






文章目录
前言
本文主要介绍在结合文件基础操作上进行哈夫曼编/译码器的设计与实现,其中主要实现接收原始数据、编码、译码、打印编码规则这几个功能。同时将详细介绍本人对这一程序的设计思想与过程,以及自己在编写程序与运行与测试时遇到的问题即解决方法。
一、问题描述:
利用哈夫曼编码进行通信可以大大提高信道利用率,缩短信息传输时间,降低传输成本。但是,这要求在发送端通过一个编码系统对待传数据预先编码,在接收端将传来的数据进行译码。系统应该具有如下的几个功能:接收原始数据、编码、译码、打印编码规则。
二、数据结构设计:
1、课设要求:
(1)构造哈夫曼树时使用顺序表作为哈夫曼树的存储结构。
(2)求哈夫曼编码时使用一维结构数组作为哈夫曼编码信息的存储。
2、具体实现:
我主要定义了三种数据结构。
(1)定义了动态分配的二维数组来存储哈夫曼树,每个结点都有五个域,分别是权值域、字符域、双亲域与左孩子和右孩子域。结构如下
//哈夫曼树存储结构定义
typedef struct
{
int weight;//权值
char ch;//结点对应字符
int parent, lchild, rchild;//结点的双亲和左右孩子
}HTNode,*HuffmanTree;//动态分配数组存储哈夫曼树
(2) 定义了动态分配的指针数组来存储哈夫曼编码,数组内存储的指针分别指向对应存储编码的一维字符数组。结构如下:
typedef char** Huffmancode;//动态分配数组存储哈夫曼编码
HC = (Huffmancode)malloc((n + 1) * sizeof(char*));
HC[i] = (char*)malloc((n - start) * sizeof(char));(3) 定义了存放字符及其权值的结构体。结构如下:
//存放字符及其权值的结构体
struct Data_type
{
char c;
int weight;
}Data[50];三、功能(函数)设计
1、课设要求
(1)初始化功能模块模块的功能为从键盘接收字符集大小n,以及n个字符和n个权值。
(2)建立哈夫曼树的功能模块此模块功能为使用1中得到的数据按照构造哈夫曼树的算法构造哈夫曼树,即将HuffNode数组中的各个位置的各个域都添上相关的值,并将这个结构体数组存于文件中。
(3)建立哈夫曼编码的功能模块此模块功能为从文件中读入相关的字符信息进行哈夫曼编码,然后将结果存入,同时将字符与0、1代码串的一一对应关系打印到屏幕上。
(4)译码的功能模块此模块功能为接收需要译码的0、1代码串,按照3中建立的哈夫曼编码规则将其翻译成字符集中的字符所组成的字符串形式,存入文件,同时将翻译的结果在屏幕上打印输出。
2、具体实现:
本人根据设计内容设计了五个功能模块,模块图如下:
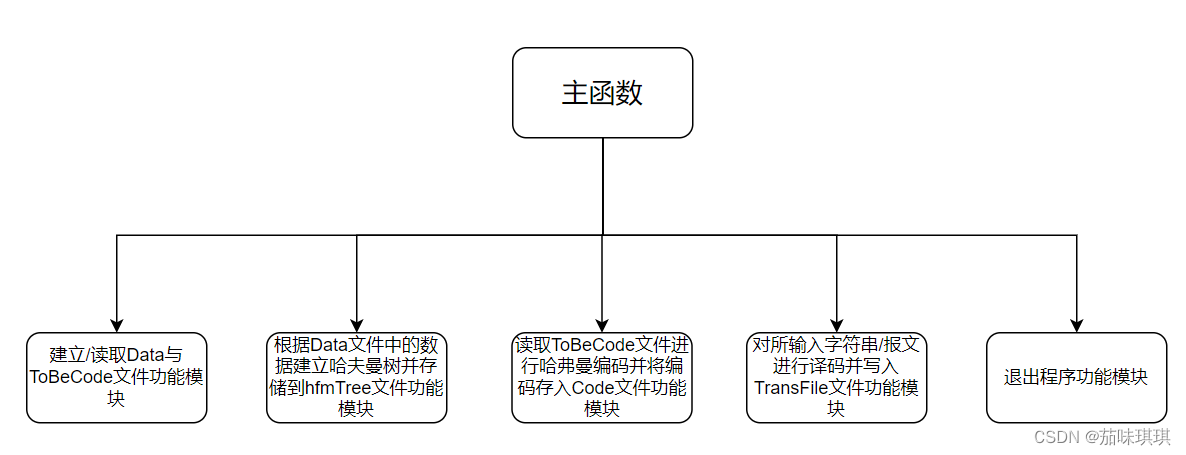
以下为每个模块所用到的函数以及函数功能描述:
(1)建立/读取Data与ToBeCode文件功能模块:
case 1://建立/读取Data与ToBeCode文件
{
printf("1、键盘输入字符及其权值建立Data.txt文件\n");
printf("2、直接读取文件中存储的字符与权值\n");
printf("请选择以上两种方式中的一种:");
int c;
scanf_s("%d", &c);
getchar();
switch (c)
{
case 1:
{
printf("请建立文件Data用以存放字符及其权值:\n");
InitData(n);//建立文件Data与ToBeCode并输出字符及其对应权值
printf("建立文件成功,请选择下一步操作:\n");
printf("\n\n");
break;
}
case 2:
{
if ((fp = fopen("Data.txt", "r")) == NULL)
