







摘 要:利用粘连字符分割和句法识别的方法,对人民币纸币图像进行识别。经试验证明,该方法能正确识别纸币面值,同时对票面的污迹等噪声的抑制有很好的效果。
关键词:纸币面值识别;粘连字符分割;句法识别;Levenshtein 距离
随着科技的发展,很多行业都出现了基于人民币纸币识别技术的智能化无人收费系统, 节省了大量的人力资源。人民币纸币的识别技术不仅可以应用在自动售货售票上,也可以应用到银行的自动存取款机,手机营业厅的自动交费机等。
目前已有的识别方法主要是利用统计方法进行识别,如尺寸比较法、模板匹配、人工神 经网络等。人民币纸币在流通中不可避免的会沾染污迹或磨损。这些方法虽然能快速识别出纸币的面值,但纸币上的微小污迹或其他图像 噪声对识别结果影响很大,甚至出现无法识别 或错误识别的现象。
为此提出以提高识别准确率为目的的识别方法,使用粘连字符分割和句法识别的方法 来识别纸币的面值。
1 面向识别
要进行人民币纸币面值识别,首先要确定人民币纸币的面向。只有确定出面向,才能准确 定位纸币要识别的特征区域。面向可分为:正面 正向、正面倒向、反面正向和反面倒向。在进行 识别前应先进行预处理,如倾斜校正、滤波等处 理。

在面向识别中,采用目前常用的方法[4],即根据灰度来确定。这种方法识别速度快,准确率 高。对纸币图像分割成 9 块区域,进根据每一块的灰度进行比较,可以得出纸币的面向。
迹或磨损,如果面值数字上沾染上污迹,那么现 有的识别方法对污迹并没有太理想的解决办法。如模板匹配方法,阈值的设定将直接影响到 识别的结果。利用人工神经网络的方法[3]识别面 值,对有污迹的纸币识别效果也不是很理想而 且网络不容易收敛,运算量过大。而利用灰度投影方法[7],识别结果受噪声影响比较大。人民币纸币识别对准确率要求很高,识别算法应在保 证高识别率的基础上尽可能的提高识别速度。 提出的识别方法将粘连字符分割应用到纸币识 别中并采用句法方法进行识别,这种方法受纸 币的污迹影响很小,即使有一些微小磨损或污迹也能准确识别。
- 字符提取及分割
以 50 元面值的人民币为例,对数字 50 定
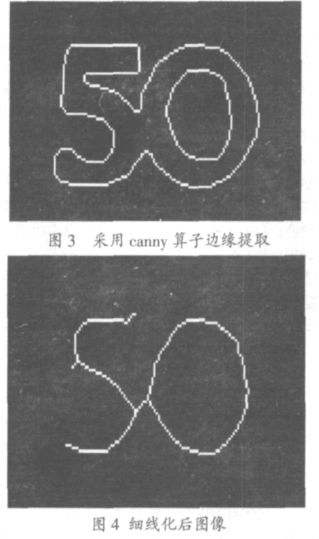
位后需要将两个字符分割开,而 5 和 0 连接的很紧密,粘连在一起,直接分割将损害字符的完 整。因此需要使用特殊的处理算法。先将数字字符滤波并进行边缘提取,经反复试验比较,can- ny 算子的效果较好,如图 3。得到 50 的空心字符,充填后进行细线化,得到图 4。
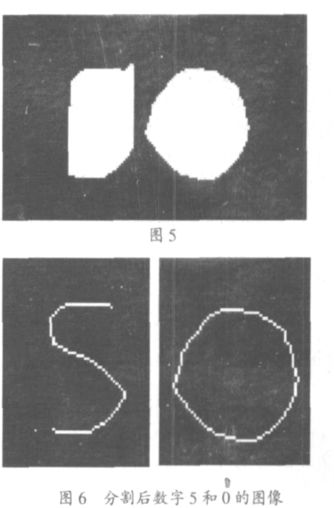
此时字符图像已经分离,可以轻易的将字符分割开。分割后也可以做一下简单的去毛刺 处理。如图 6 所示,是被分割出来的字符 5 和0。对字符的识别,这里采用句法识别的方法。
-
- 字符的识别
将字符图像分割成 4 个象限,如图 7,按几何的方法对象限排序,即右上角为第一象限,左上角为第二象限,左下角为第三象限,右下角为第四象限。之后判断每个象限的笔画。根据笔画的不同,列出代表笔画特征的表格,如图 8,可以得出

