







目录
一、摘要
Step-video-T2V是一个T2V模型,具有30B参数,能够生成最多204帧的视频(分辨率544*992),基于DiT模型设计,使用rectified flow进行训练,并在原有的VAE上实现了16x16的空间压缩比和8x的时间压缩比,包括两个双语文本编码器,能够直接理解中文或英文提示,引入了级联训练过程,包括文本到图像的预训练、文本到视频预训练、监督微调(SFT)、之际偏好优化(DPO),来加速模型收敛并充分利用不同质量的视频数据集。
另外引入了一个新的基准数据集Step-Video-T2V-Eval,包括11个类别中的128个不同的提示,以及来自几个顶级文本打视频开源和商业引擎的视频生成结果以供比较。
针对于视频基础模型,分为两个层级。
第一层级:翻译型视频基础模型,从文本、视觉、多模态上下文中生成视频。如Sora(openai)、Veo(Deepmind)、Kiling(kuaishou)、Hailuo(minimax)、Step-video。这些模型无法生成复杂动作序列(体操表演)、无法遵循物理定律(篮球在地面弹跳)的视频。更不能像LLM那样实现因果或逻辑任务。这种原因来自于:视频是文本提示的映射,而没有建模视频中的潜在因果关系。而基于自回归的T2V模型比如CogvideoX,虽然引入了因果建模机制,应该就是因果卷积,但是生成性能中难以达到扩散模型水平。
第二层级:预测型视频基础模型,根据文本、视觉、多模态上下文来预测未来事件,处理更高级的任务。未来的发展。
二、Step-Video-T2V
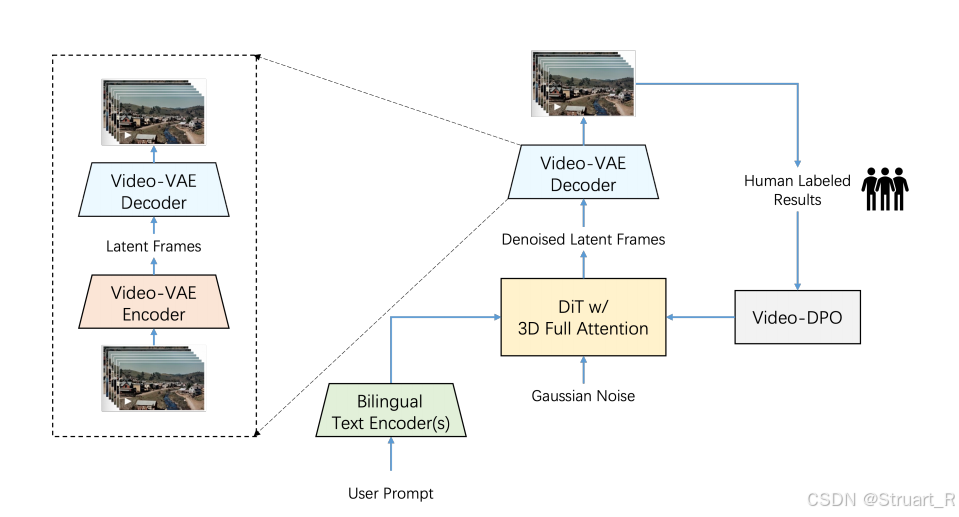
论文中Figure1的图表示了T2V的推理过程。
推理过程:输入User prompt(中或英),经过Bilingual Text Encoder得到tokens,并输入到DiT的cross-attention中,而DiT的输入是以往的gaussian noise,经过DiT的输出我们得到了denoised latent frames(也就是),之后我们经过Video-VAE Decoder得到视频帧。(到此为止,就是一般T2V模型的流程)。之后为了提高T2V的视觉质量,引入了一个人类反馈流程DPO,通过对比学习优化模型。
1、Video-VAE
