






Opencv和机器学习
随着人工智能的相关研究不断发展 深度学习与图像处理相结合 弥补了传统图像处理在分类 识别领域的不足
人脸识别 一键换脸 风格迁移等应用 受到了广大人的喜欢
Opencv与机器学习相关的函数已经日渐丰富 本章将会介绍Opencv4中传统机器学习相关的函数和识别方法
并且会介绍Opencv4中和深度学习有关的内容
Opencv中和传统机器学习相关的函数和使用方法
Opencv中提供了两个有关机器学习的模块 分别是 Machine Learning(ml) 和 Deep Neural Network(dnn)
前者主要是传统机器学习的相关函数 后者则是集成了深度神经网络的相关函数
k均值聚类算法:
非常经典的一个聚类算法 一种无监督学习
根据指定的种类数目来进行聚类
k均值的步骤有以下四点:
1. 将数据分为k类 生成k个中心点
2. 遍历所有的数据 根据数据和中心的位置关系归到不同的中心
3. 计算每个聚类的均值 作为新的中心点
4. 重复2 3 直到聚类中心的坐标收敛 输出结果
函数:
retval,bestLabels,centers = cv.kmeans(data,k,bestLabels,criteria,attempts,flags,centers)
data: 需要聚类的输入数据 该参数 按行排列 每行都是一个单独的数据 图像可以先转为N*1代表每个有一个特征 共N个数据
K: 给定的聚类数目 必须是正整数
bestLabels: 存储每个数据聚类结果 中索引的矩阵或向量 和输入有相同的大小 存储的就是标签的索引
cireria: 迭代停止条件
attempts: 表示尝试采样不同初始化标签的次数
flags: 每类中心坐标初始化的方法
cv.KMEANS_RANDOM_CENTERS 随机位置
cv.KMEANS_USE_INITIAL_LABELS 第一次尝试时 使用用户提供的标签 后续随机
cv.KMEANS_PP_CENTERS 使用Arthur和Vassilvitskii提出的kmeans++方法初始化
centers: 最终聚类后每个类的中心坐标 如果不要输入Noneimport cv2 as cv
import numpy as np
# 展示kmeans聚类算法
from matplotlib import pyplot as plt
if __name__ == '__main__':
# 产生两组点 以x y 为特征
pts1 = np.random.randint(100,200,(25,2))
pts2 = np.random.randint(300,400,(25,2))
pts = np.vstack((pts1,pts2))
# vstack(()) 垂直把数组堆叠 [[],[],...[]],[[],[],...,[]] == [[],[],.....[]]
data = np.float32(pts)
#如果精度满足就停止迭代 如果达到最大迭代数就停止迭代
#cv.TERM_CRITERIA_COUNT 迭代次数到达后 停止
#criteria = (type,count,eps)
criteria = (cv.TERM_CRITERIA_EPS+cv.TERM_CRITERIA_MAX_ITER,10,1.0)
ret,label,center = cv.kmeans(data,2,None,criteria,2,cv.KMEANS_RANDOM_CENTERS)
ap = data[label.ravel() == 0]
bp = data[label.ravel() == 1]
# A[:,0] a类点的x
plt.scatter(ap[:,0],ap[:,1],s=10,c='r')
plt.scatter(bp[:,0],bp[:,1],s=10,c='b')
plt.scatter(center[:,0],center[:,1],s=20,c='g',marker='*')
plt.title('kmeans')
plt.xlabel('x')
plt.ylabel('y')