{
printf("文件读取失败\n");
exit(0);
}
printf("各个字符及其对应的权值如下:\n");
//从文件中读取字符及其权值存入Data数组
for (int i = 0; i < n; i++)
{
fscanf(fp, "%c%d", &Data[i].c, &Data[i].weight);
printf("%c--%d\t", Data[i].c, Data[i].weight);
}
InitToBeCode(n);///创建ToBeCode文件存储要进行编码的字符
printf("读取成功,请选择下一步操作:\n");
printf("\n\n");
break;
}
default:
{
printf("输入错误请重新输入:\n");
break;
}
}
break;
}(2)根据Data文件中的数据建立哈夫曼树并存储到hfmTree文件功能模块:
case 2://从文件Data中读取数据来建立哈夫曼树并将数组存于文件hfmTree中
{
CreateTree(HT, n);//建立哈夫曼树函数
printf("建立哈夫曼树成功,请选择下一步操作:\n");
printf("\n\n");
break;
}(3) 读取ToBeCode文件进行哈弗曼编码并将编码存入Code文件功能模块:
case 3://对文件ToBeCode中的字符进行编码再写入Code文件中,并输出字符对应编码
{
HuffmanCoding(HT, HC, n);//哈夫曼编码函数
printf("编码成功,请选择下一步操作:\n");
printf("\n\n");
break;
}(4) 对所输入字符串/报文进行译码并写入TransFile文件功能模块:
case 4://对文件CodeFile译码再写入TransFile中,并输出译码结果
{
printf("请选择以下两种操作中的其中一个:\n");
printf("1、输入字符串并对其进行译码\n");
printf("2、输入报文对其进行编码后进行译码\n");
printf("请输入您的选择:");
int b;
scanf("%d", &b);
getchar();
switch (b)
{
case 1:
{
InitCode(n);//输入字符串并存入CodeFile函数
TranslateTree(HT, n);//哈夫曼译码函数
printf("译码成功,请选择下一步操作:\n");
printf("\n\n");
break;
}
case 2:
{
Trans(HT, HC, n);//输入报文并进行编码函数
TranslateTree(HT, n);//哈夫曼译码函数
printf("译码成功,请选择下一步操作:\n");
printf("\n\n");
break;
}
default:
{
printf("输入错误请重新输入:\n");
break;
}
}
break;
}(5) 退出程序功能模块:
case 5://退出程序
{
return 0;
}四、界面设计
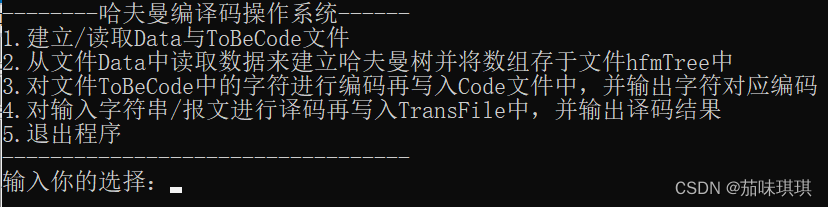
界面设计主要包括主菜单与子菜单。主菜单主要是对五个功能模块的展示,而子菜单则分别是由于用户选择输入Data的方式不同以及进行译码的数据不同而出现的,对应的就是操作一与操作四的子菜单。菜单如下所示:


五、程序设计
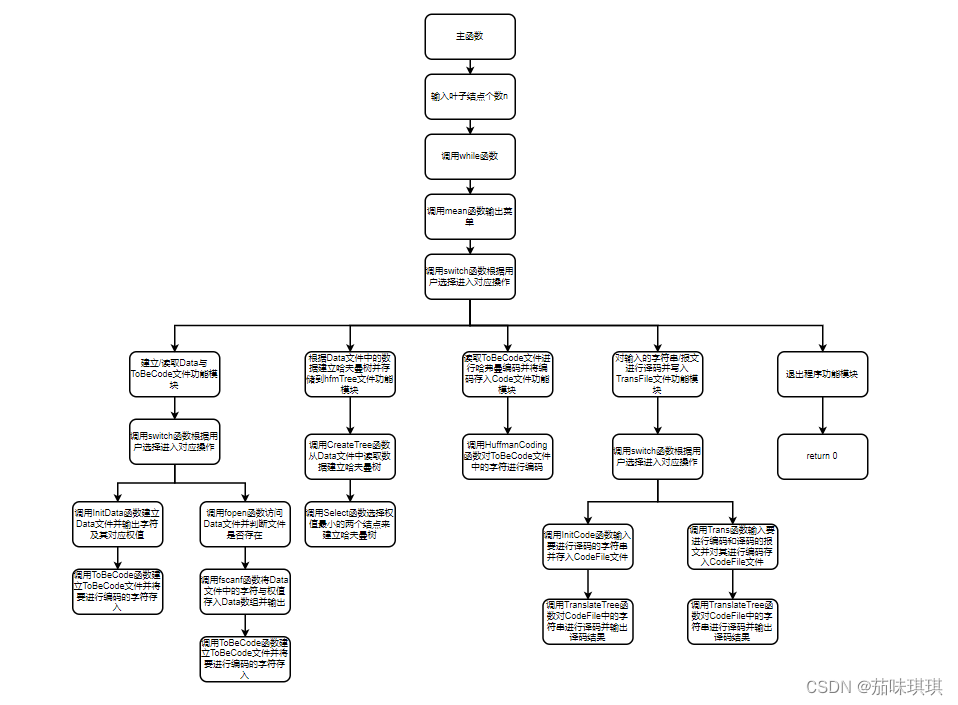
1、流程图/程序思想详细介绍:
①主程序的流程是首先让用户输入叶子结点个数之后调用while函数进入循环,接着调用mean函数输出主菜单,接着再根据用户的选择调用switch函数进入对应的功能模块。
