










这是刘二大人系列课程笔记的 最后一个笔记了,介绍的是 BasicCNN 和 AdvancedCNN ,我做图像,所以后面的RNN我可能暂时不会花时间去了解了;
写在前面:
- 本节把基础个高级CNN放在一起记录了,注意查看对应关系;
- 详细的代码理解参看下面的链接:
【Pytorch深度学习实践】B站up刘二大人课程笔记——目录与索引(已完结)
Lecture10 —— Basic & Advanced CNN 基础 & 高级-卷积神经网络
说在前面:
这节课的有两个部分,基础卷积神经网络和高级别卷积神经网络:
1. Basic CNN 卷积神经网络 基础
-
对于基础知识,不写代码了,把所有讲到的知识点,和每个知识点该注意的,以及扩展知识整理记录:
- 卷积的概念:
-
从单通道卷积讲起:即
input图像是单通道,卷积核kernel也是单通道,那么输出必然也是单通道。这里还没有讲到扩充padding和滑动步长stride,所以只关注输入和输出矩阵的尺寸大小; -
讲到这,刘老师介绍了
CCD相机模型,这是一种通过光敏电阻,利用光强对电阻的阻值影响,对应地影响色彩亮度实现不同亮度等级像素采集的原件。三色图像是采用不同敏感度的光敏电阻实现的。 -
还介绍了矢量图像(也就是PPT里通过圆心、边、填充信息描述而来的图像,而非采集的图像);
-
接下来讲到三通道
input图像的卷积操作:实为将三个通道的input分别与三个通道kernel对应相乘,再将对应位置相加,最后输出单通道output图像的过程; -
此处的
input、kernel、output的形状,以及通道数channel,是要非常注意的,我们玩卷积神经网络,其中,向的卷积层中传递的参数,与这里的参数一一对应,要非常熟悉每一个参数位置,应该是谁的channel值,后面的full connected layer也是一样,传入的是位置参数,也就是说,每一个位置必须是所需对应的参数,决不能混乱; -
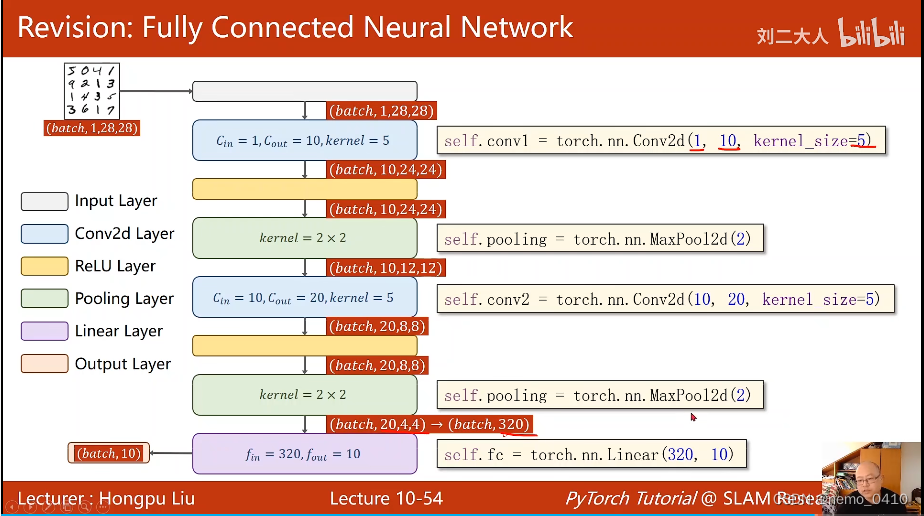
这里还有个我以前搞不清的地方,在刘老师的课上听明白了:就是这种图是什么意思,长宽高分别对应的是图像的宽高通道数,分别怎么对应的,我得插一张图了(这应该是篇博客第一章图):

-
以上是单个卷积核的获取的结果,也就是说,上图中见
kernel的位置,仅仅是一个(组)卷积核;如果我们要提取不同的特征,就需要不同(组)的卷积核,也就是说,会出现这样一种情况:

-
于是,kernel其实是一个4维的
tensor,每一个(组)filter是三维,多个这样的filters,就需要是4个dimension的概念,你,看懂了吗。 -
接下来讲了卷积层建立的方式,以及代码的简单实现,详细内容见本节插入的链接;
-
在后面讲了三个卷积的基本操作,扩充
