







1、 获取一个wrfout文件(可为多个)多个站点的的2m气温、2m比湿、地面压力、10mU风、10mV风
;----------------------------------------------------------------------
; write_csv_5.ncl
;
; Concepts illustrated:
; - Writing a CSV file with a header using write_table
; - Appending data of mixed types to a CSV file inside a loop
; - Writing select WRF-ARW data to a CSV file
;----------------------------------------------------------------------
; This example calculates temperature at 2m from a WRF-ARW output
; file, and writes a subset of the data based on an array of
; lat / lon values.
;----------------------------------------------------------------------
; These files are loaded by default in NCL V6.4.0 and newer
load "$NCARG_ROOT/lib/ncarg/nclscripts/csm/gsn_code.ncl"
load "$NCARG_ROOT/lib/ncarg/nclscripts/csm/gsn_csm.ncl"
load "$NCARG_ROOT/lib/ncarg/nclscripts/wrf/WRFUserARW.ncl"
begin
dir = "./"
files = systemfunc("ls -1 " + dir + "bei*")
a = addfiles(files+".nc","r")
times = wrf_user_list_times(a) ; "2008-09-29_18:30:00", etc
tk2 = wrf_user_getvar(a,"T2",-1) ; T2 in Kelvin
q2 = wrf_user_getvar(a,"Q2",-1) ; Specific humidity at 2m in kg/kg
psfc = wrf_user_getvar(a,"PSFC",-1) ; Surface pressure in Pascals
u10 = wrf_user_getvar(a,"U10",-1) ; 10m height U wind component in m/s
v10 = wrf_user_getvar(a,"V10",-1) ; 10m height V wind component in m/s
times = wrf_user_list_times(a)
ntimes = dimsizes(times)
print("ntimes = " + ntimes)
lats = (/30.627, 30.505, 30.637, 30.611, 30.548, 30.541, 30.560, 30.574, 30.506, 30.578, 30.466, 30.573, 30.478, 30.557, 30.562, 30.676, 30.579, 30.602, 30.583, 30.485, 30.534, 30.526, 30.514, 30.338/)
lons = (/114.382, 114.333, 114.287, 114.279, 114.517, 114.296, 114.308, 114.198, 114.480, 114.271, 114.288, 114.243, 114.343, 114.337, 114.278, 114.411, 114.454, 114.348, 114.338, 114.275, 114.319, 114.249, 114.365, 114.280/)
nlatlon = dimsizes(lats)
loc = wrf_user_ll_to_xy(a, lons, lats, True) ; 2 x nlatnlon
csv_filename = "wrf_t2_q2_p_u10_v10.csv"
system("rm -f " + csv_filename) ; Remove file in case it exists.
fields = (/"TIME", "LAT", "LON", "T2", "Q2", "PSFC", "U10", "V10"/)
dq = str_get_dq()
fields = dq + fields + dq ; Pre/append quotes to field names
header = [/str_join(fields,",")/] ; Header is field names separated by commas.
format = "%s,%6.2f,%7.2f,%6.2f,%6.3f,%8.2f,%6.2f,%6.2f"
write_table(csv_filename, "w", header, "%s") ; Write header to CSV file.
do it = 0,ntimes-1
do nl = 0,nlatlon-1
nln = loc(0,nl)
nlt = loc(1,nl)
lat1 = a[0]->XLAT(0,nlt,nln) ; nearest grid point
lon1 = a[0]->XLONG(0,nlt,nln)
alist = [/times(it), lat1, lon1, (tk2(it,nlt,nln)-273.15), q2(it,nlt,nln), psfc(it,nlt,nln),u10(it,nlt,nln), v10(it,nlt,nln)/]
write_table(csv_filename, "a", alist, format) ; Write list to CSV file.