以往的HunyuanVideo、CogvideoX和Meta Movie Gen都是通过使用空间时间下采样因子来对VAEs进行压缩的,但不同的是结构上,以往的都是级联3DConv,step-video用的是双路径的架构,双路径能有效分离高低频信息?(对于视频来说,高频是快速移动的物体,低频是缓慢移动的物体)
1.1双路径架构
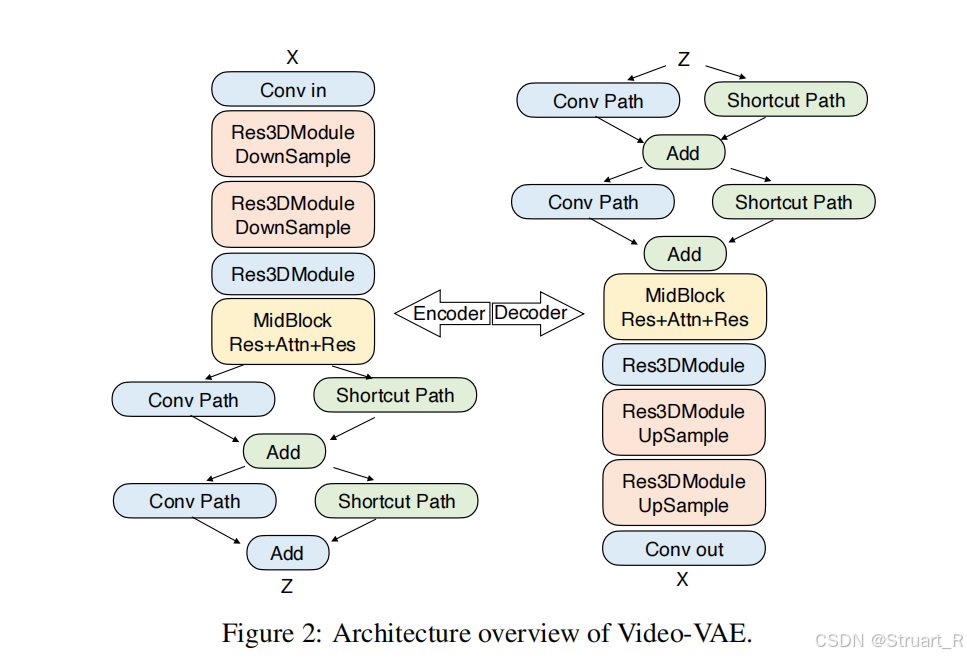
Video-VAE在编码器的后期和解码器的前期都进行了统一的空间-时间压缩,实现了8x16x16的下采样。编码器和解码器采用对称的设计。
整体架构如下:初始Conv(提取浅层信息),两层因果Res3Dblock+下采样(压缩时空维度,通过残差保留重要信息),MidBlock(引入注意力机制),双通道结构(分离高低频信息,高频信息通过卷积下采样,低频通过)
相比于以往的结构基本都是resblock进行downsample,那样做不断下采样会损失部分高频信息,解码过程时已经损失的信息完全不可逆,所以考虑在相对较小的像素下,展开双路径分离高低频信息。
双路径结构:一侧是因果卷积接像素重排作下采样提取高频信息,另一侧是通道平均接像素重排保证与左侧通道一直可以add,用极小的参数量提取低频信息
1.2解剖双路径架构
编码器部分
左侧:因果卷积(保证不泄露未来信息)+三维像素重排(时空维度压缩到通道维度,实现下采样,有点像patchify)
三维重排:
class ConvPixelUnshuffleDownSampleLayer3D(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size: int,
factor: int,
):
super().__init__()
self.factor = factor
out_ratio = factor**3
assert out_channels % out_ratio == 0
self.conv = CausalConv(
in_channels,
out_channels // out_ratio,
kernel_size=kernel_size
)
def forward(self, x: torch.Tensor, is_init=True) -> torch.Tensor:
x = self.conv(x, is_init)
x = self.pixel_unshuffle_3d(x, self.factor)
return x
@staticmethod
