







目录
一、Python环境与pip使用
1.1测试Python环境是否安装成功
- win+R,输入cmd,进入windows的命令行模式。
- 在命令行中输入python。若正确显示python版本号,则表是python环境安装成功。

若出现下面错误:

可能是因为在安装Python的过程中没有勾选 Add Python 3.7 to PATH 选项,此时需要手动对Python进行配置。
配置如下:
- 此电脑->属性->高级系统设置
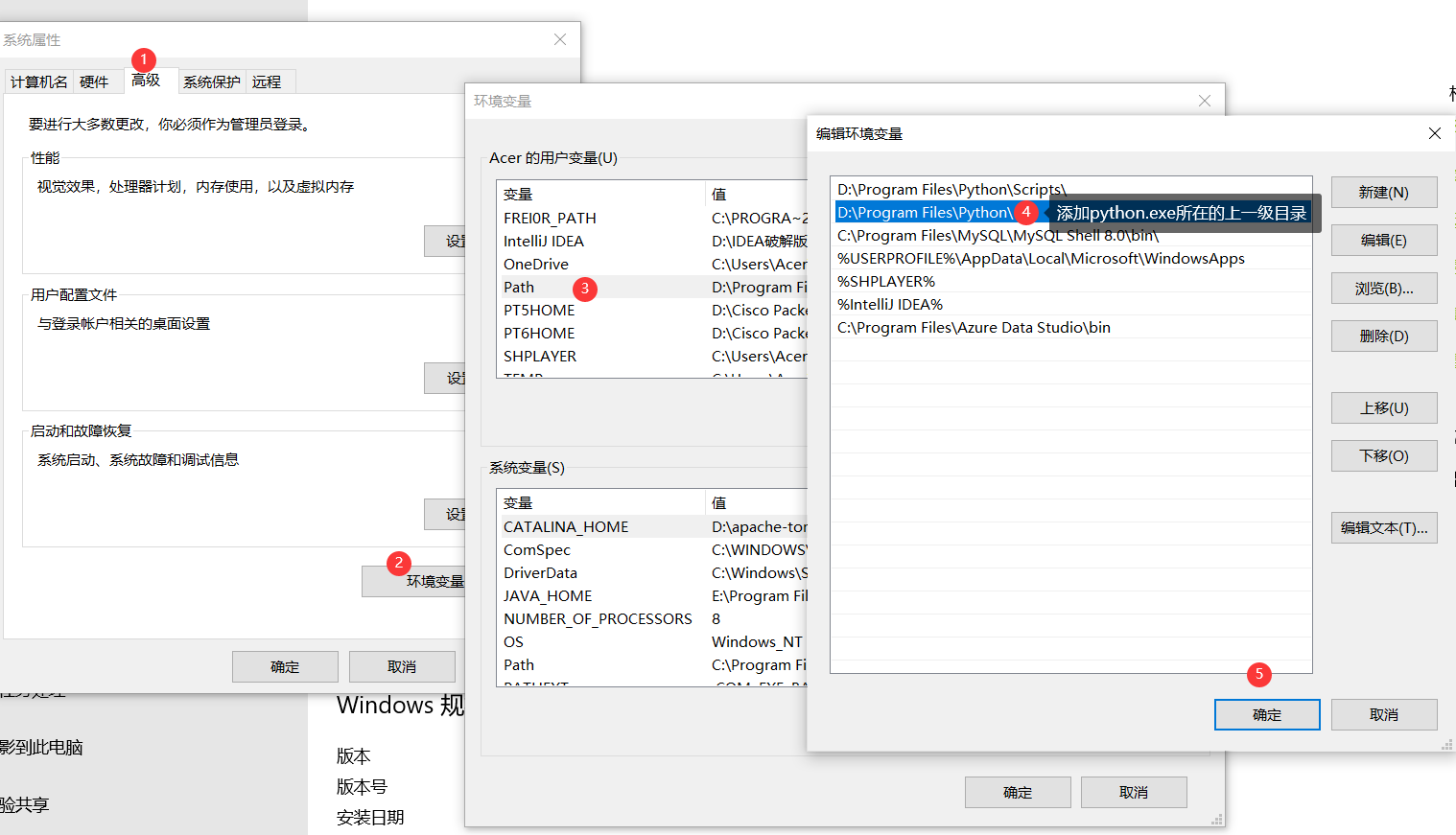
1.2pip使用
1.2.1测试pip能否使用
- pip 是一个现代的,通用的Python包管理工具。提供了对 Python 包的查找、下载、安装、卸载的功能,便于我们对Python的资源包进行管理。
- 在安装Python时,会自动下载并且安装pip。
在windows命令行中输入pip -V可以查看pip的版本。

若出现以下错误:

可能是因为在安装Python的过程中没有勾选 Add Python 3.7 to PATH 选项,此时需要手动对pip进行配置。
配置如下:
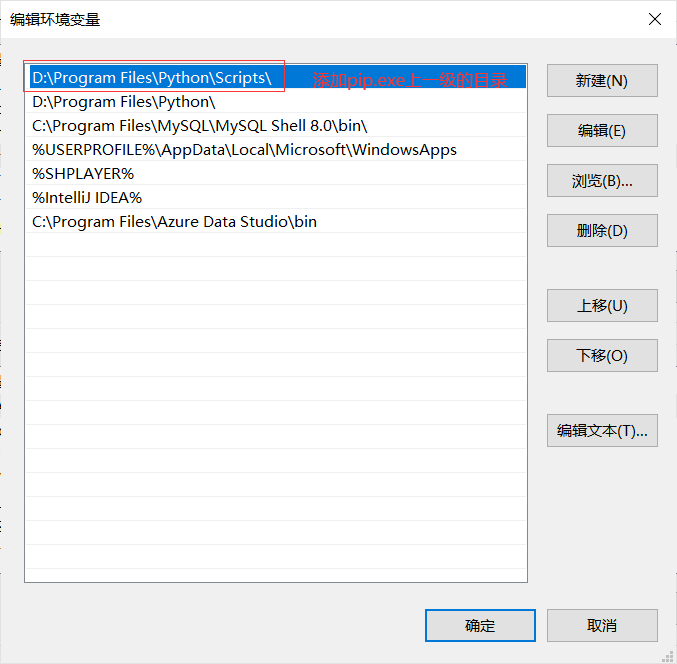
1.2.2使用pip管理Python包
| 命令 | 说明 |
| pip install 包名 | 安装指定的包 |
| pip uninstall 包名 | 删除指定的包 |
| pip list | 显示已经安装的包 |
| pip freeze | 以指定的格式显示已经安装的包 |
1.2.3修改pip下载源
运行pip install 命令会从网站上下载指定的python包,默认是从 https://files.pythonhosted.org/ 网站上下载。这是个国外的网站,遇到网络情况不好的时候,可能会下载失败,我们可以通过命令,修改pip现在软件时的源。
命令格式:
pip install 包名 -i 国内源地址
国内常用的pip下载源列表:
- 阿里云 http://mirrors.aliyun.com/pypi/simple/
- 中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
- 豆瓣(douban) http://pypi.douban.com/simple/
- 清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
- 中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/

......
![]()
二、运行Python程序
2.1终端运行
2.1.1在python解释器中书写代码

2.1.2在ipython解释器中书写代码

2.1.3退出python或ipython环境
方式一:exit() ->回车
方式二:ctrl+z ->回车
2.2运行python文件
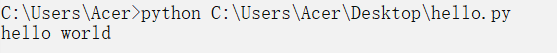
2.3pycharm
2.3.1基本介绍
- 尽管上面介绍的方法已经能够提高我们的编码速度,但是仍然无法应对我们开发中更加复杂的要求。一般情况下, 我们都需要借助工具来辅助我们快速的搭建环境,编写代码以及运行程序。
- IDE(Integrated Development Environment)又被称为集成开发环境。说白了,就是有一款图形化界面的软件,它集成了编辑代码,编译代码,分析代码,执行代码以及调试代码等功能。在我们Python开发中,最常用的IDE是pycharm.
- pycharm由捷克公司JetBrains开发的一款IDE,提供代码分析、图形化调试器,集成测试器、集成版本控制系统等, 主要用来编写Python代码。
- pycharm下载地址:http://www.jetbrains.com/pycharm/download
2.3.2使用介绍
1.运行Pycharm,选择 Create New Project ,创建一个新的Python工程。

2.选择'Pure Python'创建一个新的纯Python工程项目, Location 表示该项目的保存路径, Interpreter 用来指定Python解释器的版本。

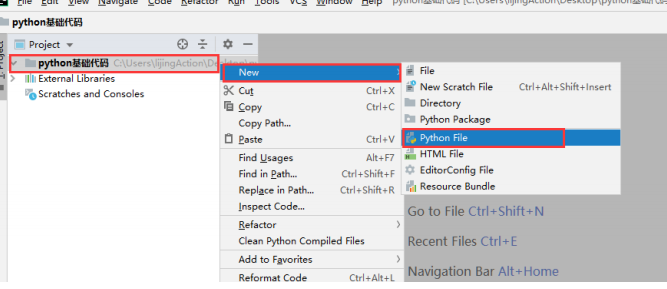
4.在弹出的对话框中输入的文件名 ,点击OK,表示创建一个Python程序的文本文件,文本文件后 缀名默认.py。
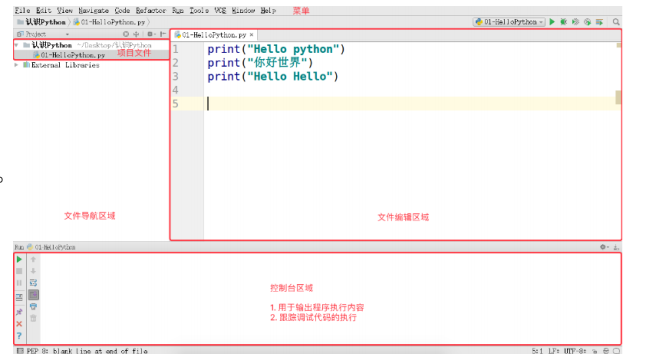
5.设置Python Script:

6.创建新的python文件,将会自动生成以下内容:

三、Python基础知识
3.1注释
3.1.1注释的介绍
- 在我们工作编码的过程中,如果一段代码的逻辑比较复杂,不是特别容易理解,可以适当的添加注释,以辅助自己或者其他编码人员解读代码。
- 注释是给程序员看的,为了让程序员方便阅读代码,解释器会忽略注释。使用自己熟悉的语言,适当的对代码进行注释说明是一种良好的编码习惯。
3.1.2注释的分类
单行注释
# 快捷键:ctrl+/
# 打印一句话
print('hello world') # 单行注释常写在代码的上方,而不是代码的右方
多行注释
# 以'''开始,以'''结束
'''
佛祖保佑
永无bug
'''3.2变量及数据类型
3.2.1变量的定义
- 对于重复使用/经常修改的数据,可以定义为变量,来提高编程效率。
- 定义变量的语法为: 变量名 = 变量值 。(这里的 = 作用是赋值。)
- 定义变量后可以使用变量名来访问变量值。
# 定义一个变量表示这个字符串,如果需要修改内容,只需要修改变量对应的值即可
weather = '今天天气真好'
print(weather)
print(weather)
print(weather)
# 应用场景:爬取网页上图片的URL,用img变量保存并打印出来
img = 'https://img14.360buyimg.com/n0/jfs/t1/9937/32/16620/170423/6274e112E8708e4ee/eaf45b30010eb33e.jpg'
print(img)注意
- 变量是可以变化的量,可以随时进行修改。
- 变量是用来存储数据的,而程序是用来处理数据的。
3.2.2数据类型
在 Python 里为了应对不同的业务需求,把数据分为不同的类型。

# Number 数值
# int
money = 100
# float
money1 = 1.2
# boolean 布尔
# 应用场景:流程控制语句、性别的变量(在工作中,性别变量使用的单词是sex/gender)
# 男 True,女 False
sex = True
gender = False
# string 字符串
# 字符串使用的是单引号或者双引号
s = '苍茫的天涯是我的爱'
s2 = "hello world"
# 不允许一单一双
# s3 = 'hhh"
# s4 = "aaa'
# 单引号和双引号的嵌套
s5 = '"哈哈哈"'
print(s5)
s6 = "'啊啊啊'"
print(s6)
# 不允许单引号套单引号,双引号套双引号
# s7 = ''行还是不行呢''
# s8 = ""行还是不行呢""
# list 列表
# 应用场景:当获取到了很多个数据的时候 那么我们可以将他们存储到列表中 然后直接使用列表访问
name_list = ['郭靖','黄蓉']
print(name_list)
# tuple 元组
age_tuple = (19,18)
print(age_tuple)
# dict 字典
# 格式:变量名 = {key:value,key2:value2}
# 应用场景:scrapy框架使用
person = {'name':'郭靖','age':19}
print(person)查看数据类型
- 在python中,只要定义了一个变量,而且它有数据,那么它的类型就已经确定了。不需要开发者主动的去说明它的类型,系统会自动辨别。在使用的时候 "变量没有类型,数据才有类型"。
- 如:下面a的类型可以根据其数据来判断,但是我们无法判断b的类型。

- 查看一个变量存储的数据类型:type(变量名)
# int
a = 100
# <class 'int'>
print(type(a))
# float
b = 2.5
# <class 'float'>
print(type(b))
# boolean
c = True
# <class 'bool'> bool是boolean的缩写
print(type(c))
# string
d = '中国'
# <class 'str'> str是string的缩写
print(type(d))
# list
e = [1,2,3]
# <class 'list'>
print(type(e))
# tuple
f = (1,2,3)
# <class 'tuple'>
print(type(f))
# dict
g = {'name':'zhangsan'}
# <class 'dict'>
print(type(g))3.3标识符和关键字
3.3.1标识符
- 标识符由字母、下划线和数字组成,且数字不能开头。
- 严格区分大小写。
- 不能使用关键字。
- 顾名思义
a = 'zhangsan' # bad
student = 'zhangsan' # good
b = 23 # bad
age = 23 # good- 采用命名法
- 驼峰命名法,又分为大驼峰命名法和小驼峰命名法。
- 小驼峰式命名法(lower camel case): 第一个单词以小写字母开始;第二个单词的首字母大写, 例如:myName、aDog
- 大驼峰式命名法(upper camel case): 每一个单字的首字母都采用大写字母,例如FirstName、LastName
-
还有一种命名法是用 下划线“_”来连接所有的单词 ,比如 send_buf。
- 驼峰命名法,又分为大驼峰命名法和小驼峰命名法。
3.3.2关键字

3.4类型转换
| 函数 | 说明 |
| int(x) | 将x转换为一个整数 |
| float(x) | 将x转换为一个浮点数 |
| str(x) | 将x转换为一个字符串 |
| bool(x) | 将x转换为一个布尔值 |
3.4.1转换为整数
# 浮点数1.68转换为整数是1
print(int(1.68))
# 字符串"678"转换为整数是678
print(int("678"))
# 布尔值True转换为整数是1
print(int(True))
# 布尔值False转换为整数是0
print(int(False))
注意
- 浮点数转换为整数,返回的是浮点数的整数部分,而不是四舍五入。
- 含有非法字符的字符串(如:"123.45" "12ab")不能转换为整数,否则会报错。
3.4.2转换为浮点数
# 整数123转换为浮点数是123.0
print(float(123))
# 字符串“12.34”转换为浮点数是12.34
print(float(12.34))
# 布尔值True转换为浮点数是1.0
print(float(True))
# 布尔值False转换为浮点数是0.0
print(float(False))注意
- 当我们在爬虫的时候,大部分获取的数据都是字符串类型的。字符串转换为浮点数是很常见的。
3.4.3转换为字符串
# 整数666转换为字符串是"666"
print(str(666))
# 浮点数888.0转换为字符串是"888.0"
print(str(888.0))
# 布尔值True转换为字符串是"True"
print(str(True))
# 布尔值False转换为字符串是"False"
print(str(False))注意
- 转换为字符串的结果用print打印后,不带单/双引号。
- 爬虫时,经常需要进行字符串之间的拼接。整数转换为字符串是很常见的。
3.4.4转换为布尔值
# 整数1转换为布尔值是True
print(bool(1))
# 整数2转换为布尔值是True
print(bool(2))
# 整数-1转换为布尔值是True
print(bool(-1))
# 整数0转换为布尔值是False
print(bool(0))
# 浮点数1.0转换为布尔值是True
print(bool(1.0))
# 浮点数0.0转换为布尔值是False
print(bool(0.0))
# 字符串“哈哈”转换为布尔值是True
print(bool("哈哈"))
# 字符串“ ”转换为布尔值是True
print(bool(" "))
# 字符串“”转换为布尔值是False
print(bool(""))
# 列表[1,2,3]转换为布尔值是True
print(bool([1,2,3]))
# 列表[]转换为布尔值是False
print(bool([]))以下情况结果均为False
print(bool(0))
print(bool(0.0))
print(bool(''))
print(bool(""))
print(bool([]))
print(bool(()))
print(bool({}))注意
- 转换为布尔值,总之一句话,非0即为True,非空即为True;0即为False,空即为False。
3.5运算符
3.5.1算术运算符
| 运算符 | 描述 | 实例 |
| + | 加 | 3 + 2 的输出结果为5 |
| - | 减 | 3 - 2 的输出结果为1 |
| * | 乘 | 3 * 2的输出结果为6 |
| / | 除 | 3 / 2的输出结果为1.5 |
| // | 取整除 | 5 // 3的输出结果为1 |
| % | 取余 | 5 % 3的输出结果为2 |
| ** | 指数 | 3 ** 2的输出结果为9 |
| () | 小括号 | 提高运算符优先级,比如:(1+2)*3的输出结果为9 |
注意
- 混合运算时,优先级顺序为: ** 高于 * / % // 高于 + - ,为了避免歧义,建议使用 () 来处理运 算符优先级。
- 不同类型的数字在进行混合运算时,整数将会转换成浮点数进行运算。