end do
end do
end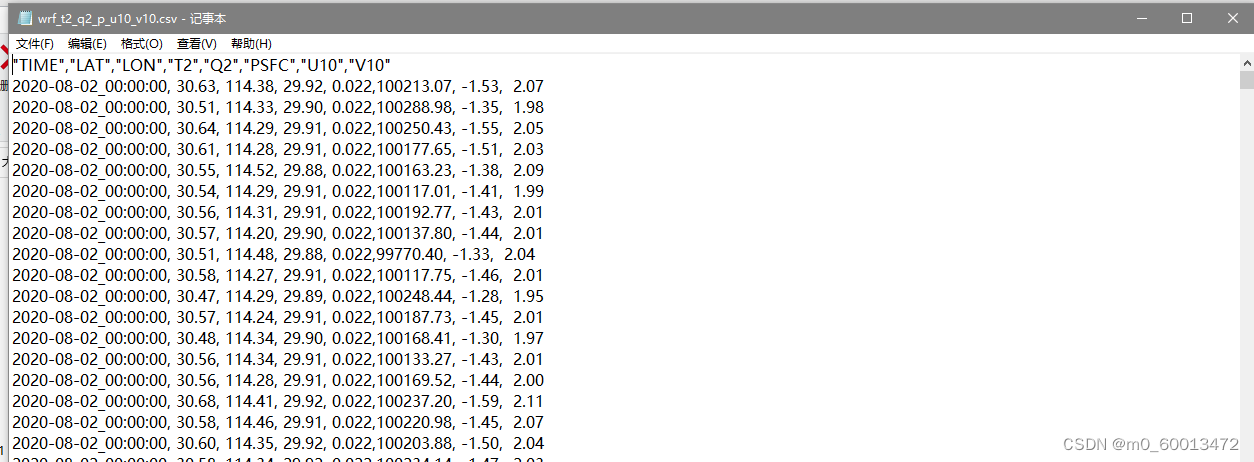
2、对气象站数据建立经度与街道名称的映射关系,根据气象站点与经度的映射关系在ncl导出的csv数据添加街道名称列
import csv
# 第一段代码:创建一个字典来存储经度到街道名称的映射
new_csv_file_path = 'J:/工作室/大论文/WRF/validation/临时验证/站点位置.csv'
lon_to_street = {}
try:
with open(new_csv_file_path, mode='r', encoding='utf-8') as file:
reader = csv.reader(file)
headers = next(reader) # 读取标题行
lon_index = headers.index('LON') # 获取经度列的索引
street_index = headers.index('街道名称') # 获取街道名称列的索引
for row in reader:
lon = float(row[lon_index]) # 通过索引获取经度并转换为浮点数
street_name = row[street_index] # 通过索引获取街道名称
lon_to_street[lon] = street_name # 创建映射
except Exception as e:
print(f"读取CSV文件时发生错误: {e}")
# 打印出建立的索引关系(即字典内容)
print("经度到街道名称的映射关系:")
for lon, street_name in lon_to_street.items():
print(f"经度 {lon} 对应的街道名称是: {street_name}")
# 第二段代码:读取旧CSV文件并在每行数据的最后新增街道名称列
old_csv_file_path = 'J:/工作室/大论文/WRF/validation/临时验证/beijing.csv'
new_csv_file_path = 'J:/工作室/大论文/WRF/validation/临时验证/updated_beijing.csv'
try:
with open(old_csv_file_path, mode='r', encoding='utf-8') as old_file, \
open(new_csv_file_path, mode='w', encoding='utf-8', newline='') as new_file:
reader = csv.reader(old_file)
writer = csv.writer(new_file)
# 读取标题行并在最后新增 "街道名称" 列标题
header = next(reader)
header.append('街道名称')
writer.writerow(header)
# 遍历旧文件中的每一行数据
for row in reader:
# 假设LON值在第三列
lon_str = row[2]
try:
# 尝试将LON值转换为浮点数
lon = float(lon_str)
# 使用映射查找街道名称
street_name = lon_to_street.get(lon, "未知街道")
# 将街道名称添加到行的最后
row.append(street_name)
except ValueError:
# 如果转换失败(数据不是数字),则添加 "未知街道"
row.append("未知街道")
# 写入新文件
writer.writerow(row)
except Exception as e:
print(f"发生错误: {e}")
print("更新完成,结果保存在:", new_csv_file_path)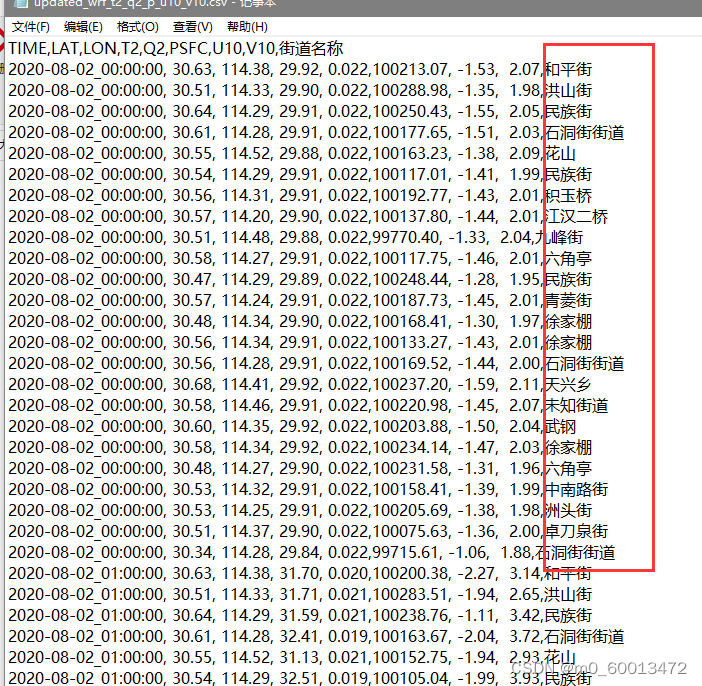
3、利用python将处理过的csv文件按照数据透视表分类
注意:时区识别的是上海,不要更改
import pandas as pd
import os
# 指定目录路径
directory_path = r'J:/工作室/大论文/WRF/validation/临时验证//'
# 需要生成透视表的列名列表
columns_to_pivot = ['Q2', 'T2', 'PSFC', 'U10', 'V10']
# 指定要处理的CSV文件名
specific_csv_file = 'updated_beijing.csv' # 这里替换为你想要处理的CSV文件名
