






机器学习--鸢尾花预测模型
今天开新坑了,python机器学习基础,本片内容是一个简单的机器学习的实例"鸢尾花预测模型",其基本内涵了scikit-learn机器学习库中所需的所有基本操作
环境: Anaconda
一些基本概念
1.因为已知鸢尾花的测量数据集,所以该模型为一个监督学习模型
2.在多个选项中预测出一种结果称为:分类
3.可能的输出称为:类别
4.一共n种输出: n分类问题
5.对于单个数据点的预测输出的类型: 标签
6.新数据的正确预测: 泛化
7.用于训练的数据集: 训练集(训练数据)
8.用于测试的数据集: 测试集(测试数据,留出集)
9.机器学习中,个体称为: 样本
10.每个样本所有的属性: 特征
导入的包:
from sklearn.datasets import load_iris # 鸢尾花数据集
from sklearn.model_selection import train_test_split # 数据集分割函数
from sklearn.neighbors import KNeighborsClassifier # k近邻算法类
import numpy as np # numpy
import pandas as pd # pandas
import matplotlib.pyplot as plt # 绘图鸢尾花类别预测基本
已知鸢尾花分为setosa,versicolor,virginica三个品种,该模型的目标为: 根据给出数据预测出 数据所属于的分类
模型搭建步骤
1.获取数据集
本案例为一经典案例,sklearn包内已包含可用数据集:
from sklearn.datasets import load_iris #可以直接导入数据集iris_datasets = load_iris() # load_iris() 返回的是一个Bunch对象,其和字典很相似,通过一些操作,可以得到该数据集内的数据和一些其他资料
# print('the key of iris_datasets:{}'.format(iris_datasets.keys())) # 拿到数据集的全部键
# print(iris_datasets['DESCR']) # 这个是数据集的说明
# print(iris_datasets['target_names']) # 这里面包含了分类的品种
# print(iris_datasets['feature_names']) # 这里面是特征的名字
# print(iris_datasets['data']) # 这里面有全部的数据,是一个二维数组
# print(iris_datasets['target']) # 这里面有数据的分类,是一个一维数组
数据集内的数据为 数据,标签 一一对应的形式2.将数据集分为训练数据和测试数据:
若需要利用数据构建一个机器学习模型,则首先应该测试出模型是否有效
但是,我们不能将训练数据来进行测试模型,因为模型会记住整个训练集,所以我们测试的结果总是对的。所以,不能用训练集来测试模型的泛化能力
为了解决这个问题,我们应该将数据集划分为训练集和测试集
实现:
scikit-learn中提供train_test_split() 函数
其可以打乱数据集并且进行 3:1 的拆分 25% 的测试集是前辈们的经验得出的
# 命名规范 X_train,y_train X_test,y_test random_state 指定随机数生成器的种子
X_train, X_test, y_train, y_test = train_test_split(iris_datasets['data'], iris_datasets['target'], random_state=0)
得到的数据集分为测试集和训练集,其中X的意思为输入的数据,y的意思为输出的结果,即标签(品种)3.观察数据
在建立模型前,最好先检测一下数据,观察是否可以不使用机器学习
观察数据的最好方法之一是将其变为可视化,将其变为散点图矩阵
方法:
1.将Numpy数组转为pandas DataFrame
2.利用pandas中有 一个名为 scatter_matrix 函数可以绘制散点图矩阵
#将其转为DataFrame,利用特征名字对其进行标记
iris_dataframe = pd.DataFrame(X_train, columns=iris_datasets.feature_names)
#利用Dataframe创建散点图矩阵,安装y_train进行染色
grr = pd.plotting.scatter_matrix(iris_dataframe, c=y_train, figsize=(15, 15), marker='o',
hist_kwds={'bins': 20}, s=60, alpha=.8)
#展示数据
plt.show()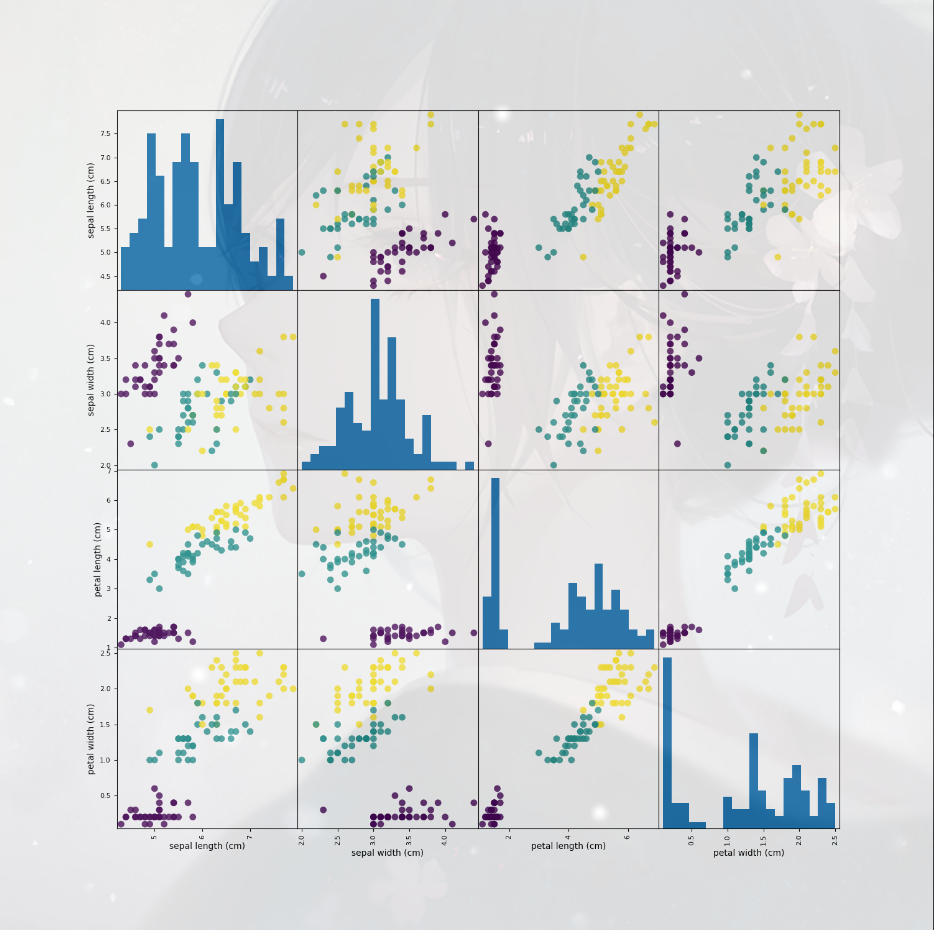
4.搭建模型
本次模型搭建选用的是‘k近邻算法’
k的含义:考虑训练集中与新数据点最近的任意k个邻居,而不是仅仅考虑最近的一个,然后用这些邻居中数量最多的类别进行预测
其中k近邻算法的一些方法已经被封装,所以可以直接通过调用库来实现
scikit-learn中所有的机器学习模型都在各自的类中实现,这些类被称为Estimator类
