







目录
1.2 安装 Hadoop 前的准备工作(如果网络没问题就很简单)
1.1创建Hadoop 用户(简单)

1.2 安装 Hadoop 前的准备工作(如果网络没问题就很简单)
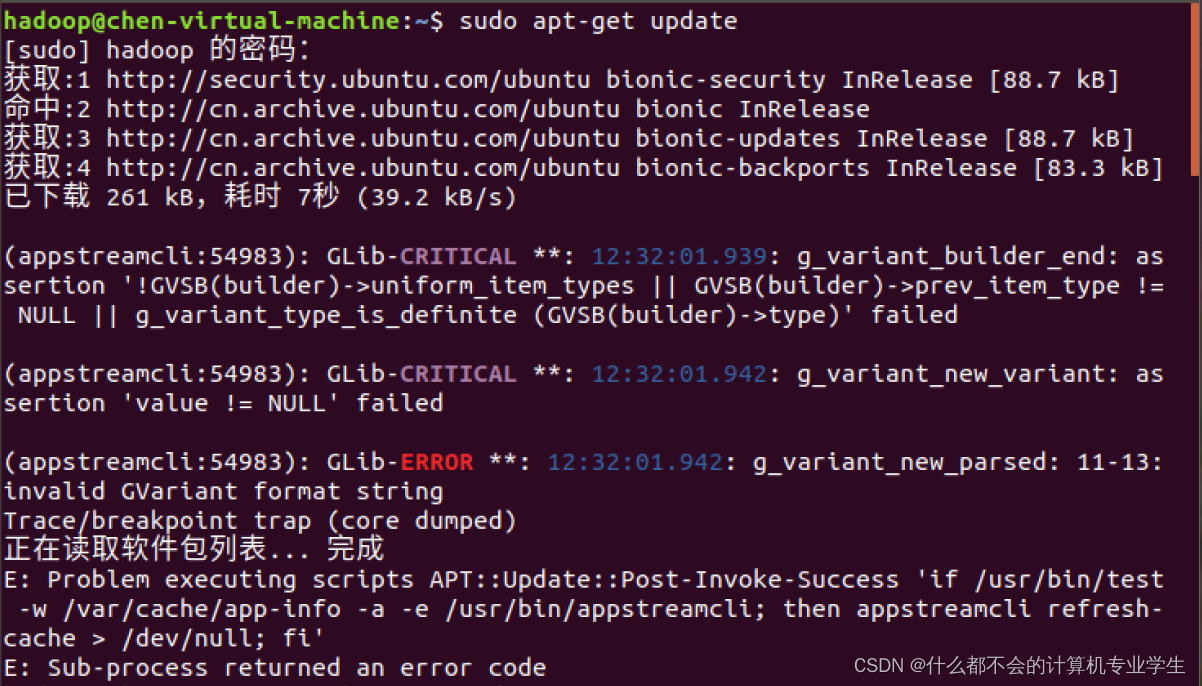
1.2.1 更新 APT
需要输入登录hadoop账户的密码,1.1中设置的
1.2.2 安装vim编辑器