句法描述格式为:是否空心;第一象限笔画;第 2 象限笔画;第 3 象限笔画;第四象限笔画。
以 50 元人民币纸币为例,图 1 和图 2 分别为正面和反面灰度化后的图像,两图 A、B 两个特征区域位置排列和灰度有明显差别,据此可以判断出纸币的面向。

图 1 正面纸币图像
图 2 反面纸币图像
- 面值识别
目前已有的识别方法主要是识别面值数字,人民币纸币在流通中不可避免的会沾染污。此时字符依然是粘连的。在二值图像中, 白色像素点的值为 1,黑色像素点值为 0。对图像每一列找出最上端为 1 的点和最下端为 1 的点,行数相减,得到差值 K。

图 3 采用canny 算子边缘提取
图 4 细线化后图像
最上端为 1 的点为f(i1,j1),最下端为 1 的点为f(i2,j2),K=i2- i1。
然后从 f(i1,j1)开始向下,把到 f(i1+K- 1,j1)之间的点的值都改为 1,如图 5
数字 0 可以描述为:19876; 数字 1 可以描述为:03333; 数字 2 可以描述为 :05842;数字 5 可以描述为:02425;
对要识别的数字,将其描述出来的字符串进行匹配识别。对字符串进行匹配,就是对两个分别具有 m 和 n 个符号的字符串 X 和 Y,衡量他们之间的相似度,具体定义为:将字符串 X 变换成Y 需要的字母编辑次数。有三种编辑方法:代替、插入和删除。将描述要识别的数字的字符串设为X,需要匹配的模板字符串为 Y。采用 Levenshtein 距离算法,以矩阵的形式给出将X 变成 Y 的所有可能编辑的操作,然后根据这个矩阵算出最终结果。在中设矩阵 D(i,j),任何一个从 D(0,0)到 D(5,5)的路径,都表示了一个将 X 转变成 Y 的编辑操作序列。从 D(0,0)开始,算法逐步填充整个矩阵,具体公式如下所示。最小的D1,D2 和D3 被赋值到 D(i,j)中。
D1=D(i,j- 1)+c(λ→a) 2.1
D2=D(i- 1,j) + c(λ→a) 2.2
D3=D(i- 1,j- 1)+ c(λ→a) 2.3
如 0 与 5 的字符串相匹配, 得到矩阵如下表,可以得出 Levenshtein 距离为 4。
表 1
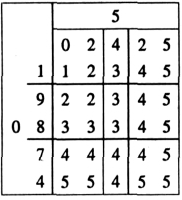
将表述要被识别的字符的字符串 X 与其他模板字符串依次匹配,算出 Levenshtein 距离,距离最小的,就是符合匹配的字符。
- 试验结果
通过扫描仪扫描的不同面值纸币图像共200 张,包括第五版及新第五版人民币纸币的正面和反面图像,其中绝大多数是流通时间较长的纸币。在 MATLAB 7.0 中仿真,对纸币图像
进行识别。其中正确识别 199 张,错误识别 1 张。错误的原因是该纸币破损和污迹比较大,已 经影响到正常的流通。试验中对可以正常流通 的纸币,即使有一些小的污迹和破损,也能正确 的识别。
- 结论
提出的识别方法能很好的克服字符上有污迹影响识别率的问题,同时也很好的解决了字符粘连而无法分割的问题。如字符上沾有污迹, 在细线化处理的时候可以很好的弱化污迹带来的影响,在用句法方法进行识别的时候可以尽可能的排除污迹的影响,达到准确识别的目的。 提出的方法把统计识别和句法识别方法相结合,实验结果表明,在该方法下对不同面值的纸币进行识别,识别率可以达到 99%以上,因此该方法有很好的实用性。
参考文献
- 范立南,韩晓微,张广渊.图像处理与模式识别[M].北京:科学出版社,2007,3.
- [ 美]Rafael C Gonzalez, Richard E Woods, Steven L Eddins. 阮秋琦译. 数字图像处理(MATLAB 版)[M].北京: 电子工业出版社, 2005. [3]杜选,高明峰.人工神经网络在数字识别中的
应用[J].计算机系统与应用,2007, (2):21-27.
- 陈慧鹏,杨亮亮,李鸿.模糊集识别法在纸币清分中的应用研究[J].华中科技大学国家数控工程中心,2004.
- 宋铭利.关于去除图像噪音的中值滤波算法
[J].洛阳师范学院院报,2012(5):67-69.
- 韩贺磊.人民币纸币面额的机器视觉识别方法研究[D].大连理工大学,2017.
- 张国华.一种基于模板匹配的人民币纸币面额识别方法 [J].沈阳工业大学学报,2015.














 2692
2692











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