# 确保columns_to_pivot中的列名在指定的CSV文件中是存在的
sample_df = pd.read_csv(os.path.join(directory_path, specific_csv_file))
columns_to_pivot = [col for col in columns_to_pivot if col in sample_df.columns]
# 获取完整的文件路径
file_path = os.path.join(directory_path, specific_csv_file)
# 读取指定的CSV文件
df = pd.read_csv(file_path)
# 指定日期时间格式,并转换为datetime类型,假设原始时间是UTC时间
df['TIME'] = pd.to_datetime(df['TIME'], format='%Y-%m-%d_%H:%M:%S', utc=True)
# 将UTC时间转换为中国标准时间(UTC+8)
df['TIME'] = df['TIME'].dt.tz_convert('Asia/Shanghai')
# 格式化时间列为所需的格式
df['TIME'] = df['TIME'].dt.strftime('%Y%m%d%H')
# 创建透视表字典
pivot_tables = {col: df.pivot_table(values=col, index='TIME', columns='街道名称', aggfunc='mean')
for col in columns_to_pivot if col in df.columns}
# 定义输出Excel文件的文件名
output_excel_file = 'beijing数据透视表.xlsx' # 这里可以指定你想要的文件名
# 使用ExcelWriter一次性保存所有透视表到一个Excel文件的不同工作表中
with pd.ExcelWriter(os.path.join(directory_path, output_excel_file), engine='xlsxwriter') as writer:
for col, table in pivot_tables.items():
# 确保透视表不为空
if not table.empty:
# 工作表名称为列名
table.to_excel(writer, sheet_name=col, index=True)
print(f"透视表已保存到Excel文件中:{os.path.join(directory_path, output_excel_file)}") 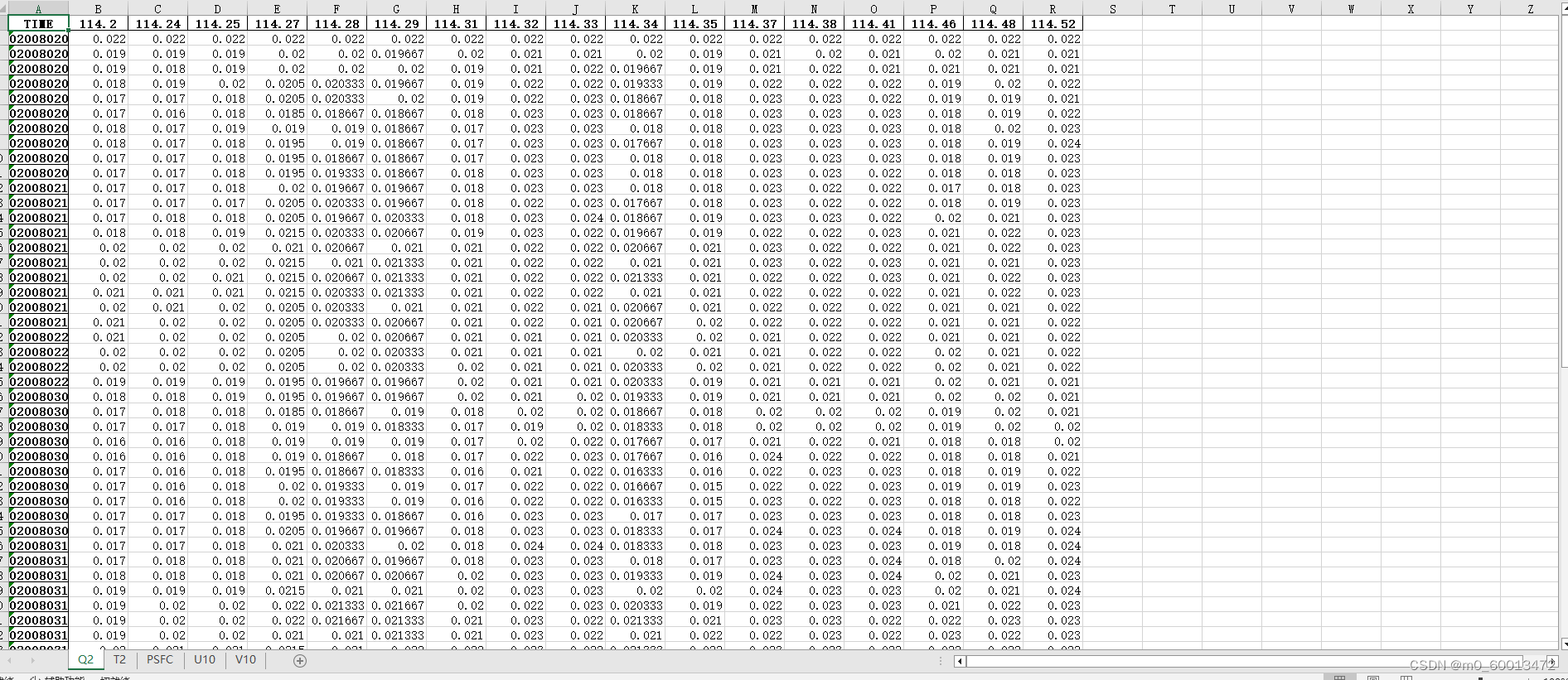
4、在excel表中增加新的2个sheet并计算相对湿度和10m风速
import pandas as pd
import numpy as np
# 指定Excel文件路径
excel_path = r'J:/工作室/大论文/WRF/validation/临时验证/beijing数据透视表.xlsx'
# 读取必要的工作表
t2_df = pd.read_excel(excel_path, sheet_name='T2', index_col=0)
q2_df = pd.read_excel(excel_path, sheet_name='Q2', index_col=0)
psfc_df = pd.read_excel(excel_path, sheet_name='PSFC', index_col=0) # 气压单位为Pa
u10_df = pd.read_excel(excel_path, sheet_name='U10', index_col=0)
v10_df = pd.read_excel(excel_path, sheet_name='V10', index_col=0)
# 定义计算相对湿度的函数
def qair2rh(qair, temp_c, press_mb=1013.25):
es = 6.112 * np.exp((17.67 * temp_c) / (temp_c + 243.5))
e = qair * press_mb / (0.378 * qair + 0.622)
rh = e / es * 100
return rh
# 定义计算风速的函数
def calculate_wind_speed(u, v):
return np.sqrt(u**2 + v**2)