算术运算符在字符串中的使用
- 如果是两个字符串做加法运算,会直接把这两个字符串拼接成一个字符串。
str1 = 'hello'
str2 = 'world'
# helloworld
print(str1 + str2)- 如果是数字和字符串做加法运算,会直接报错。解决办法是将数字转换为字符串。(很常见)
str3 = 'hello'
a = 2
# TypeError: can only concatenate str (not "int") to str
# print(str3 + a)
# hello2
print(str3 + str(a)) - 如果是数字和字符串做乘法运算,会将这个字符串重复多次。
str4 = '你爱我 我爱你 蜜雪冰城甜蜜蜜'
# 你爱我 我爱你 蜜雪冰城甜蜜蜜你爱我 我爱你 蜜雪冰城甜蜜蜜
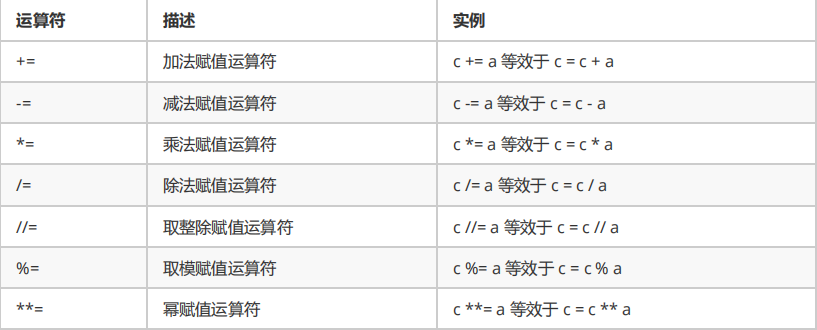
print(str4*2)3.5.2赋值运算符
| 运算符 | 描述 | 实例 |
| = | 赋值运算符 |
把
=
号右边的结果赋给左边的变量,如
num = 1 + 2 * 3
,结果
num
的值为
7
|
# 单个变量赋值
a = 1
# 1
print(a)
# 同时为多个变量赋相同的值
b = c = 2
# 2
print(b)
# 2
print(c)
# 分别为多个变量赋值(逗号隔开)
d,e,f = 3,3.14,"hello"
# 3
print(d)
# 3.14
print(e)
# hello
print(f)3.5.3复合赋值运算符
# +=
a = 100
a += 1 # a = a + 1
# 101
print(a)
# *=
b = 200
b *= 2 # b = b * 2
# 400
print(b)
# 符号右侧的表达式先计算结果,再与左边变量的值运算
c = 300
c *= 1 + 2 # c = c * (1 + 2)
# 900
print(c)3.5.4比较运算符
| 运算符 | 描述 | 实例 |
| == | 等于(比较对象是否相等) | 10 == 20 返回False |
| != | 不等于(比较对象是否不相等) | 10 !=20 返回True |
| > | 大于 | 10 > 20 返回False |
| >= | 大于等于 | 10 >= 10 返回True |
| < | 小于 | 10 < 20 返回True |
| <= | 小于等于 | 10 <=20 返回True |
扩展
- python2版本使用<>表示不等于,但是已经被python3版本遗弃。
3.5.5逻辑运算符
| 运算符 | 逻辑表达式 | 描述 | 备注 |
| and | x and y |
只要有一个运算数是
False
,结果就是
False;
只有所有的运算数都为
True
时,结果才是
True。
做取值运算时,取第一个为
False
的值,如果所有的值
都为
True,
取最后一个值。
| 运算符and 、or做取值运算时,最终取什么值根据下方的性能提升来看的 |
| or | x or y |
只要有一个运算数是
True
,结果就是
True;
只有所有的运算数都为
False
时,结果才是
False。
做取值运算时,取第一个为
True
的值,如果所有的值都为False,
取最后一个值。
| |
| not | not x |
布尔
"
非
" -
如果
x
为
True
,返回
False
。如果
x
为
False
,它返回
True
。
|
# and
print(10 > 5 and 10 > 20) # False
print(10 > 5 and 20 > 10) # True
a = 1 and 0
print(a) # 0
b = 1 and True
print(b) # True
# or
print(10 > 5 or 10 > 20) # True
print(10 < 5 or 20 < 10) # False
c = 1 or 2
print(c) # 1
d = 0 or False
print(d) # False
# not
print(not 1) # False
print(not False) # True性能提升
若前面结果的真假就能够得出最终结果的真假,则不需要判断后面结果的真假;若前面结果的真假不能够得出最终结果的真假,则需要判断后面结果的真假。
a = 20
# 短路与
a > 10 and print('hello world') # hello world
a < 10 and print('hello world')
# 短路或
a > 10 or print('hello world')
a < 10 or print('hello world') # hello world3.6输出与输入
3.6.1输出
# 普通输出
print('故事里的小黄花,从出生那年就飘着')
# 格式化输出
# 应用场景:scrapy框架的时候,会把爬取到的数据放到excel文件/mysql数据库/redis数据库,这时候需要格式化输出
name = '春风吹又生'
age = 19
# %s 代表字符串 %d代表数值
print('我的名字是%s,我的年龄是%d' % (name,age))
3.6.2输入
# 输入
password = input('请输入密码:')
print("您输入的密码是:%s" % password)
注意
- input()括号内的字符串是提示信息,用于在获取数据之前给用户一个简单提示。
- input()会把用户输入的任何值作为字符串来对待。
- input()在从键盘中获取数据之后,会存放到等号左边的变量中。
3.7流程控制语句
3.7.1if
语法
if 判断条件:
条件成立时,要运行的代码案例1
age = 20
if age >= 18:
print('我已经成年了')
if age < 18:
print('我还是未成年')![]()
案例2:从键盘获取自己的年龄,判断是否大于或者等于18岁,如果满足条件就输出“我已经成年了”
age = input('请输入您的年龄:')
if int(age) >= 18:
print('我已经成年了')
注意
- if条件判断语句有代码缩进,为一个tab键或者4个空格。
- input函数的返回结果是字符串,不能与整数进行比较。解决方法是:字符串强制转换为整数或者eval函数(去掉参数最外侧引号并执行余下语句的函数 )。
3.7.2if-else
if 判断条件:
条件成立时,要运行的代码
else:
条件不成立时,要运行的代码案例1
age = 19
if age >= 18:
print("我已经成年了")
else:
print("我还未成年")![]()
案例2 :从键盘中输入身高,如果身高没有超过150cm,则进动物园不用买票,否则需要买票
height = int(input("请输入您的身高(cm):"))
if height <= 150:
print("进动物园不用买票")
else:
print("进动物园需要买票")
3.7.3elif
if xxx1:
事情1(条件1满足则执行)
elif xxx2:
事情2(条件1不满足但是条件2满足则执行)
elif xxx3:
事情3(条件1、2均不满足但是条件3满足则执行)
...
else:
事情n(以上条件均不满足则执行)案例:从键盘中输入成绩,根据成绩输出对应的等级
score = eval(input("请输入您的成绩:"))
if score >= 90:
print("优秀")
elif score >= 80:
print("良好")
elif score >= 70:
print("中等")
elif score >= 60:
print("及格")
else:
print("不及格")

