







目录
一、概述
该论文提出了一种名为Scene123的3D场景生成框架,并结合了视频生成框架作为assist,以及增强一致性的MASK Auto Encoder(MAE)。实现从单个输入图像或文本提示到生成逼真且一致的3D场景。大量实验表明,Scene123在表面重建精度、视图真实性和纹理质量方面优于现有的最先进方法。
(1)使用视频生成模型来增强生成场景的真实性和多样性。
(2)设计一种增强一致性的MAE来填充新视图中未见的区域,同时保持几何一致性。
(3)采用基于GAN的损失函数进一步提高生成场景的细节和纹理保真度。

二、相关工作
1、文本到三维场景的生成
由于缺乏成对的text-to-3d场景数据,大多数研究使用CLIP或者预训练的文本到图像模型来解释文本输入。
Text2Scene使用CLIP从文本/图像输入中来风格化3D场景。
Set-the-Scene和Text2NeRF通过T2I扩散模型中生成多视图,并生成NeRF。
SceneScape和Text2Room通过预训练的单目深度估计模型来增强几何一致性,并直接生成场景的三维纹理网格表示。
上述但这些方法保证了真实视觉效果,却存在有限的三维一致性。
利用辅助输入的方法例如layouts,保证了三维模型与图像紧密相连,学习物体在场景中的布局。
另外PixelSynth、GAUDI、WorldSheet这些收到生成质量和场景可扩展性限制。
2、图像到3D场景生成
PERF通过单张全景图像生成场景,用扩散模型补充阴影部分。
ZeroNVS从单个图像中重建三维场景,扩展了之前的要求,但缺乏一些细节。
LucidDreamer和WorldJourney利用通用的深度估计模型将存在幻觉的2D场景project到3D表示中。
但这些方法要么依赖预训练的模型,产生伪影,要么不容易实现真实性的场景,比较超现实。
3、视频扩散模型和3D-aware GANs
SD和SVD由于训练超大数据集LAION和LVD表现强大的泛化能力,一般用于各种生成任务的基础模型。
IM-3D和SV3D探索视频扩散模型在以对象为中心的多视图生成的能力。
V3D将上述方法扩展到场景级视图合成。
然后面对场景和对象复杂情况,上述视频扩散模型表现出多视图的不一致性。
3D GANs方向更多关注基于点云、体素的无纹理几何形状生成,只能用于生成粗略的3D资产。
HoloGAN、GET3D、EG3D通过使用基于GAN的3D生成器,生成特定类别的纹理3D资产。GigaGAN中看到GANs相比DM更适合高频细节。
其中近期的IT3D引入Diffusie-GAN双重训练策略,克服视图不一致,但GAN的训练不可避免存在模式崩溃问题。
三、Method
1、完整框架
Scene123包括三个部分:场景初始化,增强一致性的MAE,视频辅助的3D-Aware生成精炼模块。
场景初始化:首先输入文本或图像,(文本)经过SD2生成图像,图像经过单目深度估计器得到深度图。
增强一致性的MAE:通过基于DIBR渲染得到额外视角下的深度图以及RGB图(此时是扭曲的,但没有补充空白的区域),并经过masked VQ-VAE得到补充后的图像,此时就是多视图。并通过NeRF生成一个三维模型并渲染多视角图像。
视频辅助的3D-Aware生成精炼模块:通过将输入图像经过一个VDM得到多帧的图像,并且与NeRF渲染出的图像进行GAN损失计算。
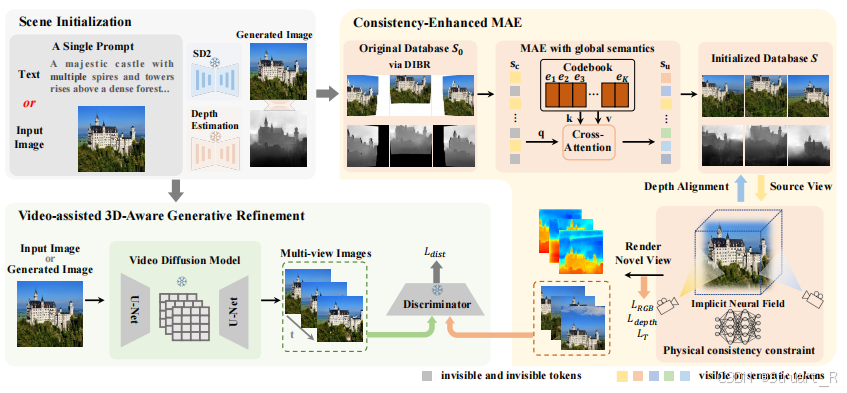
2、视频支持精炼模块
对于给定参考图像,使用SVD来生成视频。SVD的时间注意力层可以有助于生成视图一致的多视图生成,而无需任何显式3D结构。
引入鉴别器模块,设定视频帧的输出为真实数据,而NeRF渲染出的数据为假数据,学习两者之间的分布差异,计算鉴别器损失,有助于增强模型的生成能力。
另外论文中提出SVD模型的相机运动是有限的,不适合直接训练一个NeRF模型,所以用来鉴别器优化NeRF的生成过程。
3、渲染模块
在NeRF渲染模块引入了RGB损失、Depth损失、深度感知透视率损失,来监督渲染过程。其中
鼓励NeRF网络在相机射线到达预期深度
前产生空密度,防止存在更多冗余残影。
其中表示掩模,当透光距离
小于深度时,掩膜为1,
表示累积的透光率。
Scene123的总损失函数为:
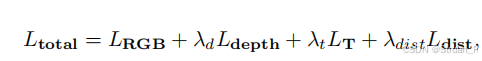
四、实验
输入为single view。