# 创建一个新的DataFrame来保存相对湿度数据
rh_df = pd.DataFrame(index=t2_df.index, columns=t2_df.columns)
# 遍历每个时间点和街道,计算相对湿度
for time in t2_df.index:
for street in t2_df.columns:
temp_c = t2_df.at[time, street] # 温度 (摄氏度)
qair = q2_df.at[time, street] # 比湿 (kg/kg)
press_pa = psfc_df.at[time, street] # 气压 (帕斯卡)
press_mb = press_pa / 100 # 转换为毫巴
rh = qair2rh(qair, temp_c, press_mb) # 计算相对湿度
rh_df.at[time, street] = rh
# 创建一个新的DataFrame来保存风速数据
wind_speed_df = pd.DataFrame(index=u10_df.index, columns=u10_df.columns)
# 遍历每个时间点和街道,计算风速
for time in u10_df.index:
for street in u10_df.columns:
u10 = u10_df.at[time, street] # U分量
v10 = v10_df.at[time, street] # V分量
wind_speed = calculate_wind_speed(u10, v10) # 计算风速
wind_speed_df.at[time, street] = wind_speed
# 保存相对湿度和风速数据到新的Excel工作表
try:
with pd.ExcelWriter(excel_path, mode='a', engine='openpyxl', if_sheet_exists='replace') as writer:
rh_df.to_excel(writer, sheet_name='相对湿度', index=True, header=True)
wind_speed_df.to_excel(writer, sheet_name='10m风速', index=True, header=True)
print("相对湿度和10m风速工作表已添加到Excel文件中。")
except PermissionError as e:
print("无法写入文件,可能是文件正在被使用或权限不足:", e)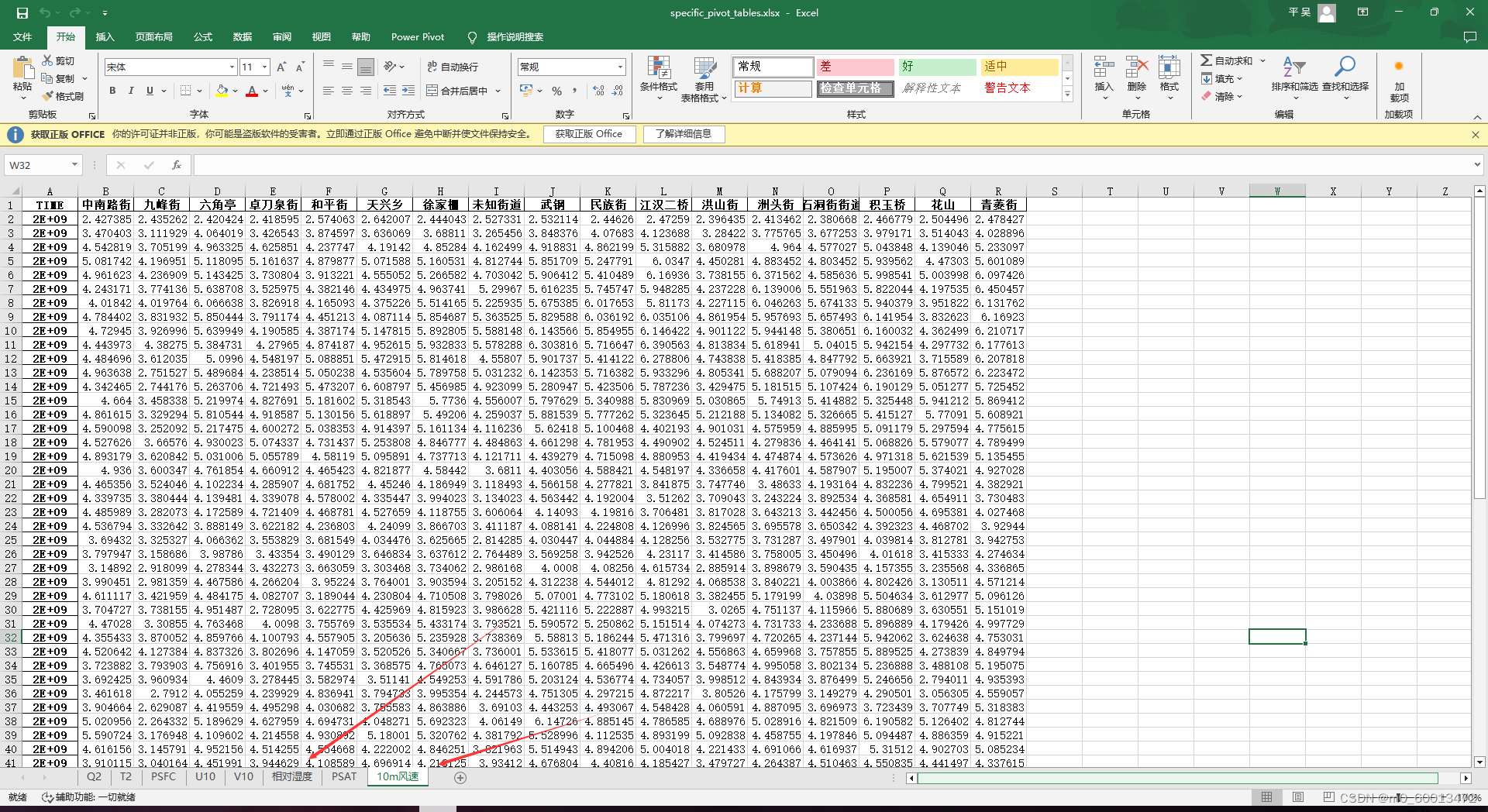
5、 处理气象站点数据格式与模拟数据格式相同
以下代码共分为4部分,每部分都可以单独拆开运行
import pandas as pd
# 指定的Excel文件路径
original_excel_path = 'J:/工作室/大论文/WRF/天气预报20200801--20200831.xlsx'
# 新表格的文件名
new_excel_file_path = 'J:/工作室/大论文/WRF/new_temperture.xlsx'
# 使用Pandas读取Excel文件
xls = pd.ExcelFile(original_excel_path)
# 获取所有sheet的名称
sheet_names = xls.sheet_names
# 初始化一个空列表来存储每个sheet的气温数据
temperature_data = []
# 读取第一个sheet的数据
df_first_sheet = pd.read_excel(xls, sheet_name=sheet_names[0])
# 提取第一个sheet的第一列作为监控时间点
monitor_time_points = df_first_sheet.iloc[:, 0].to_frame()
# 将监控时间点添加到气温数据列表中
temperature_data.append(monitor_time_points)
# 遍历所有的sheet名称
for sheet_name in sheet_names:
# 读取每个sheet的数据
df_sheet = pd.read_excel(xls, sheet_name=sheet_name)
# 假设我们要读取的气温数据在第4列
temps = df_sheet.iloc[:, 3]
# 将监控时间点的列名改为"TIME"
monitor_time_points.columns = ['TIME']