padding、步长stride和池化pooling:padding是为了让源图像最外一圈或多圈像素(取决于kernel的尺寸),能够被卷积核中心取到。这里有个描述很重要:想要使源图像(1,1)的位置作为第一个与kernel中心重合,参与计算的像素,想想看padding需要扩充多少层,这样就很好计算了吧;stride操作指的是每次kernel窗口滑动的步长,默认值当然是1了,插句话,假设不使用扩充padding,output图像的尺寸就会缩小,想要使输出的尺寸与输入尺寸保持不变,看看上一个知识点的padding描述,就很好计算需要外圈加几圈去保证输出的尺寸了吧;
-
这里插入一段代码,这段代码中
input和kernel后面的view函数,输入的位置参数含义是不一样的,看图可知细节:

-
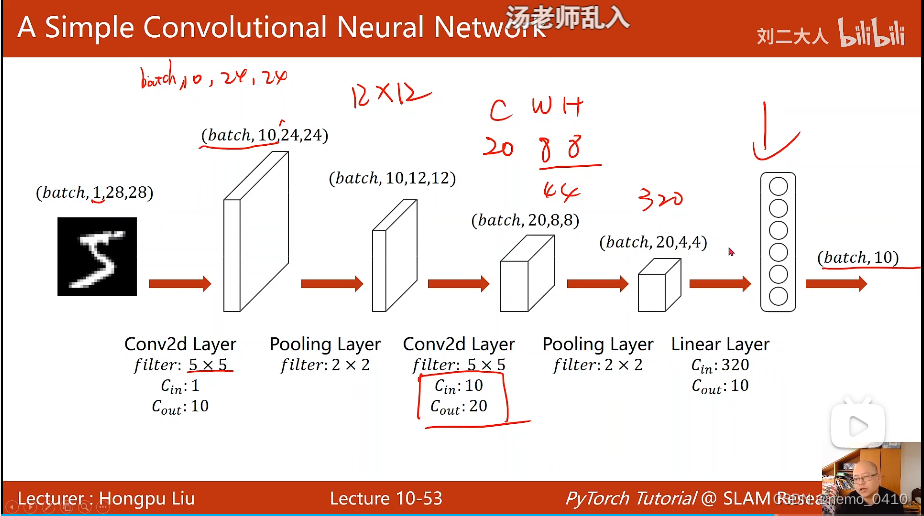
- 接下来讲了一个简单的卷积神经网络的例子,这个例子需要记住并会用,详见节尾链接;只有一个地方需要特别注意的地方,就是整个网络建立完以后,是不关心输入图像的宽度和高度大小的,也就是说,无论来多大尺寸的图像,我(网络)都能处理,需要改动的仅是
Fully Connected Layer(分类器)的输入,需要通过前面最后一层的计算来求得;而FCY的输出,是确定的(分10类就输出10); - 将模型送入
GPU的过程,可以参看我其他的博客,关于这个知识点,我是觉得土堆的讲解更好,整个网络,有三个内容需要传入GPU去计算:[1]网络模型、[2]数据(input和label)、[3]损失函数loss。参见【PyTorch教程】P30 GPU加速;
- 卷积的概念:
-
至此,刘老师
Basic CNN这节课的全部知识点都在这里了,代码的简单实现见节尾链接。
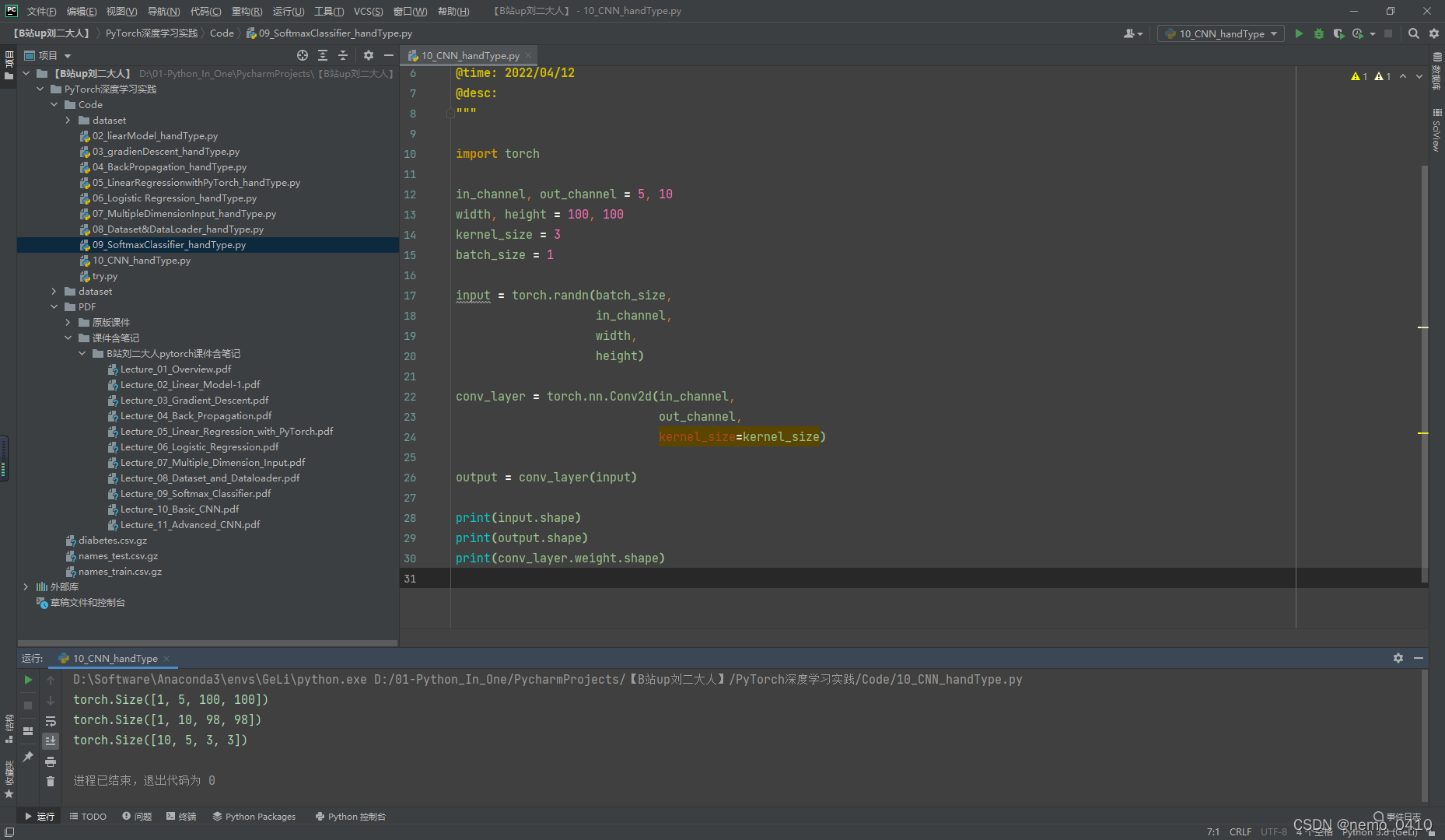
卷积操作-完整代码:
#!usr/bin/env python
# -*- coding:utf-8 _*-
"""
@author: 24_nemo
@file: 10_CNN_handType.py
@time: 2022/04/12
@desc:
"""
import torch
in_channel, out_channel = 5, 10
width, height = 100, 100
kernel_size = 3
batch_size = 1
input = torch.randn(batch_size,
in_channel,
width,
height)
conv_layer = torch.nn.Conv2d(in_channel,
out_channel,
kernel_size=kernel_size)
output = conv_layer(input)
print(input.shape)