3.7.4for
语法
# 遍历(循环):一个一个的输出
# for 变量 in 要遍历的数据:
# 要执行的代码遍历数字
# range方法的结果是一个可遍历的对象,是一组数字
# range(5) [0,5) 左闭右开
for i in range(5):
print(i)
print("------")
# range(1,6) [1,6)
for i in range(1,6):
print(i)
print("------")
# range(1,10,3) [1,10) 步长为3
for i in range(1,10,3):
print(i)
遍历字符串及其下标
# 变量i用来保存字符串中的每个字符,s代表要遍历的字符串
s = "china"
for i in s:
print(i)
print("------")
# 变量j用来保存字符串的下标,len函数返回字符串的长度
for j in range(len(s)):
print(j)
遍历列表中的元素及其下标
# 应用场景:爬取到一个列表
a_list = ["张三","李四","王五"]
# 遍历列表中的元素
for i in a_list:
print(i)
print("------")
# 遍历列表中的下标
for j in range(len(a_list)):
print(j)
案例:1~100的和
sum = 0
for i in range(1,101):
sum += i
i += 1
print("1~100的和为:%d" % sum)![]()
3.8字符串高级
# 获取长度:len 获取字符串的长度
s= "china"
# 5
print(len(s))
# 查找内容:find 查找指定内容在字符串中是否存在,如果存在就返回该内容在字符串中第一次出现的开始位置索引值,如果不存在,则返回-1
s2 = "Ccabc"
# 1
print(s2.find('c')) # 注意区分大小写
# 判断:startswith,endswith 判断字符串是否以谁开头/结尾
s3 = "abcdf"
# True
print(s3.startswith('a'))
# False
print(s3.endswith('g'))
# 计算出现次数:count 返回 str在start和end之间 在 mystr里面出现的次数
s4 = "aaabbc"
# 2
print(s4.count('b'))
# 1
print(s4.count('b',4,5))
# 替换内容:replace 替换字符串中指定的内容,如果指定次数count,则替换不会超过count次
s5 = "abcbc"
# acccc
print(s5.replace('b','c'))
# accbc
print(s5.replace('b','c',1))
# 切割字符串:split 通过参数的内容切割字符串
s6 = "1#2#3#4#5"
# ['1', '2', '3', '4', '5']
print(s6.split('#'))
# 修改大小写:upper lower 将字符串中的小写转为大写 将字符串中的大写转为小写
s7 = "China"
# CHINA
print(s7.upper())
# china
print(s7.lower())
# 空格处理:strip 去空格
s8 = " a "
# 6
print(len(s8))
# 1
print(len(s8.strip()))
# 字符串拼接:join 字符串拼接
s9 = ','
# 1,2,3,4,5
print(s9.join("12345"))3.9列表高级
3.9.1添加元素
append
# append 在列表末尾追加元素
food_list = ["辣椒炒肉","酸菜炖鱼"]
food_list.append("小鸡炖蘑菇")
# ['辣椒炒肉', '酸菜炖鱼', '小鸡炖蘑菇']
print(food_list)
insert
# insert 在指定位置index插入元素object
char_list = ['a','c','d']
char_list.insert(1,'b')
# ['a', 'b', 'c', 'd']
print(char_list)
extend
# extend 将另一个列表中的元素逐一添加到列表中
num_list = [1,2,3,4]
num_list2 = [4,5,6,7]
num_list.extend(num_list2)
# [1, 2, 3, 4, 4, 5, 6, 7]
print(num_list)3.9.2删除元素
del
# del 根据元素的下标删除元素
num_list = [1,2,3,4,5]
del num_list[2]
# [1, 2, 4, 5]
print(num_list)
pop
# pop 删除最后一个元素(不加index参数)
num_list = [1,2,3,4,5]
# [1, 2, 3, 4]
num_list.pop() # del num_list[4]
print(num_list)remove
# remove 根据元素的值删除元素
num_list = [1,2,3,4,5]
# [1, 2, 4, 5]
num_list.remove(3)
print(num_list)3.9.3查找元素
in
# in(存在)
# 待查找的列表
name_list = ["张三","李四","王五"]
# 获取用户要查找的名称
findName = input("请输入您要查找的名称:")
# 查找是否存在
if findName in name_list:
print("%s在列表中" % findName)
else:
print("%s不在列表中" % findName)