def pixel_unshuffle_3d(x: torch.Tensor, factor: int) -> torch.Tensor:
pad = (0, 0, 0, 0, factor-1, 0) # (left, right, top, bottom, front, back)
x = F.pad(x, pad)
B, C, D, H, W = x.shape
x = x.view(B, C, D // factor, factor, H // factor, factor, W // factor, factor)
x = x.permute(0, 1, 3, 5, 7, 2, 4, 6).contiguous()
x = x.view(B, C * factor**3, D // factor, H // factor, W // factor)
return x
右侧:像素重排(与左侧重排格式一致)+通道分组平均(保证输出的时空维度与左侧一致)
输入可能是(B,64,16,128,128),下采样因子为2,重排后为(B,512,8,64,64),假设group_size=2,那么每两个通道进行平均得到(B,256,8,64,64),这一步的目的就是为了降低计算量,防止参数爆炸。
class PixelUnshuffleChannelAveragingDownSampleLayer3D(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
factor: int,
):
super().__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.factor = factor
assert in_channels * factor**3 % out_channels == 0
self.group_size = in_channels * factor**3 // out_channels
def forward(self, x: torch.Tensor, is_init=True) -> torch.Tensor:
pad = (0, 0, 0, 0, self.factor-1, 0) # (left, right, top, bottom, front, back)
x = F.pad(x, pad)
B, C, D, H, W = x.shape