②操作一为建立/读取Data和ToBeCode文件功能模块,拥有子菜单,让用户可以以两种途径去建立Data与ToBeCode文件,一比较适用于字符个数较少手动输入较快的情况,二比较适用于字符个数过多直接存入文件较快的情况。一主要通过调用InitCode函数去根据输入数据建立Data文件,在InitData函数里面又调用了InitToBeCode函数建立ToBeCode文件,并将要进行编码的字符存入文件;二主要是调用fopen和fscanf函数去打开文件,并将文件数据存入Data数组,接着调用InitToBeCode函数建立ToBeCode文件,并将要进行编码的字符存入文件。
③操作二为根据Data文件中的数据建立哈夫曼树并存储到hfmTree文件功能模块。首先调用CreateTree函数从Data文件中读取数据来建立哈夫曼树,在CreateTree函数里面又调用Select函数选择权值最小的两个结点来建立双亲结点。
④操作三为读取ToBeCode文件进行哈弗曼编码并将编码存入Code文件功能模块。主要是通过调用HuffmanCoding函数对ToBeCode文件中的字符进行编码并存入Code文件。
⑤操作四为对输入的字符串/报文进行译码并写入TransFile文件功能模块,拥有子菜单,用户可以选择操作一直接输入字符串存入CodeFile文件,也可以选择操作二输入报文对报文进行编码存入CodeFile文件,这个可以根据用户的需求自行选择。操作一是调用InitCode函数输入要进行译码的字符串并存入CodeFile文件,接着调用TranslateTree函数对CodeFile中的字符串进行译码并输出译码结果;操作二;是调用Trans函数输入要进行编码和译码的报文并对其进行编码存入CodeFile文件,接着调用TranslateTree函数对CodeFile中的字符串进行译码并输出译码结果。
⑥操作五为退出程序功能模块。通过return 0退出程序。
2、函数功能说明如下:
(1)选择无双亲且权值最小的两个结点以建立新结点函数:
//在HT[1...n]中选择无双亲即parent为0且权值最小的两个结点
void Select(HuffmanTree HT, int n, int& s1, int& s2)
{
//HT不进行改变故无需引用,s1,s2需要作为序号返回
int i=1,min=0;
//先找到第一个双亲为0的结点的权值暂时作为最小值与其他结点进行比较
for (i = 1; i <= n; i++)//时间复杂度O(n)
{
if (HT[i].parent == 0)
{
min = i;
break;
}
}
//将上个循环找到的暂时的最小值与每个结点的权值进行比较从而找出权值最小的结点
for (i = 1; i <= n; i++)//时间复杂度O(n)
{
if (HT[i].parent == 0)
{
if (HT[i].weight < HT[min].weight)
{
min = i;
}
}
}
s1 = min;//s1为权值最小的结点
//排除s1,寻找另一个权值最小的结点
for (i = 1; i <= n; i++)//同样寻找一个结点的权值作为比较
{
if ((HT[i].parent == 0) && (i != s1))
{
min = i;
break;
}
}
//将暂时的最小值与所有结点的权值进行比较,找出权值最小的结点
for (i = 1; i <= n; i++)
{
if ((HT[i].parent == 0) && (i != s1))
{
if (HT[i].weight < HT[min].weight)
{
min = i;
}
}
}
s2 = min;//s2为第二个权值最小的结点
}(2)建立并将要编码的字符出入ToBeCode文件函数:
void InitToBeCode(int n)
{
FILE* fp;