print(output.shape)
print(conv_layer.weight.shape)
运行结果(截图时仍在运行):
MNIST数据集分类任务-课堂实况:
MNIST手写数据集分类任务-完整代码:
import matplotlib.pyplot as plt
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim # (可有可无)
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(root='../dataset/mnist/',
train=True,
download=True,
transform=transform
)
train_loader = DataLoader(dataset=train_dataset,
shuffle=True,
batch_size=batch_size,
)
test_dataset = datasets.MNIST(root='../dataset/mnist/',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(dataset=test_dataset,
shuffle=False,
batch_size=batch_size,
)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(in_channels=1, out_channels=10, kernel_size=5)
self.conv2 = torch.nn.Conv2d(in_channels=10, out_channels=20, kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(320, 10)
def forward(self, x):
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1)
x = self.fc(x)
return x
model = Net()
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
running_loss = 0.0
for batch_index, (inputs, labels) in enumerate(train_loader, 0):
inputs, labels = inputs.to(device), labels.to(device)
y_hat = model(inputs)
loss = criterion(y_hat, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_size % 10 == 9:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_index + 1, running_loss / 300))
def test():
correct = 0
total = 0
with torch.no_grad():
for (images, labels) in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, pred = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (pred == labels).sum().item()
print('accuracy on test set: %d %%' % (100 * correct / total))
return correct / total
if __name__ == '__main__':
epoch_list = []
acc_list = []
for epoch in range(10):
train(epoch)
acc = test()
epoch_list.append(epoch)
acc_list.append(acc)
plt.plot(epoch_list, acc_list)
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()
运行结果: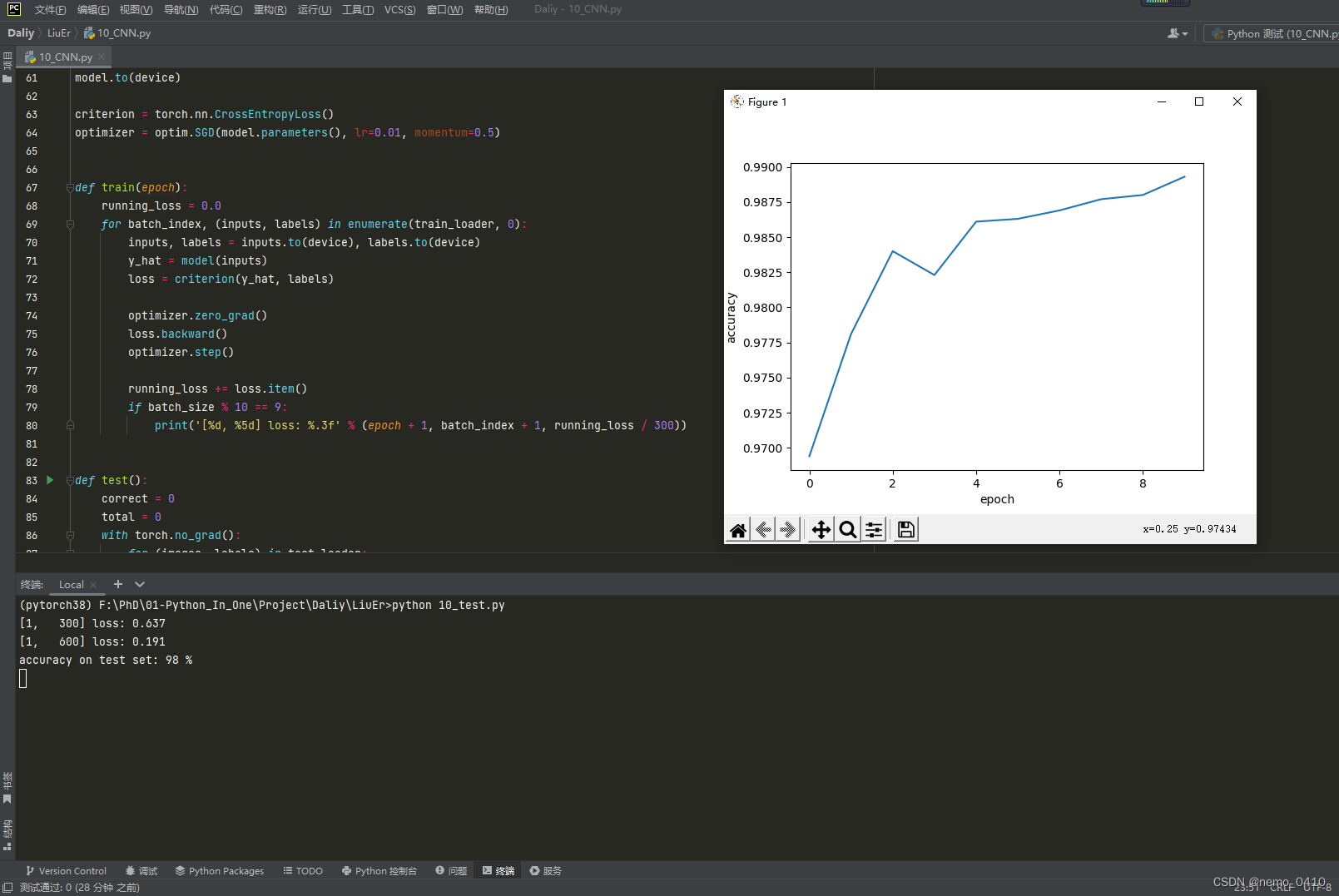
相关知识:
x.view的使用用法:【PyTorch中的view()函数用法示例及其参数详解】
2. Advanced CNN 卷积神经网络 高级
写在前面:
- 这是刘老师课程的最后一讲,RNN与我关系不大我也没看;
- 课程中讲了
GoogLeNet和ResNet两个网络的基本情况和简单的代码实现,在这里记录一下:
详细记录:
- 进入高阶
CNN,刘老师在这节课里讲了两个网络,一个是GoogLeNet,另一个是ResNet。分别记录重点:GoogLeNet:以往无论的LinearModel还是SoftmaxClassifier,其网络结构都是一个线性且没有‘岔路’的传递形式,成为单线结构,但效果一般;GoogLeNet是一种串行结构的复杂网络;想要实现复杂网络,并且较少代码冗余和多次重写相同功能的程序,面向过程的语言使用函数,面向对象的语言python使用类,而在CNN当中,使用Module和block这种模块将具有复用价值的代码块封装成一块积木,供拼接使用;GoogLeNet为自己框架里被重复使用的Module命名为Inception,这也电影盗梦空间的英文名,意为:梦中梦、嵌套;GoogLeNet设计了四条通路支线,并要求他们保证图像的宽和高W、H必须相同,只有通道数C可以不相同,因为各支线进行过卷积和池化等操作后,要将W和H构成的面为粘合面,按照C的方向,拼接concatenate起来;GoogLeNet的设计思路是:我把各种形式的核都写进我的Block当中,至于每一个支路的权重,让网络训练的时候自己去搭配;1 * 1的卷积核:以往我只是表面上觉得,单位像素大小的卷积核,他的意义不过是调整输入和输出的通道数之间的关系;刘老师举了个例子,让我对这个卷积核有了新的认识:就是加速运算,他的作用的确是加速运算,不过其中的原理是:通过1*1的核处理过的图像,可以减少后续卷积层的输入通道数;

GoogLeNet代码当中需要注意的是卷积层的输入和输出通道数,里面涉及的细节与其他层之间的差异要特别注意;- 最后在
cancatenate的时候,有一个参数是选择按照什么方向进行组合,这里的dim=1的原理在这:(B,C,W,H)按索引来讲,C指的是通道数,索引从零开始,C的位置是1,这个问题困扰了我好久,我一直都以为要死记硬背; GoogLeNet最后留下了一个问题:通过测试,网络的层数会影响模型的精度,但当时没有意识到梯度消失的问题,所以GoogLeNet认为We Need To Go Deeper;直到何凯明大神的ResNet的出现,提出了层数越多,模型效果不一定越好的问题,并针对这个问题提出了解决方案ResNet网络结构。ResNet之前,有过对梯度消失的解决方案:逐层训练。每当网络想要训练新一层的权重,就将其他层的权重锁住,逐渐将所有层的权重都确定下来,然而神经网络层数太多不容易做到,并且这也太蠢了,失去了人工智能的该有的智能;- 于是
ResNet提出了这样一种方式,来避免深度神经网络在训练过程中出现梯度消失导致靠前面的层没有被充分训练: - 以往的网络模型是这种
Plain Net形式:输入数据x,经过Weight Layer(可以是卷积层,也可以是池化或者线性层),再通过激活函数加入非线性影响因素,最后输出结果H(x);这种方式使得H(x)对x的偏导数的值分布在(0,1)之间,这在反向传播、复合函数的偏导数逐步累乘的过程中,必然会导致损失函数L对x的偏导数的值,趋近于0,而且,网络层数越深,这种现象就会越明显,最终导致最开始的(也就是靠近输入的)层没有获得有效的权重更新,甚至模型失效; ResNet采用了一个非常巧妙的方式解决了H(x)对x的偏导数的值分布在(0,1)之间这个问题:在以往的框架中,加入一个跳跃,再原有的网络输出F(x)的基础上,将输入x累加到上面,这样一来,在最终输出H(x)对输入数据x求偏导数的时候,这个结果就会分布在(1,2)之间,这样就不怕网络在更新权重梯度累乘的过程中,出现乘积越来越趋于0而导致的梯度消失问题;- 与