x = x.view(B, C, D // self.factor, self.factor, H // self.factor, self.factor, W // self.factor, self.factor)
x = x.permute(0, 1, 3, 5, 7, 2, 4, 6).contiguous()
x = x.view(B, C * self.factor**3, D // self.factor, H // self.factor, W // self.factor)
x = x.view(B, self.out_channels, self.group_size, D // self.factor, H // self.factor, W // self.factor)
x = x.mean(dim=2)
return x后续解码器的双路径结构就是对重排的逆操作。
另外论文中提到resnet中的groupnorm被空间groupnorm替换,来避免不同块之间的时间闪烁,但代码中仍然为一般的groupnorm(代码中看了一下)。
1.3训练细节
第一阶段,训练一个4x8x8压缩比的VAE不采用双路径结构
第二阶段,通过继续增加两个双路径模块来实现8x16x16的压缩,增强模型
整个训练过程中使用L1 reconstruction loss,Video-LPIPS,KL 散度约束模型,一旦这些损失收敛,就引入GAN损失进一步优化模型的性能。
2、Text Encoder
使用两种双语文本编码器来处理用户的文本提示Hunyuan-CLIP和Step-LLM,CLIP加LLM这应该是趋势了。
Hunyuan-CLIP:开源的双语CLIP模型双向文本编码器,由于CLIP模型训练机制,Hunyuan-CLIP可以生成视觉空间良好对齐的文本表示。最大输入长度限制为77个tokens,对于长文字量会遇到挑战。
Step-LLM:内部的单向的双语文本编码器,使用下一个token预测任务进行预训练。结合了Alibi-Positional Embedding,来提高序列处理的效率和准确性,没有输入长度限制,适合处理文本冗长的文本序列。
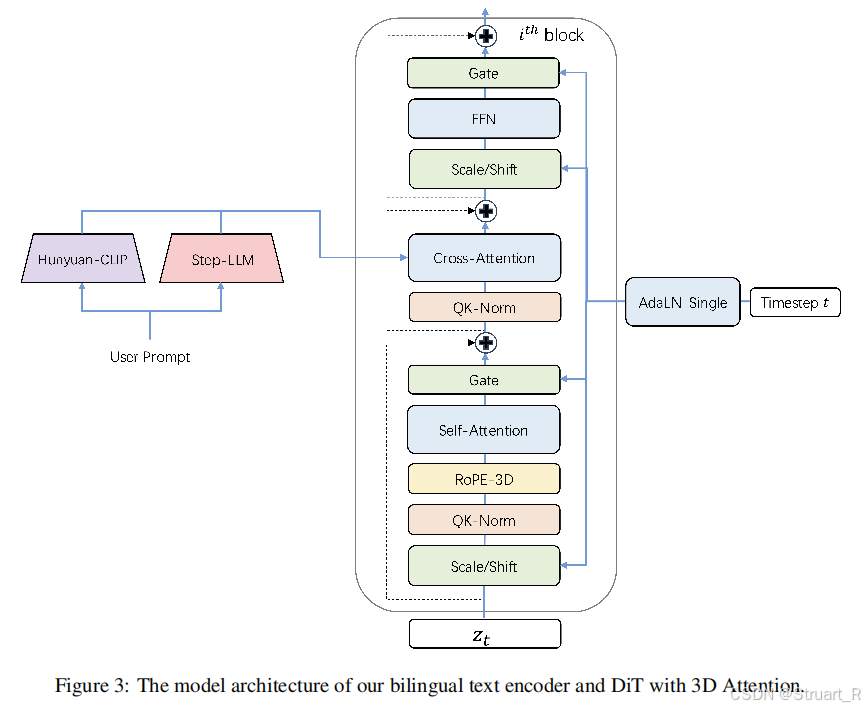
3、DiT
DiT的架构详细超参数。