not in
# not in(存在)
# 待查找的列表
age_list = [18,19,20]
# 获取用户要查找的年龄
findAge = eval(input("请输入您要查找的名称:"))
# 查找是否存在
if findAge not in age_list:
print("%d不在列表中" % findAge)
else:
print("%d在列表中" % findAge)

3.9.4修改元素
city_list = ["北京","上海","广州","深圳","长沙"]
# 通过指定下标来访问元素,赋新值即修改元素
city_list[4] = "常德"
# ['北京', '上海', '广州', '深圳', '常德']
print(city_list)3.10元组高级
Python的元组与列表类似,不同之处在于:
- 元组的元素不能修改、不能删除。
- 元组使用小括号表示,列表使用方括号表示。
访问元组
aTuple = ("hello",1,3.14)
# 元组访问元素的方式与列表相同
# 1
print(aTuple[1])修改元组
aTuple = ("hello",1,3.14)
# 元组的元素不能修改
# TypeError: 'tuple' object does not support item assignment
# aTuple[1] = 2
# print(aTuple[1])
# 元组的元素不能删除
# TypeError: 'tuple' object doesn't support item deletion
# del aTuple[2]
# print(aTuple)定义只有一个元素的元组
# 定义只有一个元素的元组,需要在该元素的后面加一个逗号,否则就是整型数据
bTuple = (1,)
# <class 'tuple'>
print(type(bTuple))
cTuple = (1)
# <class 'int'>
print(type(cTuple))3.11切片
切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。
常用的切片语法:
- [起始:结束]
- [起始:]
- [:结束]
- [起始:结束:步长]
注意
- 选取的区间从“起始”开始,到“结束”位的前一位结束(不包括结束为本身),步长表示选取间隔。
# 索引是通过下标取某一个元素
# 切片是通过下标取某一段元素
s = "hello world"
# hello world
print(s) # 直接打印字符串
# e
print(s[1]) # 索引
# hello
print(s[0:5]) # [0,5) 左闭右开
# llo world
print(s[2:]) # 从下标2开始,到后面所有的元素
# hello wo
print(s[:8]) # 从起始位置开始,到下标为7(不是下标为8)的元素
# eoo
print(s[1:10:3]) # 从下标为1开始,到下标为9的元素,步长为33.12字典高级
3.12.1查看元素
查找字典中的元素有两种方式:
- 使用key键查看。
- 使用get函数查看。
这两种方式的区别:
- 使用key键查看的方式不能查看不存在的key,否则会报错。
- 使用get函数查看的方式可以查看不存在的key,只是结果返回为None。
注意
- 不能使用.来获取数据。
定义一个字典
person = {"name":"张三丰","age":19}使用key键查看
# 获取姓名
# 张三丰
print(person["name"])
# KeyError: 'sex'
# 查看不存在的key,会发生异常
# print(person["sex"])使用get函数查看
# 19
print(person.get("age"))
# None
print(person.get("sex"))不能使用.来获取数据
# AttributeError: 'dict' object has no attribute 'name'
print(person.name)3.12.2修改元素
为已存在key赋值就是修改。
person = {"name":"张三","age":18}
# {'name': '张三', 'age': 18}
print(person)
# 为已存在的键赋值就是修改
person["name"] = "法外狂徒"
# {'name': '法外狂徒', 'age': 18}
print(person)3.12.3添加元素
添加元素时,如果键不存在,就会添加这个元素。
添加元素时,如果键存在,就会修改这个元素。
person = {"name":"老牛"}
# 添加元素时,如果键不存在,就会添加这个元素
# {'name': '老牛'}
print(person)
person["age"] = 19
# {'name': '老牛', 'age': 19}
print(person)
# 添加元素时,如果键存在,就会修改这个元素
# {'name': '老牛', 'age': 19}
print(person)
person["name"] = "老马"
# {'name': '老马', 'age': 19}
print(person)3.12.4删除元素
del删除指定的元素
person = {"name":"老马","age":19}
# {'name': '老马', 'age': 19}
print(person)
# del删除指定的元素
del person["age"]
# {'name': '老马'}
print(person)
del删除整个字典
person2 = {"name":"老牛","age":19}
# {'name': '老牛', 'age': 19}
print(person2)
# del删除整个字典
del person2
# NameError: name 'person2' is not defined
# person2已经被删除了,未被定义
# print(person2)
clear清空整个字典,但字典对象仍在
person3 = {"name":"老鼠","age":19}
# {'name': '老鼠', 'age': 19}
print(person3)
# clear清空整个字典,但字典对象仍在
person3.clear()
# {}
print(person3)3.12.5遍历元素
定义一个字典
# 定义一个字典
student = {"name":"张三","age":19}遍历字典的key(键)
# 遍历字典的key(键)
# key是变量名,keys()函数获取字典中所有的key值
for key in student.keys():
print(key)