# 将气温数据转换为DataFrame,并添加监控时间点索引
temps_df = temps.to_frame(name=sheet_name)
# 将气温数据添加到列表中
temperature_data.append(temps_df)
# 使用pd.concat合并所有列,axis=0表示在行的方向上进行合并
new_df = pd.concat(temperature_data, axis=1)
# 确保第一列是监控时间点,其余列是各个sheet的气温数据
new_df = new_df.set_index(monitor_time_points.index)
# 将新表格的DataFrame保存为新的Excel文件,并指定工作表名称为“T2”
with pd.ExcelWriter(new_excel_file_path, engine='openpyxl') as writer:
new_df.to_excel(writer, sheet_name='T2', index=False)
print(f'New table saved as {new_excel_file_path}')
import pandas as pd
# 指定的Excel文件路径
original_excel_path = 'J:/工作室/大论文/WRF/天气预报20200801--20200831.xlsx'
# 新表格的文件名,现在改为相对湿度
new_excel_file_path = 'J:/工作室/大论文/WRF/new_humidity_table.xlsx'
# 使用Pandas读取Excel文件
xls = pd.ExcelFile(original_excel_path)
# 获取所有sheet的名称
sheet_names = xls.sheet_names
# 初始化一个空列表来存储每个sheet的相对湿度数据
humidity_data = []
# 读取第一个sheet的数据
df_first_sheet = pd.read_excel(xls, sheet_name=sheet_names[0])
# 提取第一个sheet的第一列作为监控时间点
monitor_time_points = df_first_sheet.iloc[:, 0].to_frame()
# 将监控时间点添加到相对湿度数据列表中
humidity_data.append(monitor_time_points)
# 遍历所有的sheet名称
for sheet_name in sheet_names:
# 读取每个sheet的数据
df_sheet = pd.read_excel(xls, sheet_name=sheet_name)
# 假设我们要读取的相对湿度数据在第4列
humidities = df_sheet.iloc[:, 4]
# 将监控时间点的列名改为"TIME"
monitor_time_points.columns = ['TIME']
# 将相对湿度数据转换为DataFrame,并添加监控时间点索引
humidity_df = humidities.to_frame(name=sheet_name)
# 将相对湿度数据添加到列表中
humidity_data.append(humidity_df)
# 使用pd.concat合并所有列,axis=0表示在行的方向上进行合并
new_df_humidity = pd.concat(humidity_data, axis=1)
# 确保第一列是监控时间点,其余列是各个sheet的相对湿度数据
new_df_humidity = new_df_humidity.set_index(monitor_time_points.index)
# 将新表格的DataFrame保存为新的Excel文件,并指定工作表名称为“相对湿度”
with pd.ExcelWriter(new_excel_file_path, engine='openpyxl') as writer:
new_df_humidity.to_excel(writer, sheet_name='相对湿度', index=False)
print(f'New humidity table saved as {new_excel_file_path}')
import pandas as pd
# 指定的Excel文件路径
original_excel_path = 'J:/工作室/大论文/WRF/天气预报20200801--20200831.xlsx'