一如既往地文本引入cross-attention,full-attention结构而不是时空注意力机制,timestep t经过AdaLN来指导scale/shift/gate。RoPE3D放在了自注意力机制后,之前一直疑惑他的位置放在那里,将位置编码成时间,高度、宽度三个维度,建模空间和时间上的一致性,相反没有用mmdit的双流形式,类似cogvideox。
不同的是使用了qk-norm作为归一化来稳定自注意力机制,这个没有太观察到。
对于Step-Video-T2V训练过程使用Flow Matching方法,就是最近替代以前加噪去噪的扩散模型的方法,详细过程等一下再看。简单来说,优点就是,计算效率高,生成质量好,长视频生成后运动一致性好。
4、Video-DPO
4.1DPO vs RLHF
DPO:Direct preference optimization直接偏好优化。
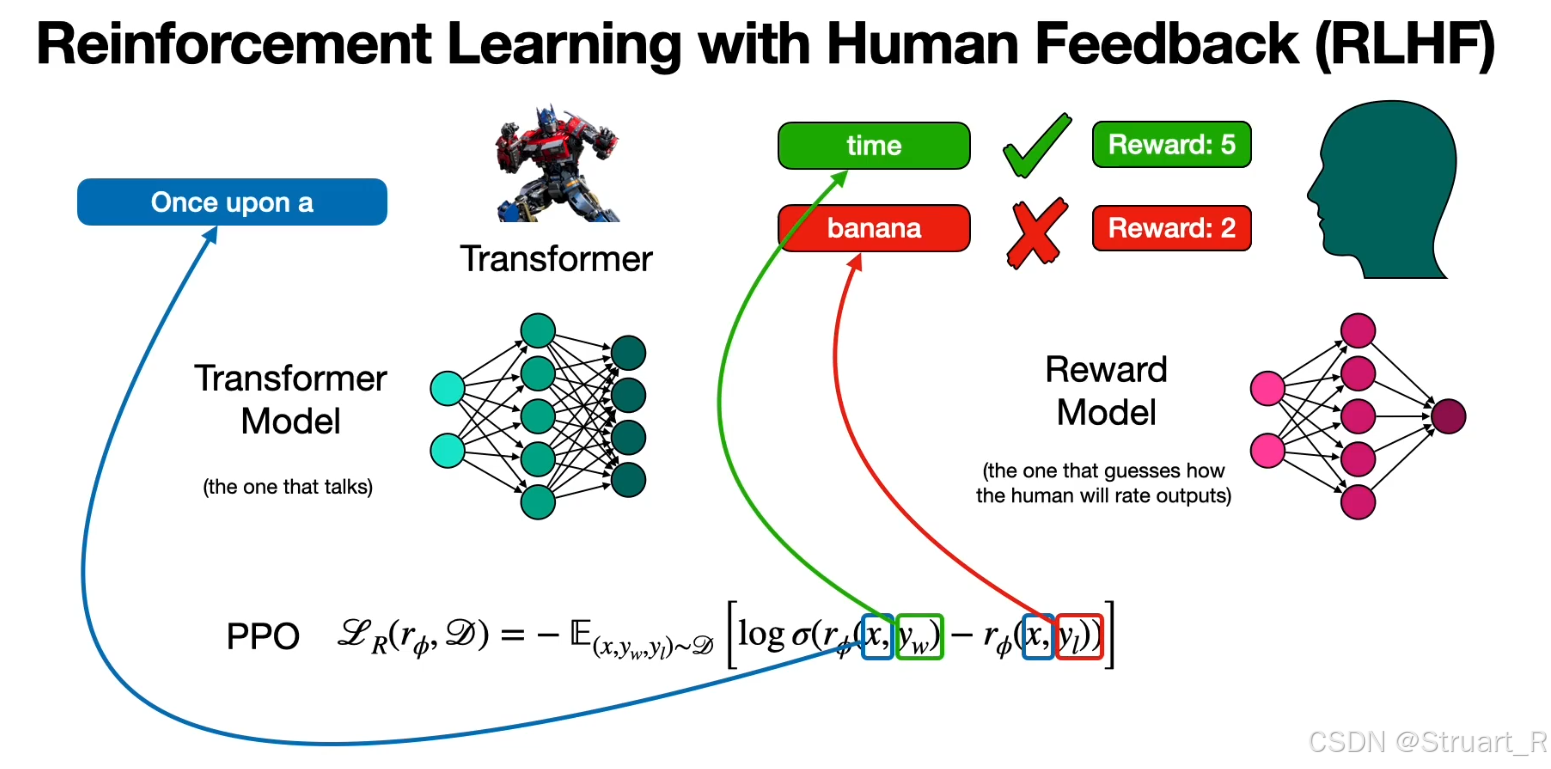
RLHF:Reinforcement learning with human feedback基于人类反馈强化学习。
讨论RLHF的具体用法,RLHF需要两个模型,奖励模型reward model和策略模型policy model,RLHF一共两步reward model的训练和policy model的优化。
reward model的训练过程:基于人类偏好数据集来训练。
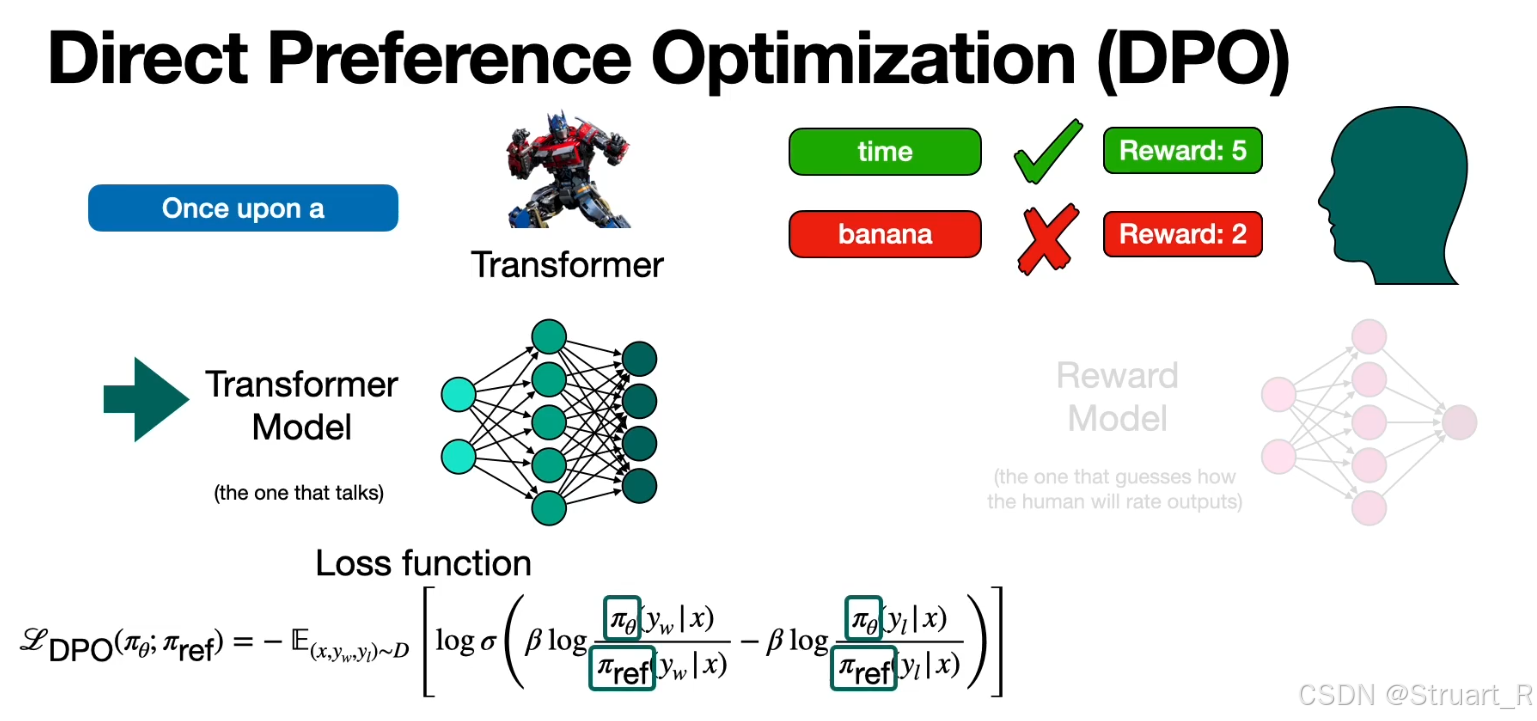
policy model的优化过程:首先明确一点policy model是已经训练好的,利用PPO算法,也就是下图的损失函数来进一步优化policy model。
比如下图利用transformer训练一个LLM,例如说我给他once upon a,他可以输出time。but 如何引入RLHF呢,我们可以让transformer输出不同的答案,此时利用人类反馈作为奖励机制,利用这种RLHF的方法设计一个损失函数,来优化transformer model。当transformer model输出time时,HF Reward:5;输出banana时,HF Reward:2。此时利用PPO算法(也就是下面那个损失函数)来计算损失,目的是更接近reward大的正确的回答,远离reward小的错误的回答。
DPO的原理:通过对比学习来隐式的学习人类的偏好。在DPO算法中我们不再需要Reward Model,而Reward Model并不是消失了而是以另一种形式——概率的方式存在。