plt.show()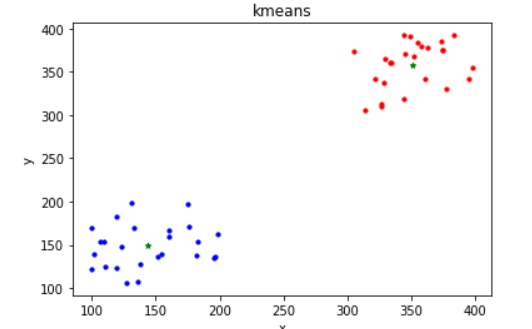
利用k均值聚类可以实现图像的像素分割
在分割时 特征是每个像素的值
1. 先将每个像素整理为 N*1
2. 聚类
3. 将不同的类表示为不同的颜色import cv2 as cv
import numpy as np
import sys
if __name__ == '__main__':
cap = cv.VideoCapture(0)
if not cap.isOpened():
print('视频开启失败')
sys.exit()
_,img = cap.read()
data = img.reshape((-1,3))
data = np.float32(data)
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER,10,1)
ret,labels,centers = cv.kmeans(data,3,None,criteria,3,cv.KMEANS_RANDOM_CENTERS)
for i in range(3):
data[labels.ravel() == 0] = (255,0,0)
data[labels.ravel() == 1] = (0,255,0)
data[labels.ravel() == 2] = (0,0,255)
res = data.reshape(img.shape)
cv.imshow('res',res)
cv.waitKey(0)
cap.release()
cv.destroyAllWindows()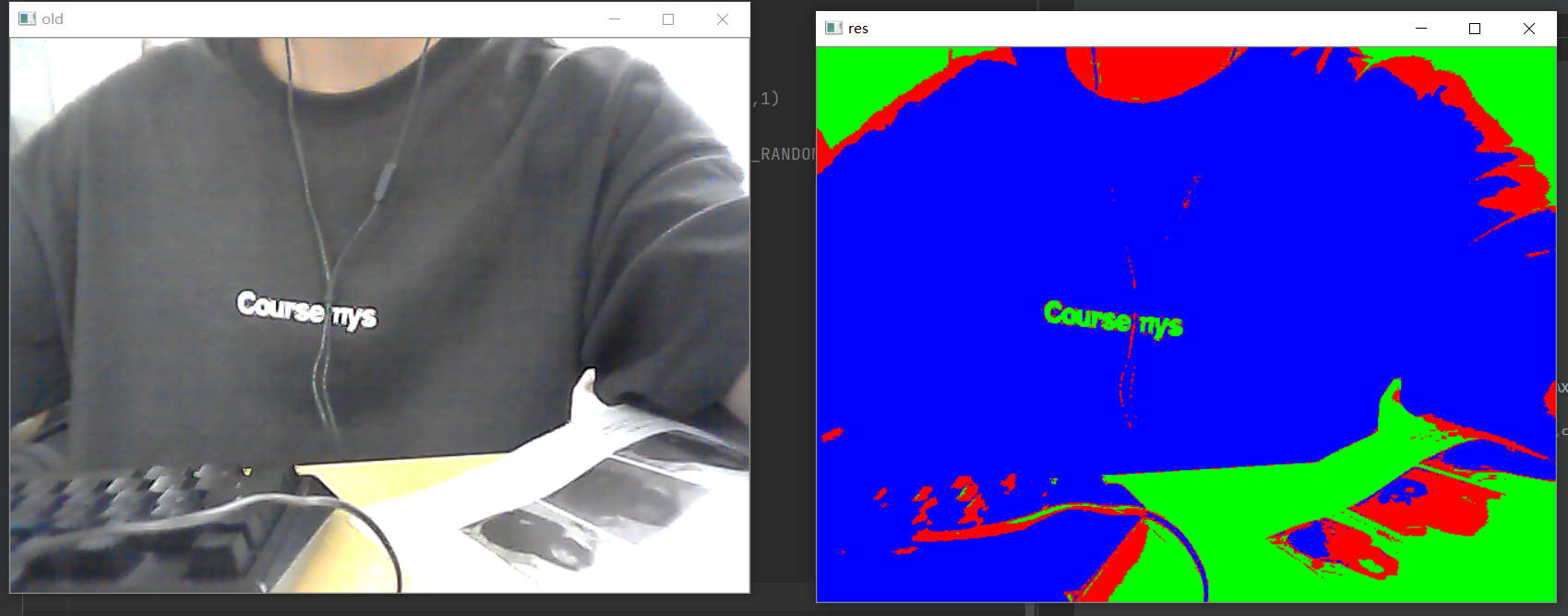
k近邻算法
一个监督学习算法 常用于对象的分类 根据近邻的个数K 来找和物体最相近的K个目标 其中最多的类型及为物体当前类型
在 传统的机器学习算法在Opencv4中实现类似于特征点检测算法的实现 先定义一个base的机器学习类
每个方法的具体实现继承这个base类实现
k近邻算法是使用的是KNearest类 继承了StatModel类(base类)
StatModel类 方法:
训练函数
ret = cv.ml_StatModel.train(samples,layout,responses)
samples: 训练的样本矩阵
layout: 排列方式
responses: 标签矩阵
返还一个bool类型变量来作为是否完成了模型训练
samples 必须为float32类型
layout cv.ml.ROW_SAMPLE 样本按行排列
cv.ml.COL_SAMPLE 按列排列
responses: 单行或者单列的矩阵 类型为int 或者 float
检测函数
retval, res = cv.ml_StatModel.predict(samples)
flags模型标志
res 结果矩阵
samples 输入矩阵
retval: 第一个值得标签
下面提供了一个有5000个手写数字的图片
每个手写数字占20 * 20
大小为 2000 * 1000 100 * 50 一行50张 一共100行
首先将图片转为
5000 * 20的矩阵
再创建一个
5000 * 1 的矩阵存储数值标签
将训练的模型保存为 一个 .yml文件
# np.hsplit 按列切分每n列变为新的一行 每列对应为新的元素
# np.vsplit 按行切份每n行变成新的一行
模型的训练import cv2 as cv
# 导入数据分割函数 引入这个包 为了分割出数据集和测试集
from sklearn.model_selection import train_test_split
# 1000 * 2000
import numpy as np
img = cv.imread('digit.png')
# 1000 // 50
print(img.shape)
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# gray先 分为 50 行 一行有100个数字 将100个数字分开 [
