






一、什么是内存重排序
重排序有指令重排序和内存重排序2种情况,指令重排序好理解,刚开始听到内存重排序的概念不是特别理解。为了加深理解,举一个例子说明什么是内存重排序:
| CPU0 | CPU1 |
|---|---|
| X=1 //S1 | Y=1 //S2 |
| r1=Y //S3 | |
| r2=X //S4 |
当前系统共2个CPU,CPU0和CPU1,上面是2个CPU执行的指令序列,其中X和Y为共享变量,r1和r2为局部变量。
上述CPU1执行S4处的指令后r2应该为1, r1应该为1,但有时间可能是r2为0,r1是1,即在CPU1看来好像S1的指令没有执行,但S3的指令已经执行了。这个不是由于指令排序造成的,是因为内存相关指令引起的,所以叫内存重排序。
二、发生内存重排序的原因
这个原因和CPU及其调整缓存相关,我们来看看整个CPU及缓存的架构变迁。
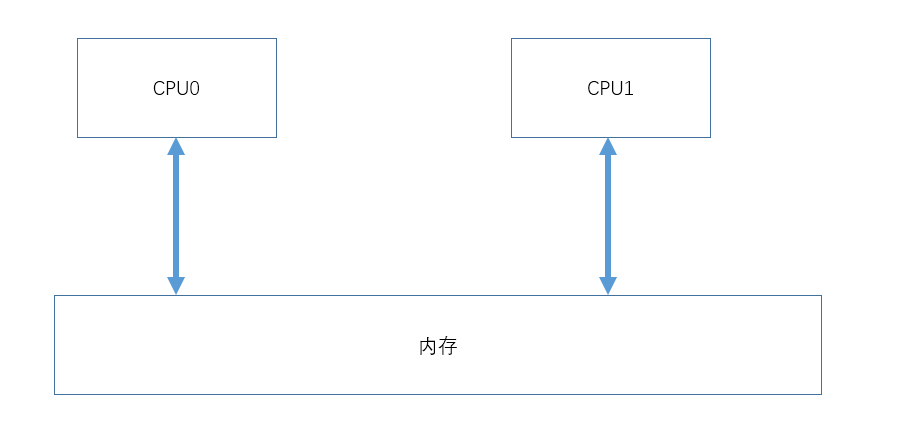
1、最初的架构
最早的CPU是没有做做任何优化,每次内存操作直接操作内存的。
2、加入Cache的架构
CPU执行指令的速度和访问内存指令速度是不匹配的,CPU执行速度太快,而访问内存的指令相对来说要慢些,为了加快快访问速度,硬件设计者们在每个CPU内部加入了高速缓存:
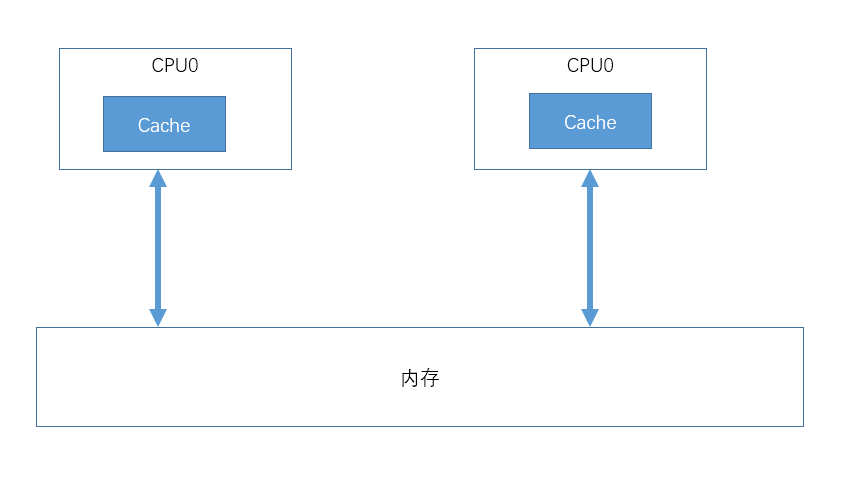
现在访问内存的流程是这样的:
先从高速缓存中读看有没有,如果没有则再从内存中读取,读到后再写入到高速缓存下次就可以命中缓存了。
这样在某些情况下访问内存速度确实加快了,但了带来了新的问题,如何保证各CPU高速缓存的数据一致性,即一个内存地址在每个CPU调整缓存中都有数据,现在某个CPU针对这个地址进行修改,怎么让其它CPU得到最新的数据?