if ((fp = fopen("ToBeCode.txt", "w")) == NULL)
{
printf("文件打开失败\n");
exit(0);
}
for (int i = 0; i < n; i++)
{
//将n个字符的字符输送到存入文件
fprintf(fp, "%c", Data[i].c);
}
fprintf(fp, "#");
fclose(fp);
}(3)建立并输入字符与权值存入文件Data函数:
//初始化功能模块
//从键盘输入字符和权值到文件Data中并输出
void InitData(int n)
{
FILE* fp,*fp1;
//w--可读可写,打开一个文本文件,如果出错则会建立一个新文件
//如果原来已存在该命名文件则删去原来的文件重新建立一个文件
if ((fp = fopen("Data.txt", "w")) == NULL)
{
printf("文件打开失败\n");
exit(0);
}
printf("请依次输入字符及其权值:\n");
for (int i = 0; i < n; i++)
{
scanf("%c%d", &Data[i].c, &Data[i].weight);
}
for (int i = 0; i < n; i++)
{
//将n个字符的字符及其权值输送到存入文件
fprintf(fp, "%c%d", Data[i].c, Data[i].weight);
}
fprintf(fp, "#");
fclose(fp);
//输出字符及其对应权值
printf("各个字符及其对应的权值如下:\n");
for (int i = 0; i < n; i++)
{
printf("%c--%d\t", Data[i].c, Data[i].weight);
}
InitToBeCode(n);//创建ToBeCode文件存储要进行编码的字符
}(4) 创建CodeFile文件并将要进行译码的字符串存入文件函数:
//创建存放即将要进行译码的字符串
void InitCode(int n)
{
FILE* fp;
char s[50];
printf("请输入要进行译码的字符串:\n");
gets_s(s);
//w--可读可写,打开一个文本文件,如果出错则会建立一个新文件
//如果原来已存在该命名文件则删去原来的文件重新建立一个文件
if ((fp = fopen("CodeFile.txt", "w")) == NULL)
{
printf("文件打开失败\n");
exit(0);
}
fprintf(fp, "%s",s);
fprintf(fp, "#");
fclose(fp);
printf("\n");
}(5)初始化并建立哈夫曼树与hfmTree文件函数:
//初始化并建立哈夫曼树
void CreateTree(HuffmanTree& HT, int n)
{
FILE* fp;
if ((fp = fopen("Data.txt", "r")) == NULL)
{
printf("文件读取失败\n");
exit(0);
}
if (n < 1)//判断结点字符个数
exit(-1);
int m, i,s1,s2;
//已知字符均为叶子结点
//由二叉树的性质3:度为2的结点数+1=叶子节点数可得总结点个数
m = 2 * n - 1;
//申请m+1个结点的存储空间,其中0号单位不用
HT = (HuffmanTree)malloc((m + 1) * sizeof(HTNode));//空间复杂度为O(n)
//利用for循环将哈夫曼树中所有结点的权值、双亲和左右孩子赋值为0
for (i = 1; i <= m; i++)
{
HT[i].ch = 0;
HT[i].weight = 0;
HT[i].parent = 0;