DPO的步骤:仍然是两步,第一步我们收集人类偏好数据集(少量成对的数据集,比如视频A优于B这种),我们不需要训练一个Reward Model,这无疑不需要那么多的数据集(指RLHF用的多)。第二步利用对比损失方式来计算损失函数优化policy model。
人类偏好数据集
具体来说,time作为正确答案(y_win),banana作为错误答案
(y_lose),once upon a作为输入汉字x,在人类偏好数据集中
一定大于
,三元组就是这样得到的。
参考模型和待优化生成模型
的关系
这是通过SFT监督微调得到的初始模型,他是已知的,冻结参数的模型,也作为
的初始基准,他的目的是防止
过于偏离基准。
是当前训练的模型,通过参数
不断进行梯度下降更新,DPO初始化阶段
。
优化过程
冻结 :在DPO训练过程中,
的参数始终不变,仅作为概率计算的参考基准。
优化 :通过梯度下降更新 θ,使
逐渐适应人类偏好数据。
对于每个三元组样本,根据当前θ和冻结的计算
,并计算对θ的梯度
,并根据学习率η来更新θ。
。

DPO示意图。
也可以写作下面这种KL散度的形式,其中红框的网络是一个基于sigmoid的结构Bradley-Teddy Model,这里就不展开说了。
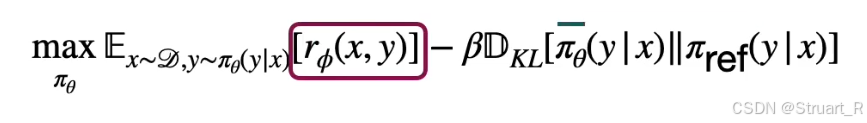
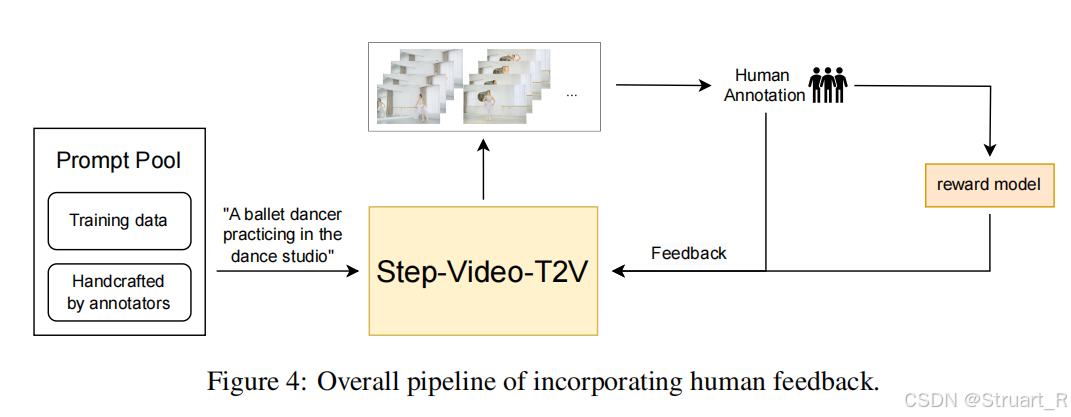
4.2Video-DPO的使用
人类偏好数据集中对视频的局部区域(如快速运动的物体)和全局运动轨迹(如摄像机移动)分别标注偏好。
对高动态场景(如爆炸、水流)使用更大的 β(如0.2),静态场景使用较小的 β(如0.05)。
下图就是使用了DPO后模型的优化前后对比。

三、Step-Video-T2V训练过程
1、T2I预训练
首先训练T2I模型,目的是从大规模图像数据中训练理解视觉概念,基于LAION数据集,利用图像扩散模型2D U-Net结构来训练。
2、T2VI预训练
在图像生成基础上引入视频数据,使模型学习时间动态(如运动轨迹、场景变换)。
阶段一:低分辨率训练(192x320)
训练运动动力学,如物体运动速度、方向变化,将2D U-Net扩展为3D结构(加入时间卷积层),时间维度压缩率8×。
阶段二:高分辨率训练(544x992)
细节生成(如纹理、光影、小物体运动)。引入动态上采样模块(Dynamic Upsampler),支持可变分辨率输入。
保留T2I工作的原因?