# [数字1的第一列][数字1的第二列][。。]..[。。]
# [数字1的第一列][..][..]..[..]
#
# [数字2的第一列][][]。。
# ]
cells = [np.hsplit(row, 100) for row in np.vsplit(gray, 50)]
x = np.array(cells).astype(np.float32)
# 将每一行的图片合并 铺平
all_data = x.reshape(-1, 400)
cv.imwrite('all_data.jpg', all_data)
print(all_data.shape)
# np.repeat()用于将numpy数组重复。
# numpy.repeat(a, repeats, axis=None);
# 参数:
# axis=0,沿着y轴复制,实际上增加了行数
# axis=1,沿着x轴复制,实际上增加了列数
k = np.arange(10)
all_label = np.repeat(k, 500).reshape(5000, 1)
cv.imwrite('all_label.jpg', all_label)
# 打散并分为测试集 数据集 保存
train_data, test_data, train_label, test_label = train_test_split(all_data, all_label, random_state=0)
# print(test_data)
cv.imwrite('train_data.jpg',train_data)
cv.imwrite('test_data.jpg',test_data)
cv.imwrite('train_label.jpg',train_label)
cv.imwrite('test_label.jpg',test_label)
# 生成k近邻算法的对象
knn = cv.ml.KNearest_create()
# 设置近邻数
knn.setDefaultK(5)
# 设置是否分类
knn.setIsClassifier(True)
model = knn.train(train_data, cv.ml.ROW_SAMPLE, train_label)
res = knn.save('knn_model.yml')
print('im ok')
# cv.waitKey(0)模型保存函数:
None = cv.ml_StatModel.save(path)
将模型保存为 .yml文件
模型加载函数:
retval = cv.ml.KNearest_load(filepath)
加载knn的模型
返还的是KNearest对象
预测:
除了使用
StatModel提供的通用的预测方法
KNearest类也提供了预测方法
retval,results,neighborResponses,dist = cv.ml_KNearest.findNearest(
sample
k
)
sample: 待预测数据
k: 近邻数
results: 预测结果
neighborResponses: 可以选择输出的每个数据的k个最近邻
dist: 输出k个最近邻的距离import cv2 as cv
import numpy as np
if __name__ == '__main__':
knn = cv.ml.KNearest_load('knn_model.yml')
test_data = cv.imread('test_data.jpg',cv.COLOR_BGR2GRAY).astype(np.float32)
test_label = cv.imread('test_label.jpg',cv.COLOR_BGR2GRAY)
print(test_data.shape)
_,res = knn.predict(test_data)
match = (test_label == res)
# 统计非0个数
match_num = np.count_nonzero(match)
accur = match_num / len(res)
print(accur)识别率为 82%
决策树算法
决策数算法也是一种对数据进行分类的算法
主要思想是通过构建树状结构来对数据进行分类
Opencv中的DTrees类
retval = cv.ml.DTrees_create()
retval = cv.ml.DTrees_load()
模型参数:
1. setMaxDepth() 必须 树最大深度 输入参数为正整数
2. setCVFolds() 必须 交叉验证 一般为0
3. setUseSurrogates() 非必须 是否建立代替分裂点 输入 bool
4. setMinSampleCount() 非必须 节点最小样本数 当样本数量过小 则不细分
5. setUselSERule() 非必须 表示是否严格剪枝
6. setTruncatePrunedTree() 非必须 分支是否完全移除import cv2 as cv
import numpy as np
# 读入训练集
train_data = cv.imread('train_data.jpg',cv.COLOR_BGR2GRAY).astype(np.float32)
train_label = cv.imread('train_label.jpg',cv.COLOR_BGR2GRAY).astype(np.int32)
# 读入测试集
test_data = cv.imread('test_data.jpg',cv.COLOR_BGR2GRAY).astype(np.float32)
test_label = cv.imread('test_label.jpg',cv.COLOR_BGR2GRAY).astype(np.int32)