遍历字典的value(值)
# 遍历字典的value(值)
# value是变量名,values()函数获取字典中所有的value值
for value in student.values():
print(value)

遍历字典的key-value(键值对)
# 遍历字典的key-value(键值对)
# key,value是两个变量名,items()函数获取字典中所有的元素
for key,value in student.items():
print("key=%s,value=%s" %(key,value))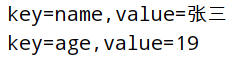
遍历字典的项(元素)
# 遍历字典的项(元素)
# item是变量名,items()函数获取字典中所有的元素
for item in student.items():
print(item)
注意
- 遍历字典的键值对,需要两个变量。每次循环时,字典中的每个元素的键和值都会分别赋给这两个变量。
- 遍历字典的项,只需要一个变量。每次循环时,字典中的每个元素这个整体会赋给这个变量。
3.13函数
3.13.1定义函数
语法格式
def 函数名():
代码案例
# 定义一个函数,能够完成打印信息的功能
def f1():
print("故事的小黄花")
print("从出生那年就开着")3.13.2调用函数
定义完函数后,函数是不会自动执行的,需要调用它才可以执行。
语法
函数名()案例
# 定义完函数后,函数是不会自动执行的,需要调用它才可以执行
f1()
3.13.3函数参数
分析以下代码的缺陷
# 定义一个函数,实现两个数的和
def add():
a = 1
b = 2
c = a + b
print(c)
# 调用函数
# 3
add()这个函数不通用,只能计算1+2,即如果我们想计算其它两个数的和,就不能用到这个函数了。
在定义函数的时候,可以让函数接收数据,就解决了这个问题,这就是函数的参数。
定义带参函数
# 定义一个带参函数,实现两个数的和
def add(a,b):
c = a + b
print(c)
# 调用带参函数,实现2和3的和
# 5
add(2,3)调用函数时参数的顺序
# 位置参数
# 7
add(3,4)
# 关键字参数
# 7
add(b = 4,a = 3)形参和实参
- 形式参数:简称“形参”,就是定义时括号内的参数,用来接收具体数据的变量。
- 实际参数:简称“实参”,就是调用时括号内的参数,用来传递给函数的具体数据。
3.13.4函数返回值
返回值就是程序中函数完成一件事情后,最后给调用者的结果。
定义带有返回值的带参函数
# 定义一个带有返回值的带参函数
def add(a,b):
c = a + b
# return后可以写变量名
return c
def add2(a,b):
# return后可以写计算表达式
return a + b调用函数并保存函数的返回值
# 调用函数并保存函数的返回值
# 使用一个result变量来保存add函数的返回值
result = add(1,2)
# 使用一个result2变量来保存add2函数的返回值
result2 = add(2,3)
# 打印变量result的结果
# 3
print(result)
# 打印变量result2的结果
# 5
print(result2)3.13.5局部变量与全局变量
局部变量只能在函数内部使用,不能在函数外部使用。
全局变量既可以在函数外部使用,也可以在函数内部使用。
局部变量的作用域是函数内部,全局变量的作用域是整个程序。
局部变量
def f1():
# 定义局部变量b
a = 100
# f1函数的局部变量b只能在函数内部使用
print(a)
# NameError: name 'a' is not defined
# f1函数的局部变量不能在函数外部使用
# print(a)
全局变量
# 定义全局变量b
b = 200
# 全局变量b既可以在函数外部使用
print(b)
def f2():
# 全局变量b也可以在函数内部使用
print(b)3.14文件
3.14.1文件的打开与关闭
在python中,使用open函数可以创建一个新文件或者打开一个已经存在的文件。
语法
open(文件路径,访问模式)案例
# 使用open函数创建一个新文件,文件路径为test.txt,访问模式为可写
fp = open('test.txt','w')
# 关闭这个文件
fp.close()
# 使用open函数打开一个已经存在的文件
fp = open('test.txt','w')
# 关闭这个文件
fp.close()文件路径
- 绝对路径:指的是绝对位置,完整地描述了目标的所在地,所有目录层级关系是一目了然的。
- 例如: E:\python ,从电脑的盘符开始,表示的就是一个绝对路径。
- 相对路径:是从当前文件所在的文件夹开始的路径。
- test.txt ,是在当前文件夹查找 test.txt 文件
- ./test.txt ,也是在当前文件夹里查找 test.txt 文件, ./ 表示的是当前文件夹。
- ../test.txt ,从当前文件夹的上一级文件夹里查找 test.txt 文件。 ../ 表示的是上一级文件夹
- demo/test.txt ,在当前文件夹里查找 demo 这个文件夹,并在这个文件夹里查找 test.txt 文件。
访问模式

