







代码如下:
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
import matplotlib.pyplot as plt
if __name__ == '__main__':
wine=load_wine()
Xtrain,Xtest,Ytrain,Ytest=train_test_split(wine.data,wine.target,test_size=0.3)
rfc=RandomForestClassifier(n_estimators=25)
rfc_s=cross_val_score(rfc,wine.data,wine.target,cv=10)
knn=KNeighborsClassifier(n_neighbors=30)
knn_s=cross_val_score(knn,wine.data,wine.target,cv=10)
knn.fit(Xtrain,Ytrain)
rfc.fit(Xtrain,Ytrain)
plt.plot(range(1,11),rfc_s,label="RandomForest")
plt.plot(range(1,11),knn_s,label="KNN")
plt.legend()
plt.show()
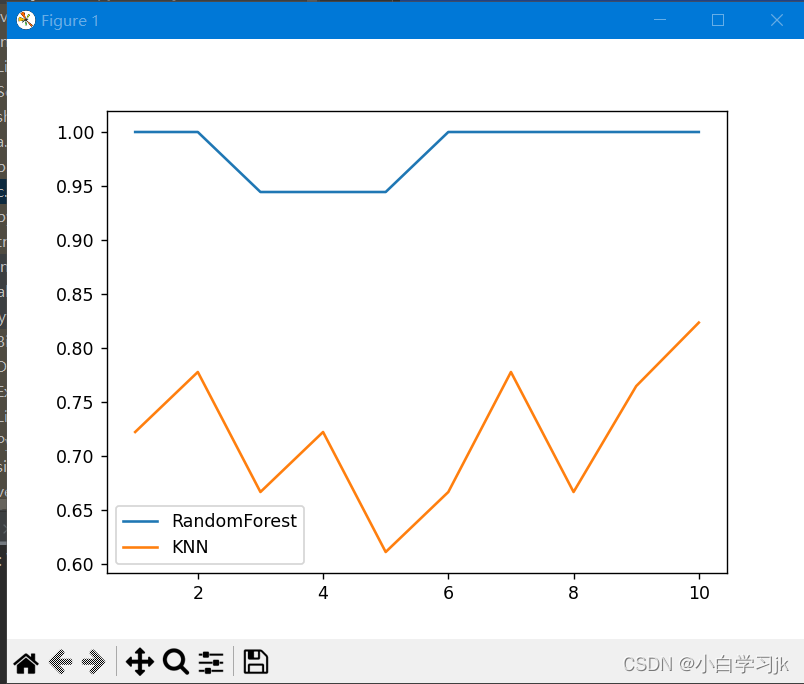
运行结果如下图:
















 1714
1714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