HT[i].lchild = 0;
HT[i].rchild = 0;
}
//利用for循环从文件中读取数据为叶子结点赋权值和字符
for (i = 1; i <= n; i++)
{
fscanf(fp, "%c%d", &HT[i].ch, &HT[i].weight);
}
fclose(fp);
//建立哈夫曼树
for (i = n + 1; i <= m; i++)
{
Select(HT, i - 1, s1, s2);//在HT[1...i-1]中选择无双亲即parent为0且权值最小的两个结点
HT[s1].parent = i;//s1和s2结合,将i赋给它们的双亲域
HT[s2].parent = i;
HT[i].lchild = s1;//将s1与s2赋给i的左孩子域和右孩子域
HT[i].rchild = s2;
//i的权值等于左右两个孩子的权值相加
HT[i].weight = HT[s1].weight + HT[s2].weight;
}
FILE* fp1;
//w--只写,打开一个文本文件,如果出错则会建立一个新文件
if ((fp1 = fopen("hfmTree.txt", "w")) == NULL)
{
printf("文件打开失败\n");
exit(0);
}
//将这个结构体数组存于文件中
for (i = 1; i <=m; i++)
{
fprintf(fp1, "%c %d %d %d %d\n", HT[i].ch, HT[i].parent, HT[i].lchild, HT[i].rchild, HT[i].weight);
}
fclose(fp1);
}(6) 求对应字符的哈夫曼编码函数:
//求哈夫曼编码函数
void HuffmanCoding(HuffmanTree& HT, Huffmancode& HC, int n)
{ //HC实际为存储每个编码的头指针数组
//分配n个字符编码的头指针存储数组空间,0号单元不用
HC = (Huffmancode)malloc((n + 1) * sizeof(char*));//空间复杂度为O(n*n)
int i, start,c,f;
char* cd;//分配暂时存储求编码的工作空间
cd = (char*)malloc(n * sizeof(char));
cd[n - 1] = '\0';//编码结束符
printf("每个字符及其对应编码如下:\n");
for (i = 1; i <= n; i++)
{
//因为是从叶子结点逆序进行编码,所以start指向存储编码的结束符位置
start = n - 1;
//从叶子结点到根逆向求编码
f = HT[i].parent;
c = i;
while (f != 0)
{
--start;
if (HT[f].lchild == c)//如果目前结点是f的左孩子则编码为0
cd[start] = '0';
else//如果目前结点是f的右孩子则编码为1
cd[start] = '1';
//接着让c指向目前结点的双亲,f指向目前结点的双亲的双亲不断进行编码
//直至f=0即f指向根结点
c = f;
f = HT[f].parent;
}
//对每个叶子结点进行编码结束之后便 将对应的编码存储到HC中
//为第i个字符的编码分配空间
HC[i] = (char*)malloc((n - start) * sizeof(char));
strcpy(HC[i], &cd[start]);//从cd复制到HC
printf("%c--%s\t", HT[i].ch, HC[i]);//输出字符及其对应编码
}
free(cd);//释放暂时存储编码的工作空间
FILE* fp, * fp1;
//建立Code.txt文件用于存放字符与编码
