







首先,我们先看下图,这是一张生产消息到kafka,从kafka消费消息的结构图。
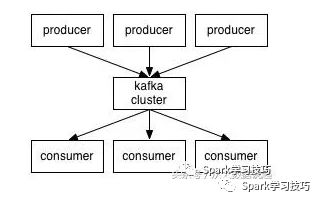
当然, 这张图很简单,拿这张图的目的是从中可以得到的跟本节文章有关的消息,有以下两个:
1,kafka中的消息不是kafka主动去拉去的,而必须有生产者往kafka写消息。
2,kafka是不会主动往消费者发布消息的,而必须有消费者主动从kafka拉取消息。
spark Streaming结合kafka
Spark Streaming现在在企业中流处理也是用的比较广泛,但是大家都知道其不是真正的实时处理,而是微批处理。
在spark 1.3以前,SPark Streaming与kafka的结合是基于Receiver方式,顾名思义,我们要启动1+个Receiver去从kafka里面拉去数据,拉去的数据会每隔200ms生成一个block,然后在job生成的时候,取出该job处理时间范围内所有的block,生成blockrdd,然后进入Spark core处理。
自Spark1.3以后,增加了direct Stream API,这种呢,主要特点是去掉了Receiver,在生成job,去取rdd的时候,计算每个partition要取数据的offset范围,然后生成一个kafkardd,该rdd特点是与kafka的分区是一一对应的。
有上面的特点可以看出,Spark Streaming是要生成rdd,然后进行处理的,rdd数据集我们可以理解为静态的,然每个批次,都会生成一个rdd,该过程就体现了批处理的特性,由于数据集时间段小,数据小,所以又称微批处理,那么就说明不是真正的实时处理。
还有一点,spark Streaming与kafka的结合是不会发现kafka动态增加的topic或者partition。
Spark的详细教程,请关注浪尖公众号,查看历史推文。
Spark Streaming与kafka结合源码讲解,请加入知识星球,获取。
flink结合kafka
大家都知道flink是真正的实时处理,他是基于事件触发的机制进行处理,而不是像spark Streaming每隔若干时间段,生成微批数据,然后进行处理。那么这个时候就有了个疑问,在前面kafka小节中,我们说到了kafka是不会主动往消费者里面吐数据的,需要消费者主动去拉去数据来处理。那么flink是如何做到基于事件实时处理kafka的数据呢?在这里浪尖带着大家看一下源码,flink1.5.0为例。
1,flink与kafka结合的demo。
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.getConfig.disableSysoutLogging
env.getConfig.setRestartStr
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7671
7671











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