为此设计者们引入了缓存一致性协议,这里不具体讨论这些协议的实现,说了大概的流程,加入协议之后,如果是一个写内存操作,必须通过通过总线广播一条消息我要修改某个地址了,然后让其它CPU更新或者删除自己的缓存,等所有其它CPU将自己缓存的数据更新后,才返回成功。
3、引入写缓冲及无效队列架构
前面讲了每个CPU加入自己的高速缓存后,如果是一个共享变量,整体性能会降低,那有没更快的办法呢,设计者们引入了写缓存:
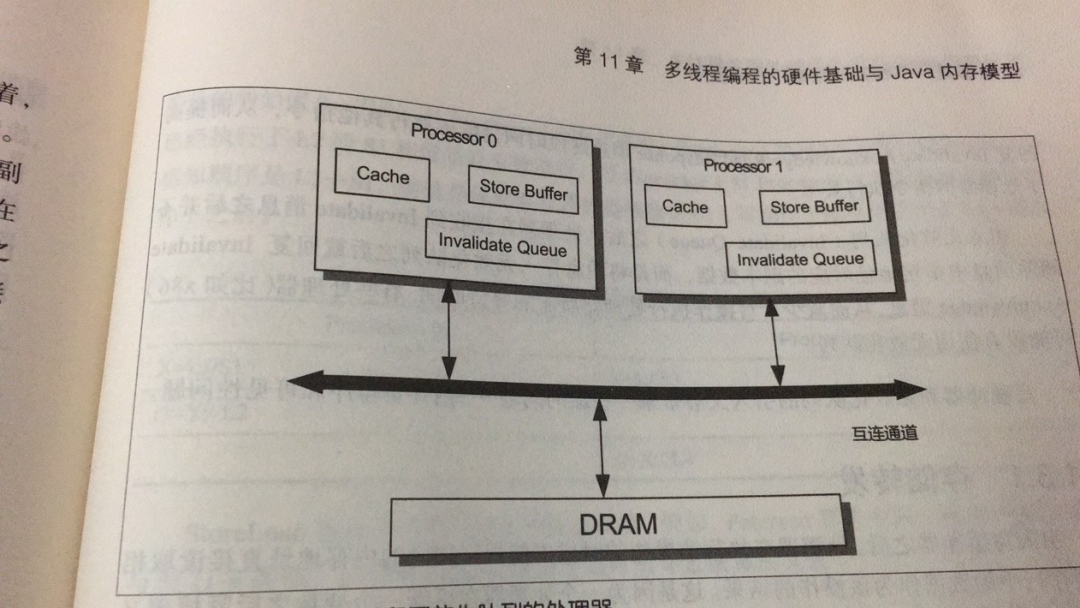
既然写内存是同步的,需要广播消息,能不能弄成异步的加快速度呢,写缓存队列就是干这个的,引入写缓存队列后写内存操作流程如下:
1)如果Cache中无数据,直接写入Cache,无需广播消息;
当然这里的Cache中无数据是每个Cpu的Cache都无数据,Cache一致性协议中有相关保障,有兴趣的同学可以学习下相关资料
2)如果Cache中有数据则写入写缓存器,然后就直接返回了
3)CPU再异步将写缓存器里的数据同步到其它CPU,这样就保证最终一致性了
这样可以加大写内存指令的速度了,因为不用广播消息,并且等待每个CPU的返回。
同样,这样也带来了新的问题,如果在写入指令写入高速缓存后,缓存的数据还没同步到其它CPU中,那其它CPU就有可能会读到脏数据。
现在我们回头来分析前面举的例子,为什么会发生这种情况:
CPU1执行到S4时,由于S1的执行结果可能还存留在写缓存中,因此CPU1无法感知到,所以执行S4的时候,CPU1读取到X的值还是未初始化的0。
怎么解决呢,Java有volatile关键字,加入这个关键字后,会在每次读取这个变量对应内存的时候,CPU都会发出一个清除缓存的指令,因而保证可以读取到最新的值。
三、总结
1、内存重排序实际上并不是真的相关操作被排序了,而是因为CPU引入缓存还没来得及刷新导致;
2、每个CPU都有自己的缓存,为了提高共享变量的写操作,CPU把整个操作变成异步的了,如果写入操作还没来的及同步到其它CPU,就有可能发生其它CPU读取到的是旧的值,因此看起来这条指令还没执行一样。

















 488
488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