# 新表格的文件名,现在改为风力
new_excel_file_path = 'J:/工作室/大论文/WRF/new_wind_table.xlsx'
# 使用Pandas读取Excel文件
xls = pd.ExcelFile(original_excel_path)
# 获取所有sheet的名称
sheet_names = xls.sheet_names
# 初始化一个空列表来存储每个sheet的风力数据
wind_data = []
# 读取第一个sheet的数据
df_first_sheet = pd.read_excel(xls, sheet_name=sheet_names[0])
# 提取第一个sheet的第一列作为监控时间点
monitor_time_points = df_first_sheet.iloc[:, 0].to_frame()
# 将监控时间点添加到风力数据列表中
wind_data.append(monitor_time_points)
# 遍历所有的sheet名称
for sheet_name in sheet_names:
# 读取每个sheet的数据
df_sheet = pd.read_excel(xls, sheet_name=sheet_name)
# 假设我们要读取的风力数据在第8列
winds = df_sheet.iloc[:, 7]
# 将监控时间点的列名改为"TIME"
monitor_time_points.columns = ['TIME']
# 将风力数据转换为DataFrame,并添加监控时间点索引
wind_df = winds.to_frame(name=sheet_name)
# 将风力数据添加到列表中
wind_data.append(wind_df)
# 使用pd.concat合并所有列,axis=0表示在行的方向上进行合并
new_df_wind = pd.concat(wind_data, axis=1)
# 确保第一列是监控时间点,其余列是各个sheet的风力数据
new_df_wind = new_df_wind.set_index(monitor_time_points.index)
# 将新表格的DataFrame保存为新的Excel文件,并指定工作表名称为“风力”
with pd.ExcelWriter(new_excel_file_path, engine='openpyxl') as writer:
new_df_wind.to_excel(writer, sheet_name='10m风速', index=False)
print(f'New wind table saved as {new_excel_file_path}')
import pandas as pd
# 指定三个Excel文件路径
temperature_excel_path = 'J:/工作室/大论文/WRF/new_temperture.xlsx'
humidity_excel_path = 'J:/工作室/大论文/WRF/new_humidity_table.xlsx'
wind_excel_path = 'J:/工作室/大论文/WRF/new_wind_table.xlsx'
# 新的Excel文件路径
final_excel_file_path = 'J:/工作室/大论文/WRF/final_weather_data.xlsx'
# 读取三个Excel文件
temperature_df = pd.read_excel(temperature_excel_path, sheet_name='T2')
humidity_df = pd.read_excel(humidity_excel_path, sheet_name='相对湿度')
wind_df = pd.read_excel(wind_excel_path, sheet_name='10m风速')
# 使用ExcelWriter来创建一个新的Excel文件,并添加三个工作表
with pd.ExcelWriter(final_excel_file_path, engine='openpyxl') as writer:
# 写入温度数据到'温度'工作表
temperature_df.to_excel(writer, sheet_name='T2', index=False)
# 写入相对湿度数据到'相对湿度'工作表
humidity_df.to_excel(writer, sheet_name='相对湿度', index=False)