if ((fp1 = fopen("Code.txt", "w")) == NULL)
{
printf("文件打开失败\n");
exit(0);
}
//判断ToBeCode.txt文件是否存在
if ((fp = fopen("ToBeCode.txt", "r")) == NULL)
{
printf("文件读取失败\n");
exit(0);
}
c = fgetc(fp);
while (c != '#')
{
for (i = 1; i <= n; i++)
{
if (c == HT[i].ch) //找到字符编号
//将对应的哈夫曼编码写入文件Code中
fprintf(fp1, "%s",HC[i]);
}
c = fgetc(fp);
}
fprintf(fp1, "#");
fclose(fp);
fclose(fp1);
}(7)译码函数:
//译码函数
//基本思想:从根出发,按字符'0'/'1'来寻找左孩子或者右孩子直至叶子结点
void TranslateTree(HuffmanTree HT, int n)
{
int m;
char b;
FILE* fp, * fp1,*fp2,*fp3;
//CodeFile.txt文件需要提前输入,也就是要进行译码的代码串
if ((fp = fopen("CodeFile.txt", "r")) == NULL)
{//打开文件只读
printf("文件打开失败\n");
exit(0);
}
//w--只写,打开一个文本文件,如果出错则会建立一个新文件
if ((fp1 = fopen("TransFile.txt", "w")) == NULL)
{//打开文件只写
printf("文件打开失败\n");
exit(0);
}
printf("字符串进行译码的结果为:\n");
b = fgetc(fp); //从文件中一个一个读取字符
m = 2 * n - 1;//初始化让m指向根结点,从根结点出发
while (b != '#')
{
if (b == '0')//如果为'0',则指向其左孩子
{
m = HT[m].lchild;
}
else if (b == '1')//如果为'1',则指向其右孩子
{
m = HT[m].rchild;
}
//一直到根结点则将该结点表示的字符存入文件中并让m重新指向根结点进行查找
if (HT[m].lchild == 0)
{
fprintf(fp1, "%c", HT[m].ch);
m = 2 * n - 1;
}
printf("%c", b);
b = fgetc(fp);//再读下一个字符
}
printf("——");
fprintf(fp1, "#"); //将‘#’写入文件
fclose(fp);
fclose(fp1);
if ((fp2 = fopen("TransFile.txt", "r")) == NULL)
{//打开文件只读
printf("文件打开失败\n");
exit(0);
}
char k = fgetc(fp2);
while (k != '#')
{
printf("%c", k);
k = fgetc(fp2);
}
printf("\n\n");
fclose(fp2);
}
(8) 对给定的报文进行编码函数:
//对给定的报文进行编码
void Trans(HuffmanTree HT, Huffmancode HC, int n)
{
FILE* fp;
int i,j;
char s[50];//存放报文
if ((fp = fopen("CodeFile.txt", "w")) == NULL)
{
printf("文件打开失败\n");
exit(0);
}
printf("请输入要进行编码的报文:\n");
gets_s(s);