1.2.3安装 SSH
$ sudo apt-get install openssh-server #安装SSH服务端

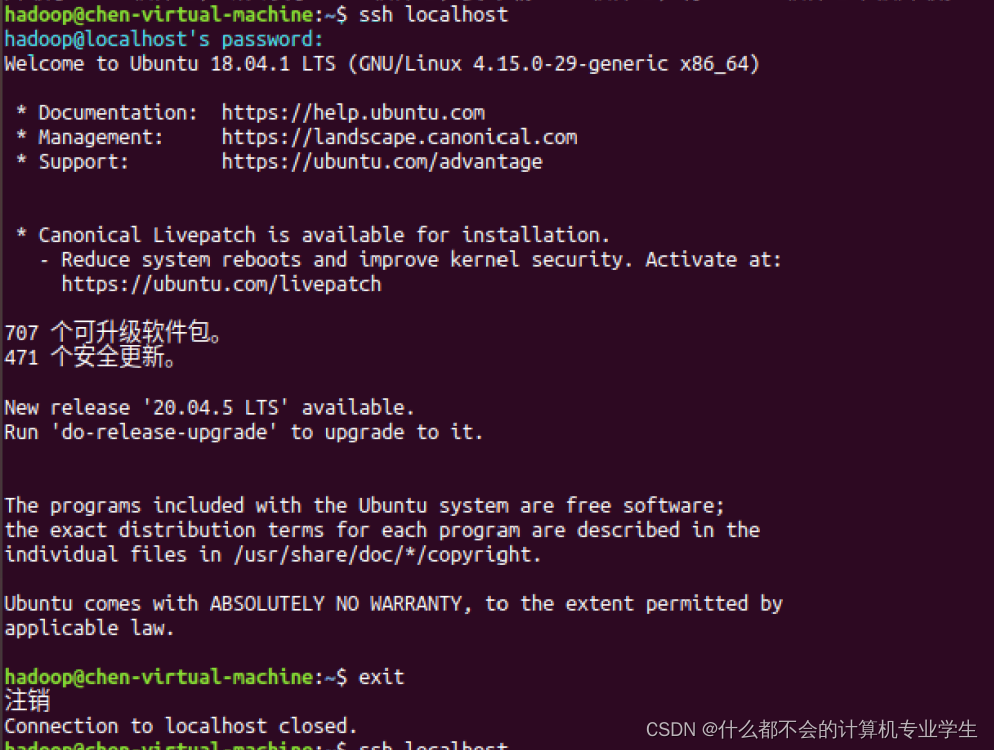
安装后,可以使用如下命令登录本机:
$ ssh localhost #登录需要密码,exit退出登录
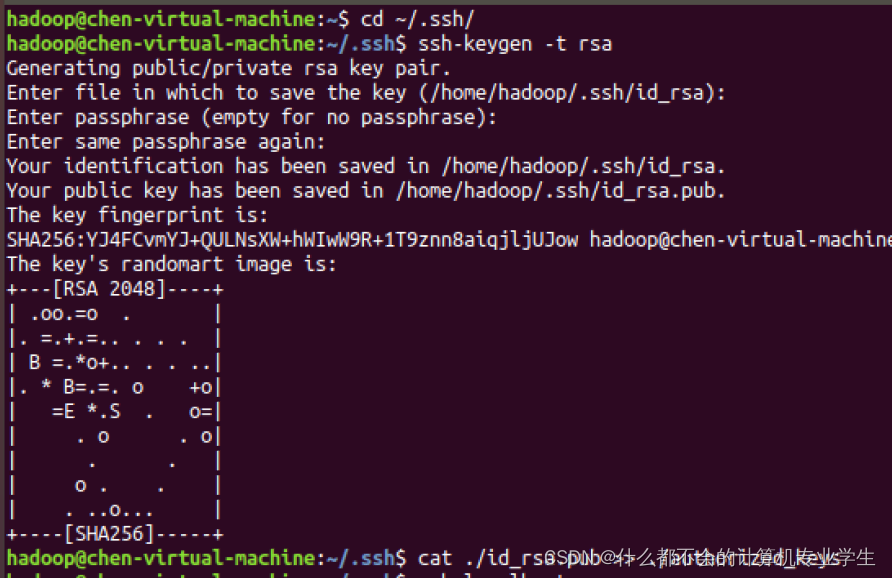
免密登录:利用ssh-keygen生成密钥,并将密钥加入到授权中,命令如下:
$exit
$ cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
$ ssh-keygen -t rsa # 会有提示,都按回车即可(:后边都敲回车)
$ cat ./id_rsa.pub >> ./authorized_keys # 加入授权
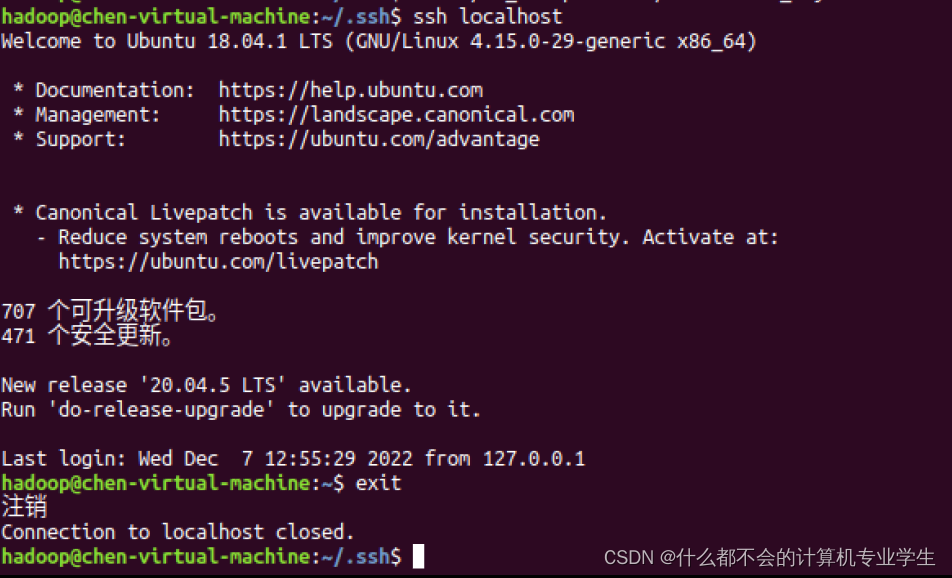
此时,再执行ssh localhost命令,无需输入密码就可以直接登录了。
1.3 安装 Java 环境
执行如下命令创建/usr/lib/jvm目录用来存放JDK文件:
$ cd /usr/lib
$ sudo mkdir jvm #创建/usr/lib/jvm目录用来存放JDK文件