# 写入风力数据到'风力'工作表
wind_df.to_excel(writer, sheet_name='10m风速', index=False)
print(f'Final weather data saved as {final_excel_file_path}')6、基于模拟数据将气象站的数据再次筛选时间和站点
import pandas as pd
import numpy as np
# 定义Excel文件的路径
excel_path_1 = 'J:/工作室/大论文/WRF/validation/临时验证/beijing数据透视表.xlsx'
excel_path_2 = 'J:/工作室/大论文/WRF/validation/临时验证/气象站数据.xlsx'
output_path = 'J:/工作室/大论文/WRF/validation/临时验证/气象站数据处理.xlsx'
# 使用pd.ExcelFile读取Excel文件
xls1 = pd.ExcelFile(excel_path_1)
xls2 = pd.ExcelFile(excel_path_2)
# 读取数据,自动将第一行作为列名,第一列作为索引
# 假设'T2'、'相对湿度'和'10m风速'是工作表的名称
df1_t = pd.read_excel(xls1, 'T2', index_col=0)
df1_rh = pd.read_excel(xls1, '相对湿度', index_col=0)
df1_wind_10m = pd.read_excel(xls1, '10m风速', index_col=0)
df2_t = pd.read_excel(xls2, 'T2', index_col=0)
df2_rh = pd.read_excel(xls2, '相对湿度', index_col=0)
df2_wind_10m = pd.read_excel(xls2, '10m风速', index_col=0)
# 确保df2的DataFrame只包含df1的列名
df2_t = df2_t.reindex(columns=df1_t.columns, fill_value=np.nan)
df2_rh = df2_rh.reindex(columns=df1_rh.columns, fill_value=np.nan)
df2_wind_10m = df2_wind_10m.reindex(columns=df1_wind_10m.columns, fill_value=np.nan)
# 找到两个DataFrame索引的交集
common_indices = df1_t.index.intersection(df2_t.index)
# 使用交集索引筛选df2的数据
filtered_df2_t = df2_t.loc[common_indices, :]
filtered_df2_rh = df2_rh.loc[common_indices, :]
filtered_df2_wind_10m = df2_wind_10m.loc[common_indices, :]
# 检查筛选结果是否符合预期
print(filtered_df2_t.head()) # 打印部分筛选后的T2数据
print(filtered_df2_rh.head()) # 打印部分筛选后的相对湿度数据
print(filtered_df2_wind_10m.head()) # 打印部分筛选后的10m风速数据
# 保存筛选后的数据到新的Excel文件
with pd.ExcelWriter(output_path, engine='openpyxl') as writer:
filtered_df2_t.to_excel(writer, sheet_name='T2')
filtered_df2_rh.to_excel(writer, sheet_name='相对湿度')
filtered_df2_wind_10m.to_excel(writer, sheet_name='10m风速')
print(f'Filtered data saved to {output_path}')7.计算观测值与模拟值T2以及相对湿度的标准差STDE、平均绝对误差MAE、均方根误差RMSE、相关系数R、一致性指数IOA
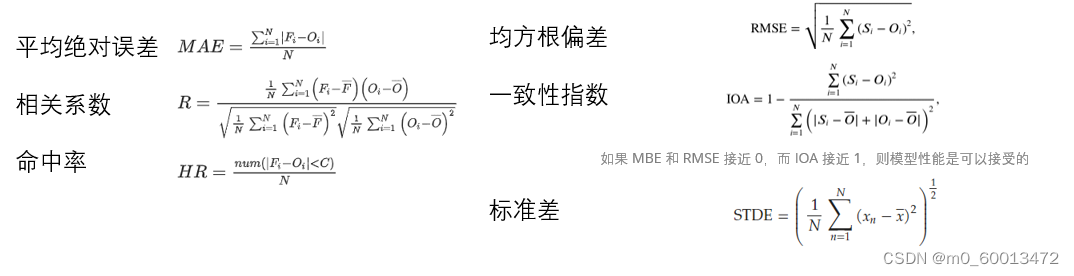
import pandas as pd
import numpy as np
