






想要完成一个scrapy爬虫框架,那首先得明确自己想要爬取的东西是什么,要选择什么样的爬取方法。接下来我就讲一下我使用Scrapy框架爬取慕课网的一些思路以及过程。
思路:(1)打开慕课网址,并分析网站;
(2)创建Scrapy;
(3)设置爬虫文件;
(4)爬取慕课网址;
(5)保存数据。
过程:
1、打开浏览器,输入网站地址:
https://coding.imooc.com/
2、分析页面。右键点击“检查”,查看网页元素,这里阿彬就爬取书本的名字和图片的地址。
3、创建项目。输入命令 scrapy startproject wl,创建一个名叫wl的爬虫项目。
4、进入项目,到wl项目中进入原有的spiders文件中,创建自定义的爬虫文件;命令为:scrapy genspider whh(爬虫文件名字) 爬取网页的网址。
5、接下来呢得修改爬虫项目中的setting文件。
把君子协议原本是True改为False。
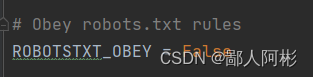
再把这行原本被注释掉的代码把它打开。

6、进入items文件进行定义爬取字段,代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class WlItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field() # 爬取该书本的名称
img = scrapy.Field() # 爬取该书本的图片
7、编辑whh.py文件,使用xpath方法爬取网页,代码如下:
import scrapy
from ..items import WlItem
class WhhSpider(scrapy.Spider):
name = 'whh'
allowed_domains = ['https://coding.imooc.com/']
start_urls = ['https://coding.imooc.com/']
def parse(self, response):
whh = response.xpath('//ul[@class="course-list clearfix"]/li/a')
for i in whh:
name = i.xpath('./p[1]/text()').extract()
img = i.xpath('./div/@style').extract()
for a in img:
src = 'http:' + a[22:-1]
print(name, src)
data = WlItem(name=name, img=src)
yield data
8、在pycharm工具的终端执行命令“scrapy crawl whh ”,运行结果如下图所示:

9、使用CSV格式保存数据只需执行命令“scrapy crawl whh -o data.csv”,结果如下图所示:

好了,一个简单的scrapy爬虫框架就做好了。感谢各位博主收看。
















 2653
2653











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