执行如下命令对安装文件进行解压缩:(提前设置好共享文件夹或者设置双向粘贴,直接把压缩包粘到Ubuntu中)
我也有总结---原文链接:https://blog.csdn.net/m0_59865073/article/details/128192013
$ cd ~ #进入stu用户的主目录
$ cd Downloads #切换到压缩包所在目录
$ sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm
以上两步操作的代码运行截图:(挂载共享文件夹)
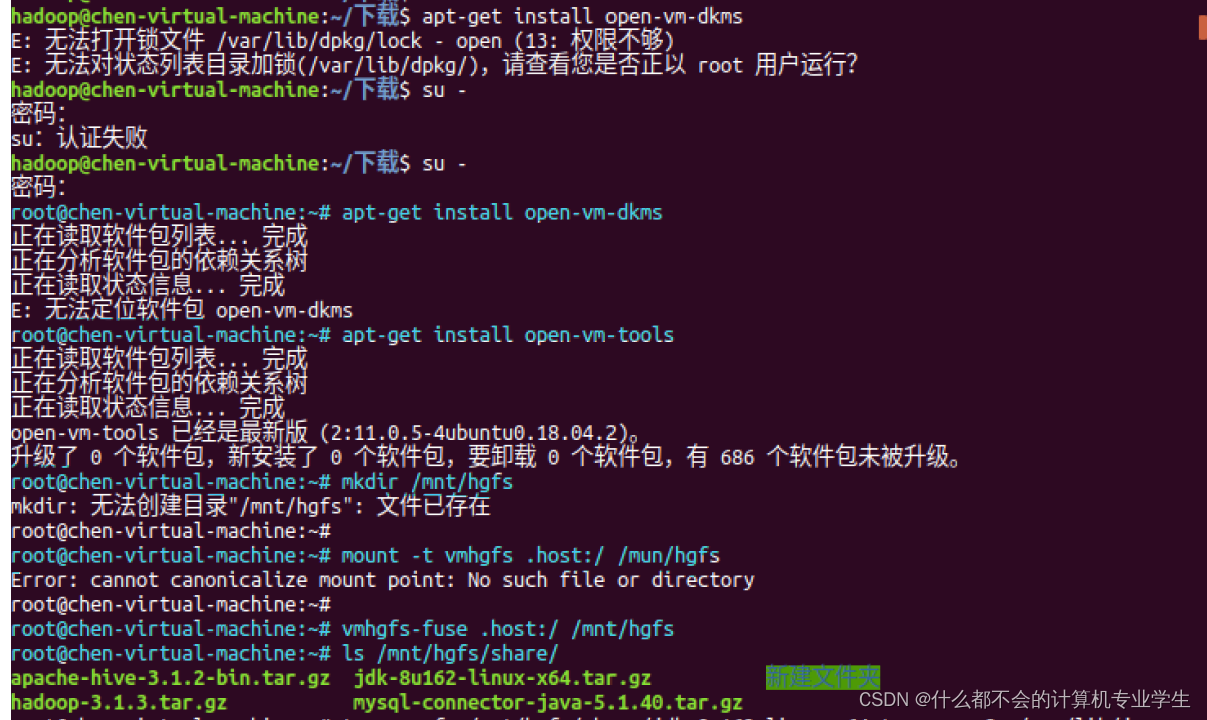
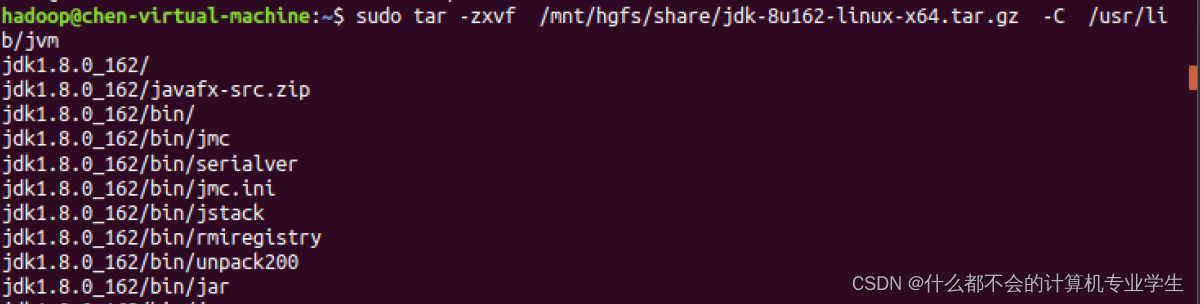
下面继续执行如下命令,设置环境变量:
$ vim ~/.bashrc
如果vim使用不熟悉,同学们可以使用gedit
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4286
4286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