import os
def calculate_and_write_stats(excel_path_1, excel_path_2, output_excel_path, sheet_name):
# 读取Excel文件中的数据
df_1 = pd.read_excel(excel_path_1, sheet_name=sheet_name, index_col=0)
df_2 = pd.read_excel(excel_path_2, sheet_name=sheet_name, index_col=0)
# 初始化一个空的列表来收集统计数据
stats_list = []
# 遍历每个街道,计算统计量
for street in df_1.columns:
if street in df_2.columns:
obs = df_1[street].dropna()
pred = df_2[street].dropna()
# 确保obs和pred数组长度相同才进行计算
if len(obs) == len(pred):
# 计算标准差 STD
std_dev = pred.std(ddof=1) # 使用 Bessel's correction
# 计算MAE
mae = np.mean(np.abs(obs - pred))
# 计算RMSE
rmse = np.sqrt(np.mean((obs - pred) ** 2))
# 使用pandas的.corr()方法计算皮尔逊相关系数 R
r = obs.corr(pred)
# 计算IOA
ioa = 1 - (np.sum((obs - pred) ** 2) /
np.sum(np.abs(pred - pred.mean()) ** 2))
# 将计算结果添加到列表中
stats_list.append({
'Street': street,
'STD': std_dev,
'MAE': mae,
'RMSE': rmse,
'R': r,
'IOA': ioa,
})
# 将列表转换为DataFrame
stats_df = pd.DataFrame(stats_list)
# 检查是否有任何统计量被计算
if not stats_df.empty:
# 检查输出文件是否存在,如果不存在则创建一个新的Excel文件
if not os.path.exists(output_excel_path):
mode = 'w' # 写入模式
else:
mode = 'a' # 追加模式
# 定义输出Excel文件的路径
with pd.ExcelWriter(output_excel_path, engine='openpyxl', mode=mode) as writer:
# 如果sheet存在,则替换它
if mode == 'a' and sheet_name in writer.book.sheetnames:
del writer.book[sheet_name]
stats_df.to_excel(writer, sheet_name=sheet_name, index=False)
print(f'Statistics have been written to {output_excel_path} in sheet "{sheet_name}"')
else:
print('No statistics were calculated.')
# 定义Excel文件的路径
excel_path_1 = 'J:/工作室/大论文/WRF/validation/临时验证/beijing数据透视表.xlsx'
excel_path_2 = 'J:/工作室/大论文/WRF/validation/临时验证/气象站数据处理.xlsx'
output_excel_path = 'J:/工作室/大论文/WRF/validation/临时验证/beijing统计.xlsx'
# 对不同的sheet分别进行操作
sheets_to_process = ['T2', '相对湿度']
for sheet_name in sheets_to_process:
calculate_and_write_stats(excel_path_1, excel_path_2, output_excel_path, sheet_name)















 1014
1014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









