






 京东商品主图无法直接保存或截图无水印,但可通过使用下图高手软件进行批量下载。只需简单几步:进入商品页面,复制链接到软件,勾选下载主图,设置保存位置,即可获取高清原图。
京东商品主图无法直接保存或截图无水印,但可通过使用下图高手软件进行批量下载。只需简单几步:进入商品页面,复制链接到软件,勾选下载主图,设置保存位置,即可获取高清原图。
京东上的产品主图,直接下载或是截图,要么会出现水印要么像素不够,达不到我们的要求。但是,现在发现窍门,简单的那么几个步骤就能下载到京东产品主图的原图、大图哦!咱们一起开始用下图高手批量下载京东商城的产品图片叭。
打开京东,点一个类目

单击一个商品进入页面
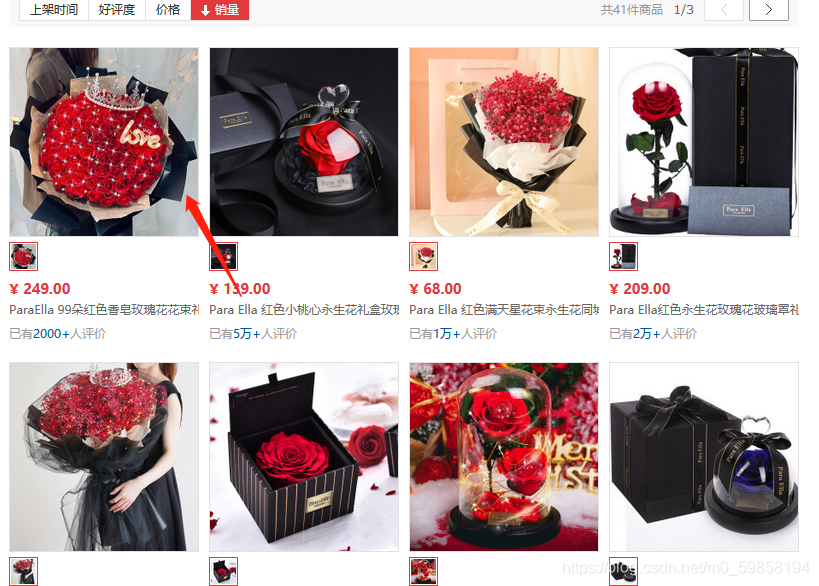
把鼠标放在主图上显示出网格,右键单击并没有保存图片的按钮,说明京东图片无法直接保存到电脑上
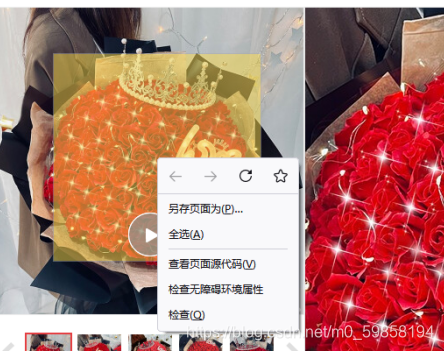
下载一个下图高手把商品链接复制到软件上
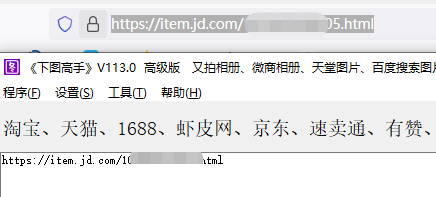
把“自动粘贴网址”打勾,可一行复制一个链接

接着把“下载主图”打勾,其他的选项任意

点“浏览”设置好商品下载后所保存的位置

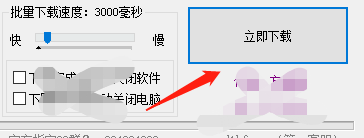
确定全部设置好后,单击立即下载
进度条滚动完成,打开文件夹浏览
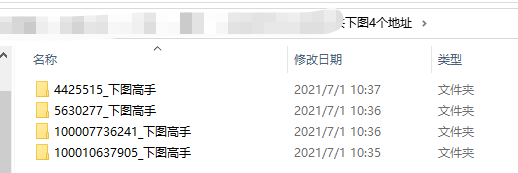
任意双击一个商品进去,都可看到所下载的主图图片
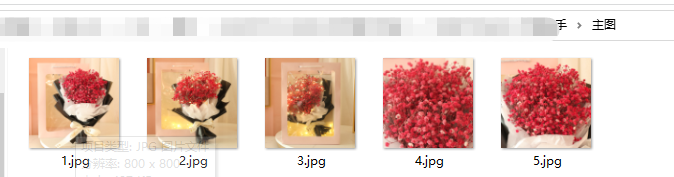
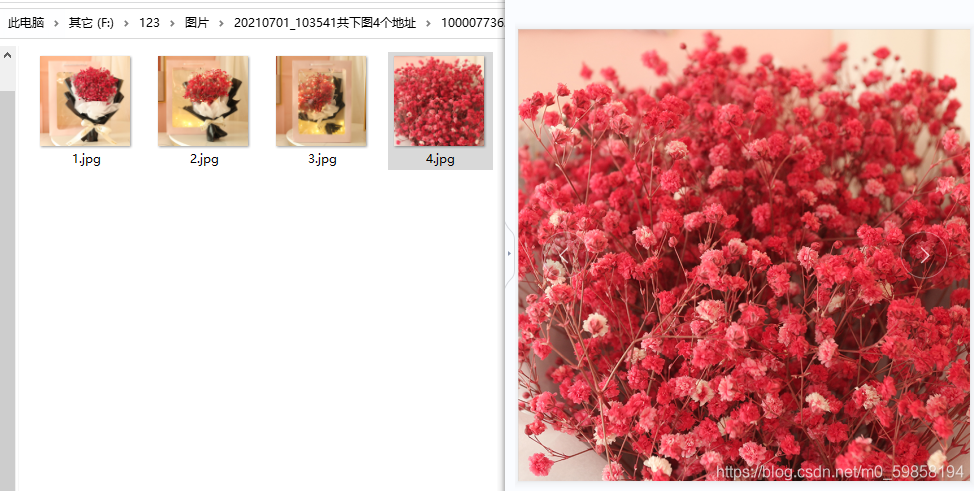
双击一张主图,是高清原图

















 1723
1723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









