







全连接神经网络是一种最基本的神经网络结构,英文为Full Connection,所以一般简称FC。FC的神经网络中除输入层之外的每个节点都和上一层的所有节点有连接。例如下面这个网络结构就是典型的全连接:
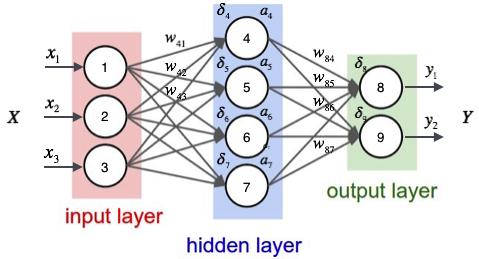
神经网络的第一层为输入层,最后一层为输出层,中间所有的层都为隐藏层。在计算神经网络层数的时候,一般不把输入层算做在内,所以上面这个神经网络为2层。其中输入层有3个神经元,隐层有4个神经元,输出层有2个神经元。
网络结构:

代码程序:
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F # 用Relu函数
import torch.optim as optim # 优化器优化
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
# transform:把图像转化成图像张量
train_dataset = datasets.MNIST(root='../dataset/mnist',
train=True,
download=True,
transform=transform) # 训练数据集
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(test_dataset,
shuffle=False,
batch_size=batch_size)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(in_channels=1,out_channels=10,kernel_size=(3,3))
self.conv2 = torch.nn.Conv2d(in_channels=10,out_channels=20,kernel_size=(3,3),padding=1)
self.conv3 = torch.nn.Conv2d(in_channels=20,out_channels=30,kernel_size=(3,3))
self.pooling = torch.nn.MaxPool2d(kernel_size=(2,2))
self.relu = torch.nn.ReLU()
self.fc1 = torch.nn.Linear(120,60)
self.fc2 = torch.nn.Linear(60, 10)
def forward(self,x):
batch_size = x.size(0)
x = self.relu(self.pooling(self.conv1(x)))
x = self.relu(self.pooling(self.conv2(x)))
x = self.relu(self.pooling(self.conv3(x)))
x = x.view(batch_size,-1)
x = self.fc1(x)
x = self.fc2(x)
return x
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# 因为网络模型已经有点大了,所以梯度下降里面要用更好的优化算法,比如用带冲量的(momentum),来优化训练过程
# 把一轮循环封装到函数里面
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad() # 优化器,输入之前清零
# forward + backward + updat
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299: # 每300轮输出一次
print('[%d,%5d] loss:%.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0 # 正确多少
total = 0 # 总数多少
with torch.no_grad(): # 测试不用算梯度
for data in test_loader: # 从test_loader拿数据
images, labels = data
outputs = model(images) # 拿完数据做预测
_, predicted = torch.max(outputs.data, dim=1) # 沿着第一个维度找最大值的下标,返回值有两个,因为是10列嘛,返回值
# 返回值一个是每一行的最大值,另一个是最大值的下标(每一个样本就是一行,每一行有10个量)(行是第0个维度,列是第1个维度)
total += labels.size(0) # 取size元组的第0个元素(N,1),
correct += (predicted == labels).sum().item() # 推测出来的分类与label是否相等,真就是1,假就是0,求完和之后把标量拿出来
print('Accuracy on test set:%d %%' % (100 * correct / total))
# 训练
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test() #训练一轮,测试一轮
运行结果:
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