//时间复杂度为O(len*n)
for (i = 0; s[i] != '\0'; i++)
{
for (j = 1; j <= n + 1; j++)
{
if (s[i] == HT[j].ch)
{
fprintf(fp, "%s", HC[j]);
}
}
}
fprintf(fp, "#");
fclose(fp);
printf("\n");
}(9)主菜单函数:
void mean()
{
printf("--------哈夫曼编译码操作系统------\n");
printf("1.建立/读取Data与ToBeCode文件\n");
printf("2.从文件Data中读取数据来建立哈夫曼树并将数组存于文件hfmTree中\n");
printf("3.对文件ToBeCode中的字符进行编码再写入Code文件中,并输出字符对应编码\n");
printf("4.对输入字符串/报文进行译码再写入TransFile中,并输出译码结果\n");
printf("5.退出程序\n");
printf("----------------------------------\n");
printf("输入你的选择:");
}六、运行与测试
1、课设要求
(1)利用下列数据调试程序:令叶子结点个数n为4,权值集合为{1,3,5,7},字符集合为{A,B,C,D},并有如下对应关系,A——1、B——3、C——5、D——7,调用初始化功能模块可以正确接收这些数据;调用建立哈夫曼树的功能模块,构造静态链表HuffNode的存储;调用建立哈夫曼编码的功能模块,在屏幕上显示如下对应关系:A——111、B——110、C——10、D——0;调用译码的功能模块,输入代码串“111110100”后,屏幕上显示译码结果:111110100——ABCD
(2)用下表给出的字符集和频度的实际统计数据建立哈夫曼树,并实现以下报文的编码和译码:“THE PROGRAM IS MY FAVORITE”。
| 字符 | A | B | C | D | E | F | G | H | I | J | K | L | M | |
| 频度 | 186 | 64 | 13 | 22 | 32 | 103 | 21 | 15 | 47 | 57 | 1 | 5 | 32 | 20 |
| 字符 | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | |
| 频度 | 57 | 63 | 15 | 1 | 48 | 51 | 80 | 23 | 8 | 18 | 1 | 16 | 1 |
2、具体实现:
(1)测试的数据及其结果:
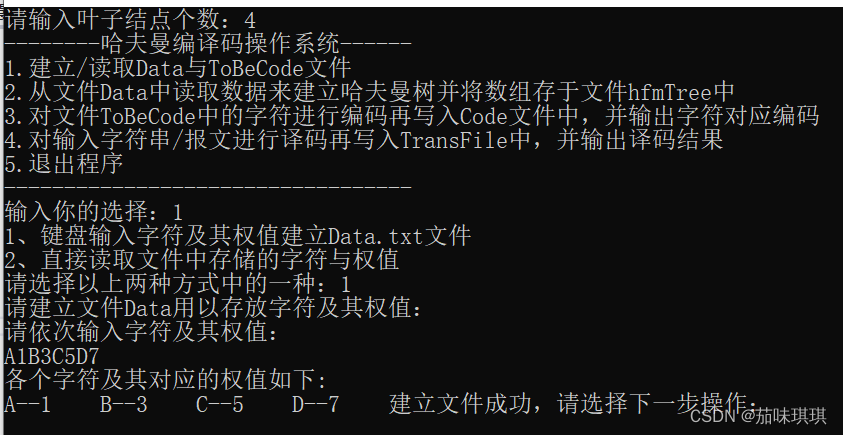
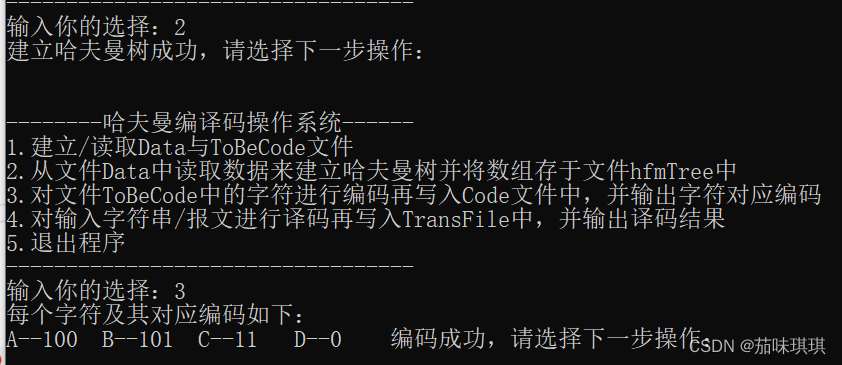
(一)结点个数n=4,字符及其权值A-1,B-3,C-5,D-7,译码字符串:100101110,结果如下:
 (二)结点个数与字符及其权值与(一)相同,译码报文为:ACDBDBCA,结果如下:
(二)结点个数与字符及其权值与(一)相同,译码报文为:ACDBDBCA,结果如下:

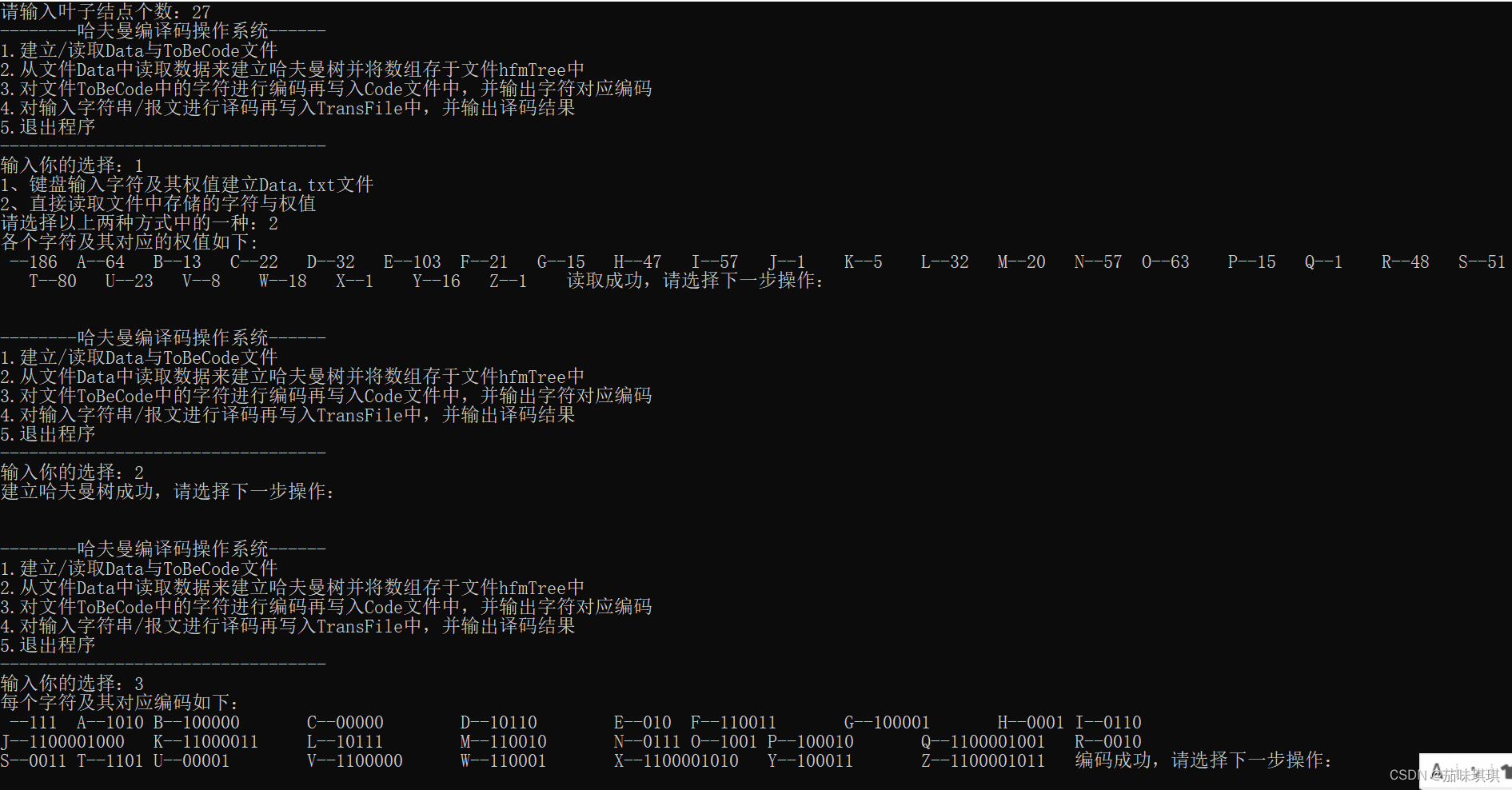
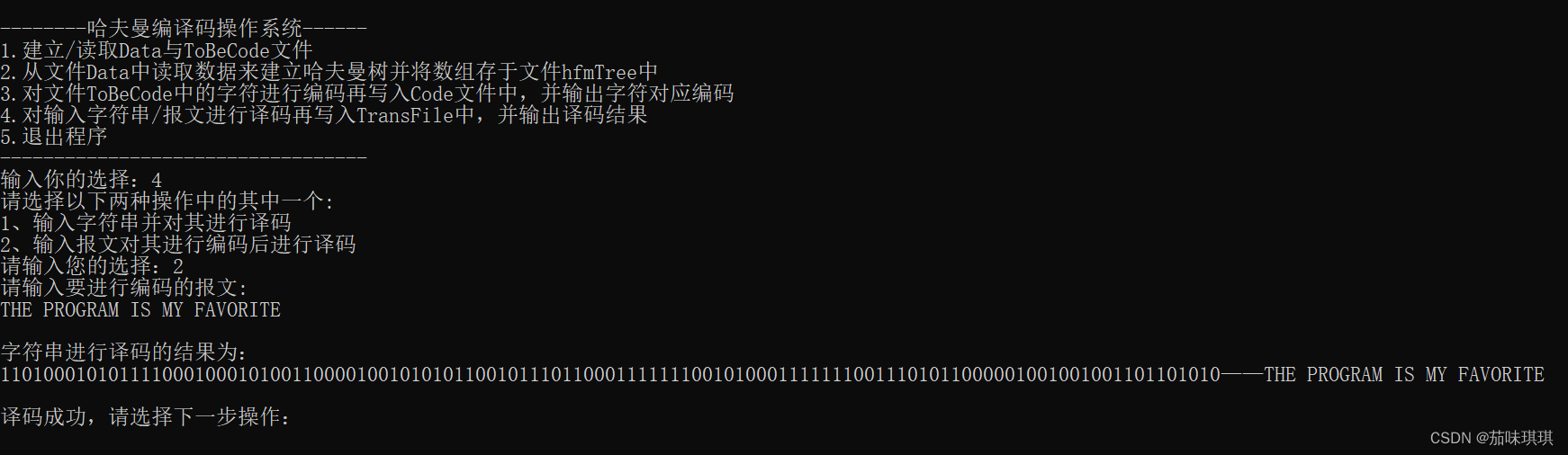
(三)结点个数n=27,字符及其权值为-186,A-64,B-13,C-22,D-32,E-103,F-21,G-15,H-47,I-57,J-1,K-5,L-32,M-20,N-57,O-63,P-15,Q-1,R-48,S-51,T-80,U-23,V-8,W-18,X-1,Y-16,Z-1,译码报文:THE PROGRAM IS MY FAVORITE,结果如下:
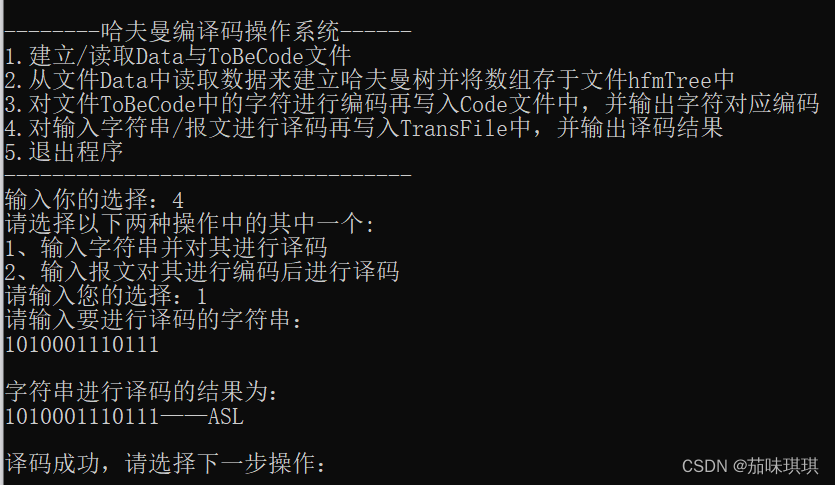
 (四)结点个数与字符及其权值与(二)相同,译码字符串为1010001110111,结果如下:
(四)结点个数与字符及其权值与(二)相同,译码字符串为1010001110111,结果如下:
(2)程序的空间复杂度与时间复杂度分析:
空间复杂度为O(n)
当要进行译码的是报文时,时间复杂度为O(len*n),其中len为报文的长度;当要进行译码的是字符串时,时间复杂度为O(n)。
七、编写代码及运行时遇到的问题及解决方法
1、编写代码期间遇到的问题及其解决办法
问题(一):定义Data数组中的权值域时定义类型先为字符数组char[50],因此导致空间复杂度高了一些以及字符数组在输入的时候很容易受到回车键/空格的影响。
解决方法:先是将50改成了10,最后为了更加适用,改成了int类型。
问题(二):在写入文件的时候,运用fwrite/fprintf这两个函数的时候,不明确两者的区别,所以随意选择而导致在人工检查生成文件内的数据的时候有些文件内容为乱码,因而无法判断。
解决方法:弄清楚fprintf是将格式化的数据写入文件,文件中的数据计算机与人都可读;fwrite是以二进制内容写入文件,除非数据能够表示为字符,不然计算机可读,人工不可读。为了方便检验,统一使用fprintf函数写入文件。
问题(三):在运用scanf输入字符及其权值或者字符串与报文时,在定义格式类型时不够统一,使得用户在输入的时候很容易出错。
解决方法:输入字符与权值时统一“%c%d”的形式,而输入字符串与报文则利用gets函数读取。
问题(四):输出字符及其对应权值或编码时如何进行输出,存入文件后再读取文件存入数组再输出的话不仅显得很复杂。
解决方法:字符及其权值存放于Data数组,因而直接输出数组数据就可以,而输出字符及其编码时则输出哈夫曼树HT中结点的字符及对应HC中的编码。但同时可能需要人工检查写入文件中的数据是否正确。
问题(五):将哈夫曼树存入hfmTree文件如何操作。
解决方法:调用fprintf函数,用for循环依次存入。
2、运行与测试期间遇到的问题及其解决办法
问题(一):利用fwrite函数将数据写入文件时打开文件检查出现乱码以及不匹配的情况。
解决方法:均利用fprintf函数将数据写入,以进行人工核对数据,注意输入数据的格式,避免多加空格使得数据不对。
问题(二):在输入较多字符及其权值时手动输入很容易出错而导致结果出错以及无法将空格字符存入。
解决方法:提前建立一个数据文件,将要进行输入的较多字符提前存储到其中,在用到时从数据文件中复制并存入Data文件中以减少出错的可能并且提高效率。
问题(三):由于需要用户多次输入自己的选择,而每一个选择对应的下一步如果要输入数据一般都为字符型,因而很容易将回车吃进入导致数据存储失败从而导致哈夫曼树建立失败。
解决方法:对每一个scanf后面的操作进行考虑,如果接下来涉及到字符型数据输入则加一个getchar读取回车键,以防止其影响数据输入。
问题(四):由于手动输入空格字符作为结点时输入失败但未察觉而导致输入“THE PROGRAM IS MY FAVORITE”时输出结果为分段的字符串,与实际要求输出结果不同。
解决方法:问题出现在输入字符及其权值时,未按照规定的形式输入数据,即未选择合适记忆并且普遍使用的输入格式,规定好输入字符及其权值以%c%d的形式输入。
问题(五):在对输入的报文进行编码时,查找存储编码的指针数组HC时,无法转化成对应的编码字符串。
解决方法:惯性思维认为i,j都是从0开始,但是在HC数组中0号单元不存储编码,将j的初始值改成1即可。
















 2491
2491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











