condition loops (REPEAT-UNTIL)
while 1:
if <condition(s)>:
<statement(s)>
break
Pre-condition loops (WHILE-ENDWHILE)
while <condition>:
<statement(s)>
Build-in Function (For Python)
- string[index]
- chr(int) # return CHAR
- ord(char) # reutrn ASCLL
- len(S) # return length of string or list or dictionary or set
- (list or string)[a:b] # slicing (a, b could be negative)
- (string or char).upper() and .lower() return upper or lower version of string of char #(actually there isn't difference between string and char in Python)
- join two string: string1 + string 2
Procedure
PROCEDURE <NAME> (REL OR REF PARAMETERS)
<STATEMENT(S)>
ENDPROCEDURE
def <name>(parameters):
<statement(s)>
Function
reutrn value: the value replacing the function call used ini the expression
parameters: the acual input expression or value with which the subrountine in being called
Subroutine interface: the parameters being passed between the subroutine and the calling program
Function: the first line of a function or procedure definition showing the identifier and parameter list
By value: the actual value passed into the precedure
By reference: the address of the variable is passed into the procedure
I write Text File and REL REF in the previous pages
There are something that I want to add:
EOF (test if we got the last line in a text file)
In pseudocode:
WHILE NOT EOF <file name>
ENDWHILE
In Python:
while 1:
line = handle.readline()
if len(line)==0:
break
Chapter 15
Software development
The program development life cycle
-
Analysis
-
Design
-
coding
-
testing
-
Maintence
-
5 --> 1
<insert>
Models
The waterfall model:
Benefits:
Simply to understand as the stages are clearly defined
Easy to manage due to the fixed stages in model. Each stage has specific outcomes
Stages are [processed and completed one at a time
Work well for smaller prrojects where requirements are very well understand
<insert>
Drawbacks:
No working software is produced until late during the life cycle
Not a good model for complex and object-oriented projects
Poor model for long and ongoing project
Cannot accommodate changing requirements
It is difficult to measure progress within stages
Integration is done at the very end, which doesn't allow identifying potential techical or business issues early
The iterative model
Benefits:
There is a working model of the system at a very early stage of development, which makes it easier to find functional or design flaw. Finding issues at an early stage of development means corrective measures can be taken more quickly
Some working functionality can be developed quickly and early in the life cycle
Results are obtained early and periodically
Parallel development can be planned
Progress can be measured
Less costly to change the scope/requirement
Testing and debugging of a smaller subset of program is easy
Risking are identified and resolved during iteration
Easier to manage risk - high-risk park is done first
With every increment, operational product is delivered
Issues, challenges and risks identified from each increment can be utilised/applied to the next increment
Better suited for large and mission-critical projects
During the life cycle, software is produced quickly which facilitates customer evaluation and feedback
Drawbacks:
Only large software development














 3677
3677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