GoogLeNet类似,ResNet的Residual Block在搭建时,留了一个传入参数的机会,这个参数留给了通道数channel,Residual Block的要求是输入与输出的C,W,H分别对应相同,B是一定要相同的,所以就是说,经过残差模块Residual Block处理过的图像,并不改变原有的尺寸和通道数;(TBD) - 其余就是老生常谈的参数问题,记准每一个参数的含义;
- 课程最后刘老师推荐了两篇论文:
Identity Mappings in Deep Residual Networks:其中给出了很多不同种类的Residual Block变化的构造形式;Densely Connected Convolutional Networks:大名鼎鼎的DenseNet,这个网络结构基于ResNet跳跃传递的思想,实现了多次跳跃的网络结构,以后很多通过神经网络提取多尺度、多层级的特征,都在利用这种方式,通过Encoder对不同层级的语义特征进行逐步提取,在穿插着传递到Decoder过程中不同的层级上去,旨在融合不同层级的特征,尽可能地挖掘图像全部的特征;
GoogLeNet 的完整代码:
# advanced CNN
import torch
from torch import nn, optim
import torch.nn.functional as F
from torchvision import datasets # dataset 引用位置
from torch.utils.data import DataLoader # DataLoader 引用位置
from torchvision import transforms
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='../dataset/mnist', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
class InceptionA(torch.nn.Module):
def __init__(self, in_channels):
super(InceptionA, self).__init__()
self.branch1x1 = nn.Conv2d(in_channels, 16, kernel_size=1) # 乘号用字母x代替;
self.branch5x5_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_2 = nn.Conv2d(16, 24, kernel_size=5, padding=2)
self.branch3x3_1 = nn.Conv2d(in_channels, 16, kernel_size=1) # 第一个卷积核都是1x1,这个东西是减少操作数的,为了加速运算