防止空间能力退化:混合训练保持模型对静态场景的理解,避免视频生成时空间细节丢失。
3、T2V微调
针对预训练数据的分布偏差(如风格不一、低质量视频),使用高质量视频数据微调模型。使用少量的文本-视频对,并删除T2I,允许模型进行微调和专门的文本到视频生成。
4、DPO训练
通过人类偏好数据优化生成视频的视觉质量和提示对齐性。
· 为了适应训练期间的不同视频的长度和宽高比,采用了可变长度和可变分辨率策略,定义了四个长度桶(1、68、136、204帧),根据视频长度动态调整潜在帧数量,另外根据最接近的高宽比设置了三个桶,横向、纵向、方形。

四、Flow Matching
Flow Matching,学习一个连续的向量场,将简单的高斯分布转换为复杂数据分布
。通过定义条件概率路径,使得模型生成的流,与目标流(真实数据分布的变化路径)相匹配。
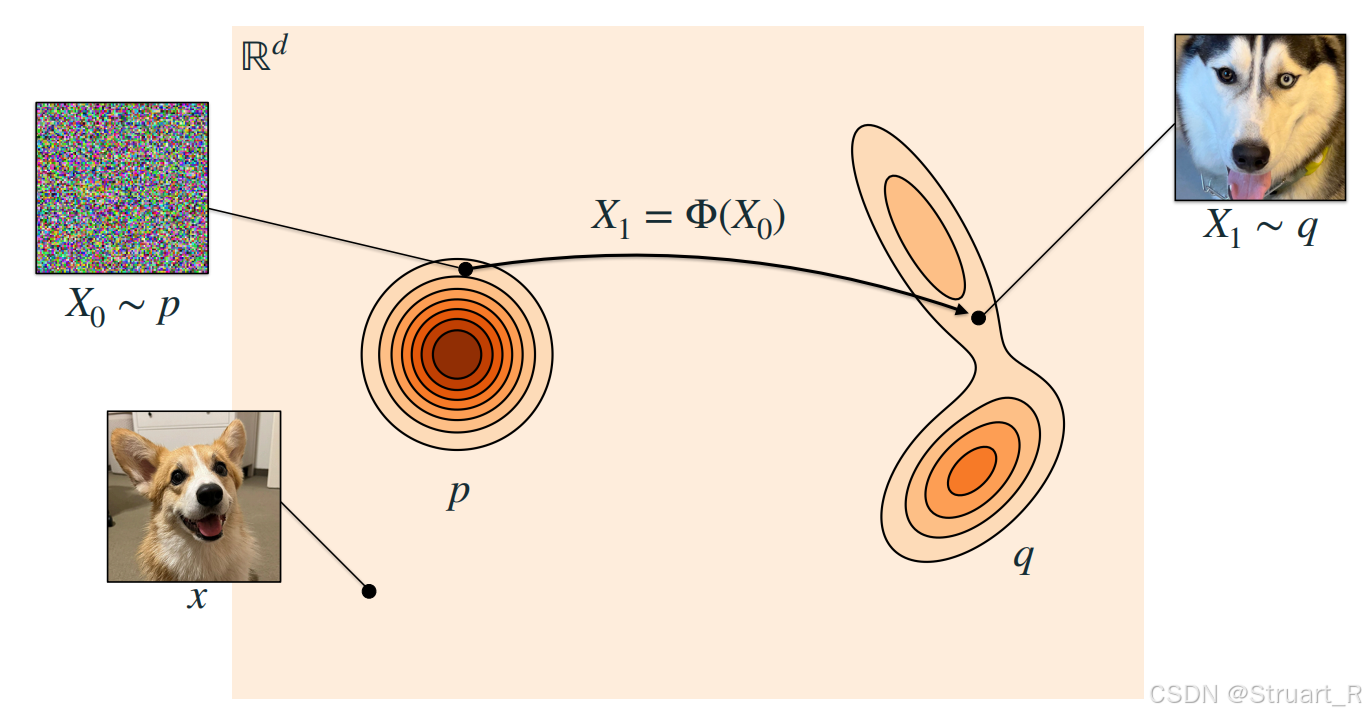
什么是流?
流的本质就是连续时间下从到
分布的轨迹变换,可以用常微分方程(ODE)描述:
是初始高斯分布,
是目标分布也就是真实数据分布。
是时间
时的样本,
也就是初始高斯分布中的任一样本点,
是目标数据。
是模型学习的向量场,就是初始高斯分布中所有的样本点移动到真实数据分布中的速度变化。
通过对速度模型进行积分(积分ODE模型)就可以得到一个路径,这个路径就是从初始噪声到目标数据
的路线。
Rectified流的实现方式
(1)定义条件路径:对于每一个目标样本x1,构造一条从噪声x0~p0到x1的直线路径。