3.14.2文件的读写
写数据(write)
使用write()可以完成向文件中写入数据。
以只写方式写数据:
# 手动创建一个demo文件夹(暂时不能通过代码创建)
# 在demo文件夹中创建一个test.txt文件,访问模式为可写
fp = open('demo/test.txt','w')
# 向该文件写入5行hello world
fp.write('hello world\n' * 5)
# 关闭该文件
fp.close()
# 打开一个已经存在的文件
fp = open('demo/test.txt','w')
# 向该文件写入2行hello python
fp.write('hello python\n' * 2)
# 关闭该文件
fp.close()
# 此时该文件的内容是2行hello python,也就是说之前5行hello world的内容被覆盖了。以追加方式写数据:
# 在demo文件夹中创建一个test.txt文件,访问模式为追加
fp = open('demo/test2.txt','a')
fp.write('hello world\n' * 5)
fp.close()
# 打开一个已经存在的文件
fp = open('demo/test2.txt','a')
fp.write('hello python\n' * 2)
fp.close()
# 此时该文件的内容5行hello world加上2行hello python,也就是2行hello python的内容追加到文件的末尾。得出结论:
- 如果以只写或者追加方式打开的文件不存在,那么创建;
- 如果打开的文件已存在,那么只写方式会将新数据覆盖到旧数据,追加方式会将新数据追加到文件末尾。
类比(Linux命令):
- echo "hello" > a.txt 覆盖
- echo "hello" >> a.txt 追加
读数据(read)
使用read(num)可以从文件中读取数据,num表示要从文件中读取数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据。
# 打开一个已经创建的文件,访问模式为只读
fp = open('demo/test.txt','r')
# 读取5个字节的数据
content = fp.read(5)
print(content)
# 分割线,用来测试
print('-' * 12)
# 从上次读取的位置继续读取剩下的数据
content = fp.read()
print(content)
fp.close()
注意
- 如果以只读方式打开的文件不存在,会报错。
- 如果以只读方式打开的文件存在,那么可以省略参数"r"。
读数据(readline)
readline只用来读取一行数据。
fp = open('demo/test2.txt','r')
content = fp.readline()
print("第一行:%s" % content)
content = fp.readline()
print("第二行:%s" % content)
fp.close()

读数据(readlines)
readlines可以按照行的方式把整个文件的内容进行一次性读取,并且返回的是一个列表,其中每一行为列表的一个元素。
fp = open('demo/test2.txt','r')
content = fp.readlines()
# <class 'list'>
print(type(content))
print(content)
print("-" * 30)
for temp in content:
print(temp)
fp.close()
3.14.3序列化和反序列化
- 序列化:python对象-->字节序列
- 反序列化:字节序列->python对象
| 函数 | 作用 |
| dumps | 传入一个对象参数,将对象转换为字符串 |
| dump | 传入一个对象参数和一个文件参数,在对象转换为字符串的同时将其写入文件 |
import json
fp = open('names.txt','w')
names_list = ['zhangsan','lisi']
# TypeError: write() argument must be str, not list
# 不能直接将列表写入文件
# fp.write(names_list)
# 调用json的dumps方法,传入一个对象参数,将对象转换为字符串
result = json.dumps(names_list)
fp.write(result)
# <class 'str'>
print(type(result))
fp.close()import json
fp = open('names.txt','w')
names_list = ['zhangsan','lisi']
# 调用json的dump方法,传入一个对象参数和一个文件参数,在对象转换为字符串的同时将其写入文件
json.dump(names_list,fp)
fp.close()使用json实现反序列化
| 函数 | 作用 |
| loads | 传入一个字符串参数,将字符串转换为对象 |
| load | 传入一个文件参数,将文件中的内容转换为对象 |
import json
fp = open('names.txt','r')
content = fp.read()
# ["zhangsan", "lisi"]
print(content)
# <class 'str'>
print(type(content))
# 调用json的loads方法,传入一个字符串参数,将字符串转换为对象
result = json.loads(content)
# ['zhangsan', 'lisi']
print(result)
# <class 'list'>
print(type(result))
fp.close()import json
fp = open('names.txt','r')
# 调用json的load方法,传入一个文件参数,将文件中的内容转换为对象
result = json.load(fp)
# ['zhangsan', 'lisi']
print(result)
# <class 'list'>
print(type(result))
fp.close()3.15异常
3.15.1读取文件异常
在读取一个文件时,如果这个文件不存在,则会报出FileNotFoundError异常
fp = open('aaa.txt','r')
# FileNotFoundError: [Errno 2] No such file or directory: 'aaa.txt'
fp.read()
fp.close()
3.15.2try...except语句
语法
try:
可能会出现异常的代码块
except 异常的类型:
出现异常后的处理语句案例
try:
fp = open('aaa.txt','r')
fp.read()
except FileNotFoundError:
print("文件名称未找到,请检查文件名称是否正确")![]()















 751
751











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