k邻居算法在 neighobors模块的KNeighborsClassifier类中实现,我们需要实例化一个对象才可以使用这个算法
该类中对要使用的方法进行了封装
其实例化的对象包含了训练数据构建模型的算法,也包含了预测的算法,还包含了提取出的信息
对于类来说,其仅仅保存了训练集
knn = KNeighborsClassifier(n_neighbors=1) # 实例化
knn.fit(X_train,y_train) # 训练函数,返回值为knn本身5.模型的使用
模型的使用在类中已经进行了封装,可以直接的调用函数实现
(1).创建数据: X_new = np.array([[5,2.9,1,0.2]]) # 输入的数据为一个二维的数组
(2).结果预测: prediction = knn.predict(X_new) # 返还的是一个一维数组,含有标签的序号
(3).展示结果: print('the name:{}'.format(iris_datasets['target_names'][prediction]))模型评估
对于已经搭建好的模型,我们要对其正确性来进行评估,这时就要使用到我们提前分离出来的测试集里面的数据和标签了
1.利用类中自带的评价函数
knn.score(X_test,y_test)
2.利用数组的计算
y_pre = knn.predict(X_test) # 得到测试集的预测结果,然后对正确的标签进行比较
print('the score:{:.2f}'.format(np.mean(y_pre == y_test))) # np.mean()函数功能:求取均值完整代码
点击查看代码
from sklearn.datasets import load_iris # 本数据集为一个经典数据集,可以直接导入数据集
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
iris_datasets = load_iris() # load_iris() 返回的是一个Bunch对象,其和字典很相似
# print('the key of iris_datasets:{}'.format(iris_datasets.keys())) # 拿到数据集的全部键
# print(iris_datasets['DESCR']) # 这个是数据集的说明
# print(iris_datasets['target_names']) # 这里面包含了分类的品种
# print(iris_datasets['feature_names']) # 这里面是特征的名字
# print(iris_datasets['data']) # 这里面有全部的数据,是一个二维数组
# print(iris_datasets['target']) # 这里面有数据的分类,是一个一维数组
# 数组包含了150朵花的测量数据,机器学习中个体称为样本,属性为特征,data数组的形状为样本数乘特征数
# 命名规范 X_train,y_train X_test,y_test random_state 指定随机数生成器的种子
X_train, X_test, y_train, y_test = train_test_split(iris_datasets['data'], iris_datasets['target'], random_state=0)
# print('X_train_shape:{},\n y_train:shape{}'.format(X_train.shape, y_train.shape))
# print('X_test_shape:{},\n y_test:shape{}'.format(X_test.shape, y_test.shape))
# 观察数据
# 将其转为DataFrame,利用特征名字对其进行标记
iris_dataframe = pd.DataFrame(X_train, columns=iris_datasets.feature_names)
# 利用Dataframe创建散点图矩阵,安装y_train进行染色
grr = pd.plotting.scatter_matrix(iris_dataframe, c=y_train, figsize=(15, 15), marker='o',
hist_kwds={'bins': 20}, s=60, alpha=.8)
# 展示数据
plt.show()
# k近邻算法
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(X_train, y_train)
X_new = np.array([[5, 2.9, 1, 0.2]])
prediction = knn.predict(X_new)
print('the prediction:{}'.format(prediction))
print('the name:{}'.format(iris_datasets['target_names'][prediction]))
# 模型评估
print('the score:{:.2f}'.format(knn.score(X_test, y_test)))















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