(2)推导目标向量场:也就是计算条件路径下的导数。
(3)训练模型匹配目标场:使得初始模型拟合
,损失函数如下:
当这个模型训练完成,就可以生成从高斯分布p_0到真实数据分布p_1的流。
(4)生成样本过程:对初始分布采样x0~p_0,然后利用数值积分求解ODE。
实践过程中,利用欧拉法近似积分。
x = x0
for t in range(0, 1, dt):
dx = v_t(x) * dt # 模型预测的向量场
x = x + dx利用flow matching 从x0到x1的分布变化:
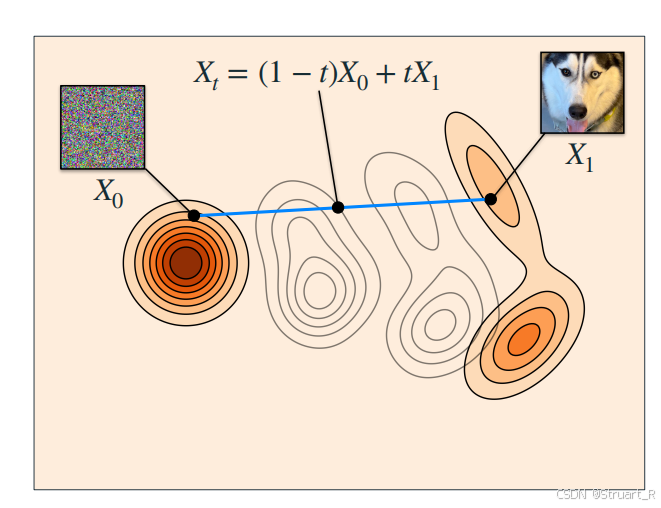
Flow matching相比于扩散模型和随机jump的直观实例如下:
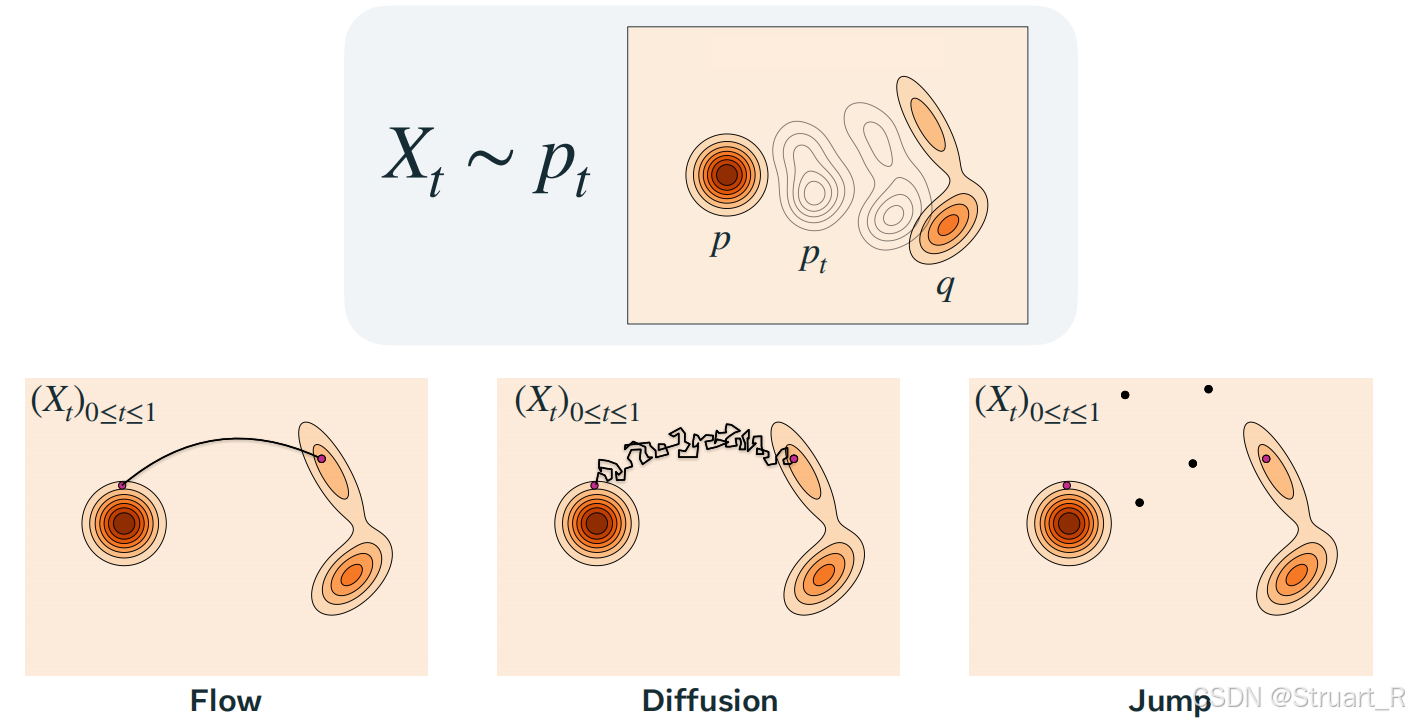
流与传统扩散模型的对比:
| 特性 | 扩散模型 | Rectified Flow |
| 训练目标 | 预测每一步添加的噪声 | 预测噪声到数据的直线偏移量 |
| 生成过程 | 多步迭代去噪(DDPM) | ODE求解(可实现一步或几步内生成) |
| 路径假设 | 基于随机扩散过程(SDE) | 确定性直线路径(ODE) |
| 损失函数 | 噪声预测的MSE损失 | 向量场匹配的MSE损失 |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