self.branch3x3_2 = nn.Conv2d(16, 24, kernel_size=3, padding=1)
self.branch3x3_3 = nn.Conv2d(24, 24, kernel_size=3, padding=1)
self.branch_pool = nn.Conv2d(in_channels, 24,
kernel_size=1) # branch 这个词儿,在S2D引用的laina的代码里见过,一个是upper——branch,一个是bottom——branch;
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
output = [branch1x1, branch5x5, branch3x3, branch_pool]
return torch.cat(output, dim=1)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(88, 20, kernel_size=5)
self.incep1 = InceptionA(in_channels=10)
self.incep2 = InceptionA(in_channels=20)
self.mp = nn.MaxPool2d(2)
self.fc = nn.Linear(1408, 10)
def forward(self, x):
in_size = x.size(0)
x = F.relu(self.mp(self.conv1(x)))
x = self.incep1(x)
x = F.relu(self.mp(self.conv2(x)))
x = self.incep2(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('accuracy on test set: %d %% ' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
运行结果(截图时仍在运行):
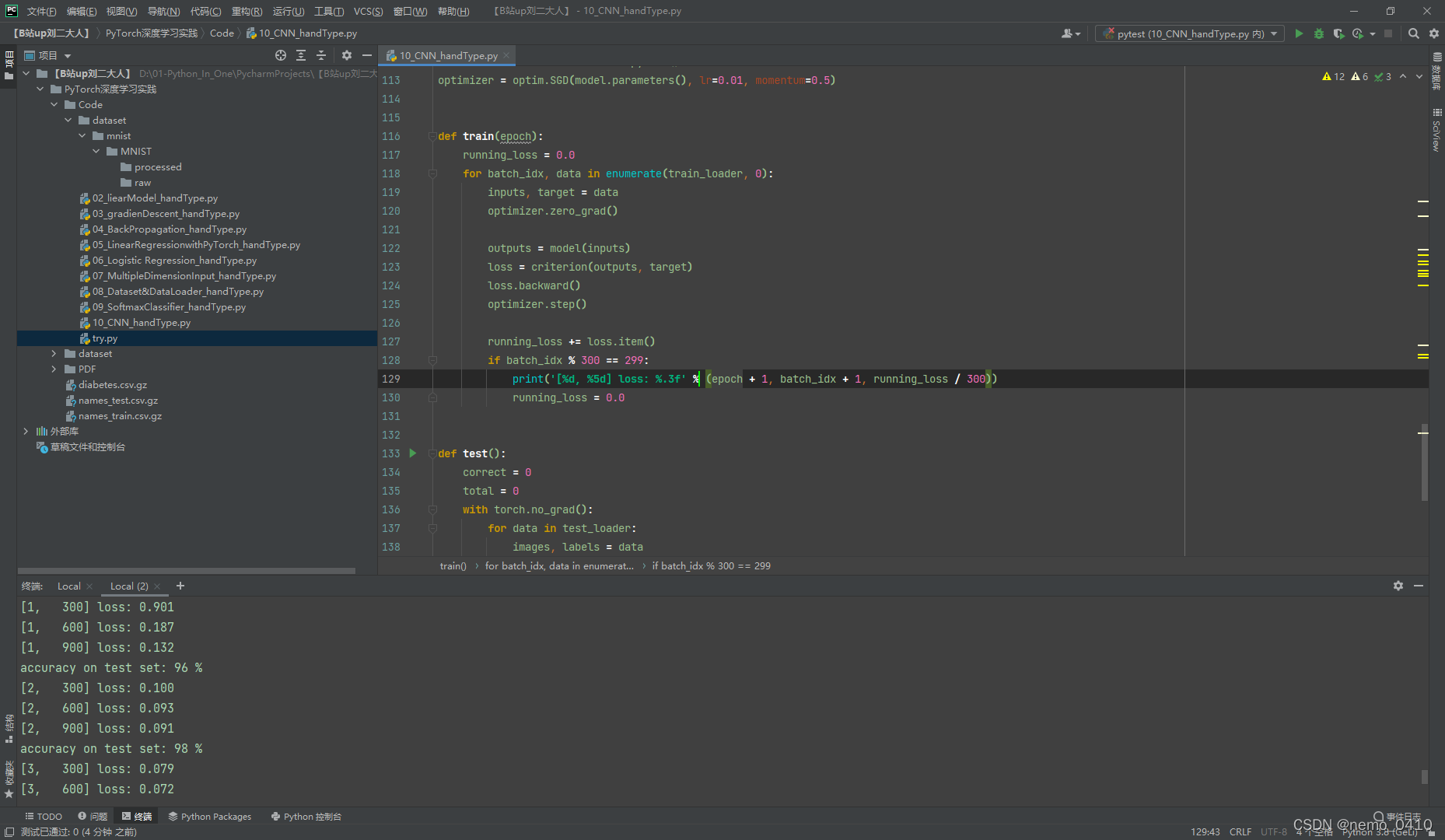
ResNet 的完整代码:
# ResNet
import torch
from torch import nn, optim
from torchvision import datasets
from torch.utils.data import DataLoader
from torchvision import transforms
import torch.nn.functional as F
batch_size = 64
transforms = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081))])
