







前言:
现在流行着一句话,遇事不要慌,朋友圈走一波。不知道还有多少人记得QQ空间,这可是QQ那个年代的青春啊,哎呀,不小心暴露了年龄。好了,废话不多说了,今天来教各位如何爬取QQ空间的信息。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块,并前往:
http://npm.taobao.org/mirrors/chromedriver/
下载与自己使用的Chrome浏览器版本对应的驱动文件,下载完毕后将chromedriver.exe所在文件夹添加到环境变量中即可。
原理简介
抓取点QQ空间的数据。
其主要思路为:
利用selenium模拟登录QQ空间从而获取登录QQ空间所需的cookie值,这样就可以利用requests模块来抓取QQ空间的数据了。
一些细节:
(1)第一次获取cookie之后将其保存下来,下次再登录之前先试试保存的cookie有没有用,有用直接使用就可以了,这样可以进一步节省时间。
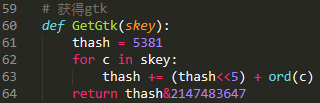
(2)抓包分析过程中,可以发现抓取QQ空间数据所需请求的链接都包含g_tk这个参数,这个参数实际上是使用cookie中的skey参数计算获得的:
最后:
抓取点数据看看吧
好吧,那就把:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1165
1165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