输入为text prompt。
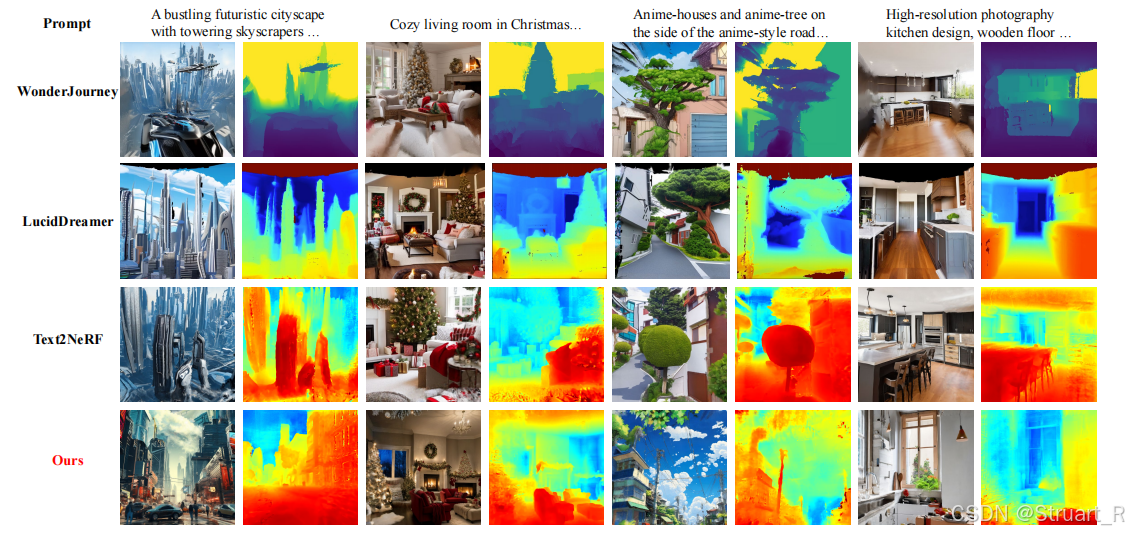
不同模型之间的视觉质量量化对比。

下面这个图可以看出,full model相比前面多了VDM-assist所以整体效果更好,MAE可以保证局部的三维一致性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