train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transforms)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist', train=True, download=True, transform=transforms)
test_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
class ResidualBlock(nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.channels = channels
self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
def forward(self, x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
return F.relu(x + y)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=5)
self.conv2 = nn.Conv2d(16, 32, kernel_size=5)
self.mp = nn.MaxPool2d(2)
self.rbloch1 = ResidualBlock(16)
self.rbloch2 = ResidualBlock(32)
self.fc = nn.Linear(512, 10)
def forward(self, x):
in_size = x.size(0)
x = self.mp(F.relu(self.conv1(x)))
x = self.rbloch1(x)
x = self.mp(F.relu(self.conv2(x)))
x = self.rbloch2(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_size + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('accuracy on test set: %d %% ' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
运行结果(截图时仍在运行):
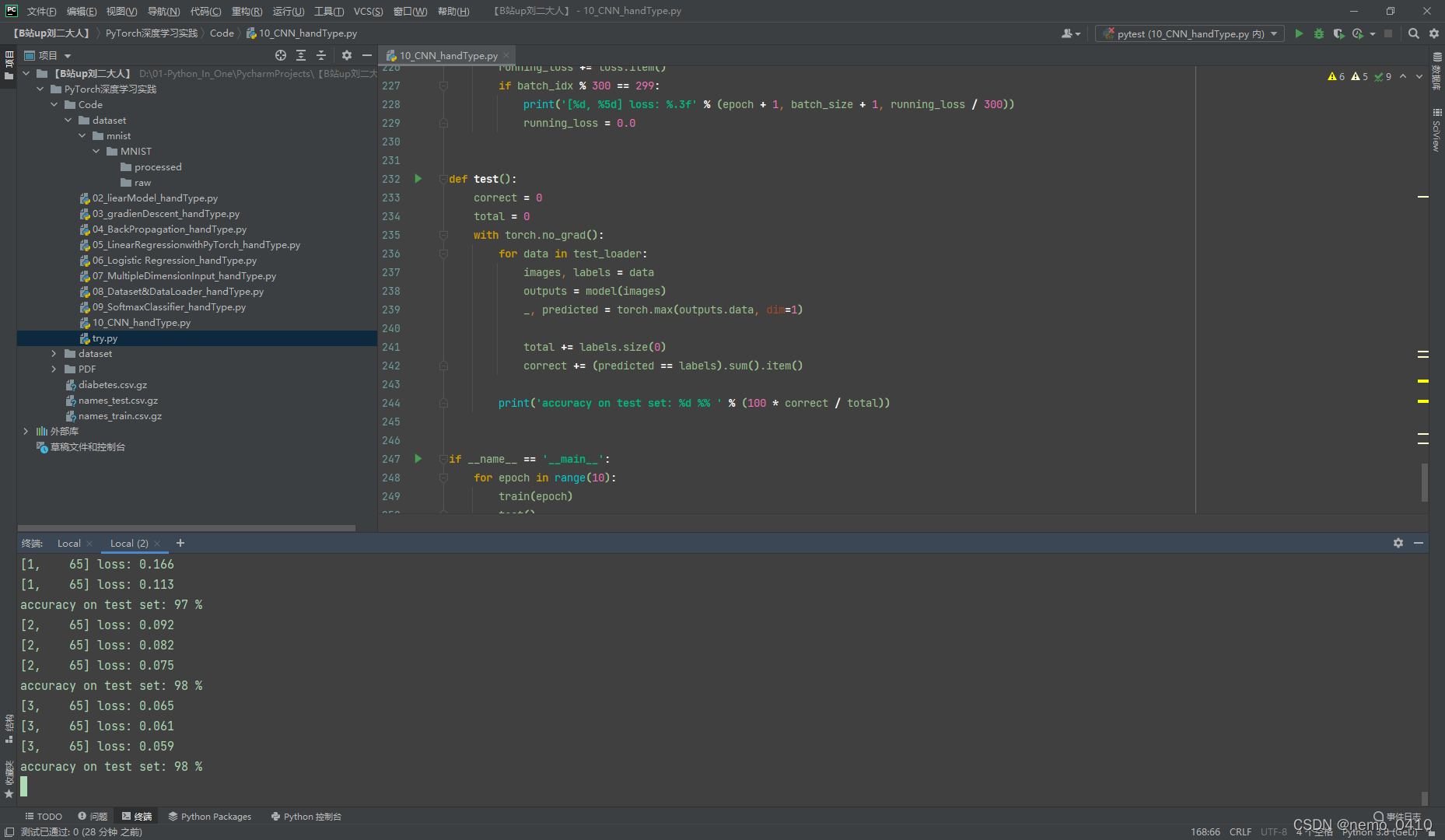
上一篇:
【Pytorch深度学习实践】B站up刘二大人之SoftmaxClassifier-代码理解与实现(8/9)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









