







 本文通过随机森林和决策树在乳腺癌数据集上的应用,探讨了模型调参的重要性。实验显示随机森林在该数据集上表现优于单棵决策树。通过交叉验证和学习曲线,讨论了如何选择合适的`n_estimators`,并提出了根据数据规模来试探模型深度的策略。同时,引入了网格搜索方法来进一步优化模型参数。
本文通过随机森林和决策树在乳腺癌数据集上的应用,探讨了模型调参的重要性。实验显示随机森林在该数据集上表现优于单棵决策树。通过交叉验证和学习曲线,讨论了如何选择合适的`n_estimators`,并提出了根据数据规模来试探模型深度的策略。同时,引入了网格搜索方法来进一步优化模型参数。
from sklearn.model_selection import train_test_split
#划分30%的数据作为测试集
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data, wine.target, test_size=0.3)
clf = DecisionTreeClassifier(random_state=0) #建立模型: 决策树
rfc = RandomForestClassifier(random_state=0) #建立模型: 随机森林
clf = clf.fit(Xtrain, Ytrain) # 训练模型: 决策树
rfc = rfc.fit(Xtrain, Ytrain) # 训练模型: 随即森林
score_c = clf.score(Xtest, Ytest) #返回预测的准确度: 随机森林
score_r = rfc.score(Xtest, Ytest) #返回预测的准确度: 决策树
# 打印出准确度
print("single Tree:{}".format(score_c),
"Random Forest:{}".format(score_r))
single Tree:0.9444444444444444 Random Forest:0.9814814814814815
可见随机森林默认就比决策树准确度要高。
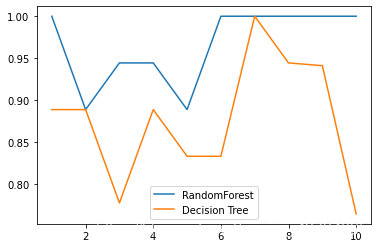
**4、画出随机森林和决策树在一组交叉验证下的效果对比**
> **交叉验证**
> 将数据集划分为n份,依次取每一份做测试集,每n-1份做训练集,多次训练模型以观测模型稳定性的方法
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
随机森林
rfc = RandomForestClassifier(n_estimators=25)
rfc_s = cross_val_score(rfc, wine.data, wine.target, cv=10)
决策树
clf = DecisionTreeClassifier()
clf_s = cross_val_score(clf, wine.data, wine.target, cv=10)
plt.plot(range(1,11), rfc_s, label = “RandomForest”)
plt.plot(range(1,11), clf_s, label = “Decision Tree”)
plt.legend()
plt.show()
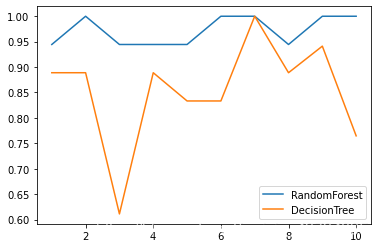
另一种更加简单有趣的写法:
label = “RandomForest”
for model in [RandomForestClassifier(n_estimators=25),DecisionTreeClassifier()]:
score = cross_val_score(model,wine.data, wine.target, cv=10)
print("{}:".format(label)),print(score.mean())
plt.plot(range(1,11),score,label = label)
plt.legend()
label = "DecisionTree"
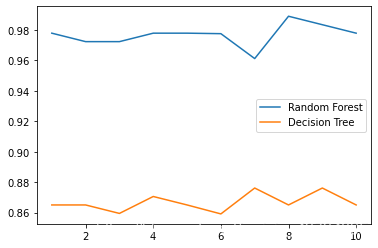
**5、画出随机森林和决策树在十组交叉验证下的效果对比**
rfc_l = []
clf_l = []
for i in range(10):
rfc = RandomForestClassifier(n_estimators=25)
rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean()
rfc_l.append(rfc_s)
clf = DecisionTreeClassifier()
clf_s = cross_val_score(clf,wine.data,wine.target,cv=10).mean()
clf_l.append(clf_s)
plt.plot(range(1,11), rfc_l, label=“Random Forest”)
plt.plot(range(1,11), clf_l, label=“Decision Tree”)
plt.legend()
plt.show()
**6、n\_estimators的学习曲线**
#####【TIME WARNING: 2mins 30 seconds】#####
superpa = []
for i in range(200):
rfc = RandomForestClassifier(n_estimators=i+1,n_jobs=-1)
rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean()
superpa.append(rfc_s)
print(max(superpa), superpa.index(max(superpa))) # 0.9888888888888889 53
plt.figure(figsize=[20,5])
plt.plot(range(1,201),superpa)
plt.show()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1037
1037

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