# print(test_label)
dt = cv.ml.DTrees_create()
dt.setMaxDepth(10)
dt.setCVFolds(0)
# 训练保存模型
dt.train(train_data,cv.ml.ROW_SAMPLE,train_label)
dt.save('dt_model.yml')
# 得到结果
_,res = dt.predict(test_data)
print(res)
# 计算成功率
match = res == test_label
match_num = np.count_nonzero(match)
print('识别成功率为:{}'.format(match_num / len(test_label)))
# print(test_label)
随机森林算法
决策树在使用时仅仅构建一棵树 这样容易出现过拟合现象 可以通过构建多个决策树来避免过拟合现象
当构建多个决策树时 就出现了随机森林
这种方法通过多个决策树的投票来得到在最终的结果
RTrees类:
setRegressionAccuracy() 非必须 回归算法的精度
setPriors() 非必须 数据类型
setCalculateVarImportance() 非必须 是否要计算var
setActiveVarCount() 非必须 设置var的数目import cv2 as cv
import numpy as np
train_data = cv.imread('train_data.jpg',cv.COLOR_BGR2GRAY).astype(np.float32)
train_label = cv.imread('train_label.jpg',cv.COLOR_BGR2GRAY).astype(np.int32)
test_data = cv.imread('test_data.jpg',cv.COLOR_BGR2GRAY).astype(np.float32)
test_label = cv.imread('test_label.jpg',cv.COLOR_BGR2GRAY).astype(np.int32)
# print(test_label)
rt = cv.ml.RTrees_create()
rt.setMaxDepth(10)
rt.setCVFolds(0)
rt.train(train_data,cv.ml.ROW_SAMPLE,train_label)
rt.save('dt_model.yml')
_,res = rt.predict(test_data)
print(res)
match = res == test_label
match_num = np.count_nonzero(match)
print('识别成功率为:{}'.format(match_num / len(test_label)))
# print(test_label)
支持向量机
也是一种分类器 可以将不同的样本通过超平面分割在不同的区域
在直线分割样本时 如果直线距离样本太近 则会使直线容易受到噪声的影响
具有较差的泛化性 因此 寻找最佳分割直线就是寻找一条与所有点最远的直线
在支持向量机中 两条直线的间距称为间隔
retval = cv.ml.SVM_create()
全部非必须
setKernel() 设置核函数模型
setType() 设置SVM类型
setTermCriteria() 迭代停止条件
setGamma() 设置算法中的γ参数
setC() 设置算法中的c变量
setP() 设置e变量
setNu 设置v变量
setDegree 设置核函数度数
核函数的可选参数
cv.ml.SVM_LINEAR 0 线性核函数
cv.ml.SVM_POLY 1 多项式核函数
cv.ml.SVM_LINEAR 2 径向基函数
cv.ml.SVM_LINEAR 3 sigmodi核函数
cv.ml.SVM_LINEAR 4 指数卡方核函数
cv.ml.SVM_LINEAR 5 直方图交叉核函数import cv2 as cv
import numpy as np
train_data = cv.imread('train_data.jpg',cv.COLOR_BGR2GRAY).astype(np.float32)
train_label = cv.imread('train_label.jpg',cv.COLOR_BGR2GRAY).astype(np.int32)
test_data = cv.imread('test_data.jpg',cv.COLOR_BGR2GRAY).astype(np.float32)
test_label = cv.imread('test_label.jpg',cv.COLOR_BGR2GRAY).astype(np.int32)
# print(test_label)
svm = cv.ml.SVM_create()
svm.setKernel(1)
svm.setType(cv.ml.SVM_C_SVC)
svm.setDegree(3)
svm.train(train_data,cv.ml.ROW_SAMPLE,train_label)
svm.save('svm_model.yml')
_,res = svm.predict(test_data)
print(res)
match = res == test_label
match_num = np.count_nonzero(match)
print('识别成功率为:{}'.format(match_num / len(test_label)))
# print(test_label)















 362
362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









