







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
最后的 ASSURED 就是该状态已经确认
[ASSURED]
nf_conntrack 是如何存储连接信息的
上面部分介绍了 nf_conntrack 模块的作用——追踪连接
接下来该介绍 nf_conntrack 模块是怎么存储这些 track 信息的
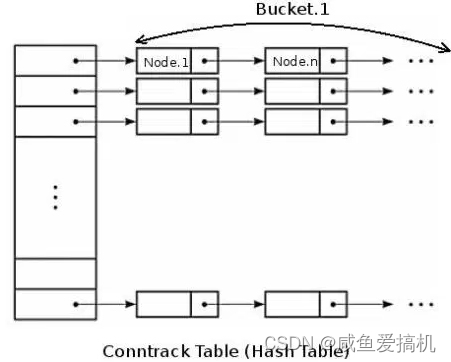
我们首先需要知道nf_conntrack将每一条连接信息都 track 到一个哈希表里面(hash table),一条 conntrack 连接信息也称条目(entry)
哈希表中的最小存储单位称作 哈希桶(bucket),哈希表的大小称作 HASHSIZE,所以哈希表有 HASHSIZE个 bucket
bucket 的大小对应 nf_conntrack 模块中的nf_conntrack_buckets值
而每个 bucket 包含一个链表(link list),每个链表都能够存放若干条 entry(bucket size)
nf_conntrack_max 则表示系统最大允许连接跟踪数,即 entry 的个数
#nf\_conntrack\_max等于 bucket 个数乘上每个 bucket 的大小
nf_conntrack_max = HASHSIZE * bucket size
当有新的数据包到来时,内核是如何判断这条连接信息是否被 track 到的
- 内核提取此数据包信息(源目IP,port,协议号)进行 hash 计算得到一个 hash 值,在哈希表中以此 hash 值做索引,索引结果为数据包所属的 bucket。这一步 hash 计算时间固定并且很短
- 遍历 hash 得到所属的 bucket,查找是否有匹配的 entry。这一步是比较耗时的操作,
bucket size越大,遍历时间越长 - 如果没有匹配到,则就新建
理想情况下,每个 bucket 下 link list 只存储一条 entry(即 bucket size = 1),这样查询效率是最高的,每次查询追踪记录的时候都是完美的 O(1) 的效率
但如果一个 bucket 存放一个 entry,这样会导致内存消耗非常大
官方指出:每个 entry 会占用大概 300 字节的空间,如果一个 bucket 存放一个 entry,那么整个哈希表的大小就等于总 entry 的大小
假设一个 bucket 存放一个 entry,我们设置 nf_conntrack_max == 12262144,就意味着哈希表可以存放12262144条 entry
这样我们会需要12262144308字节= 12262144308/(1024*1024) = 3508.22753906MB ,大约3个G的内存
一般服务器配置高点的,32G内存或者64G,光是给 connection track 就达到了 3G,更何况其中有些连接还是没有实际意义的已经被释放掉的 time_wait 的连接
那么一个 bucket 里应该存放多少条 entry 呢?
我们看下官方的解释,官方一般推荐一个 bucket 里存放四条 entry

nf_conntrack_max = nf_conntrack_buckets *4
如果一个 bucket 存放过多的 entry,就意味着每个 bucket 中的 link list 会非常长,会影响 hash 查询效率
所以一个 bucket 里存放四条 entry,兼顾时间和存储空间
3.解决问题
回到遇到的问题,既然报错是nf_conntrack: table full, dropping packet
那就意味着系统的连接跟踪表满了,我们有如下几种方法可选,请大家可以结合自己服务器情况来选择使用
- 关闭防火墙
对不直接暴露在公网,也不使用 NAT 转发的服务器来说,关闭 Linux 防火墙是最简单的办法,还能避免防火墙/ netfilter 成为网络瓶颈
#以 CentOS 7 为例
systemctl stop firewalld
systemctl disable firewalld
- 修改 iptables 规则
对于需要防火墙的机器,可以设置 NOTRACK 规则,减少要跟踪的连接数
对于一些不需要 track 的连接,针对对应的 iptables 规则加一个 notrack 的动作
# 表示凡是不跟踪的连接统统放行
# iptables 处理规则的顺序是从上到下,如果这条加的位置不对,可能导致请求无法通过防火墙
iptables -I INPUT 1 -m state --state UNTRACKED -j ACCEPT
-j notrack
把不需要 track 的 iptables 直接 notrack,那自然就不会去占 hashtable 空间了,更不会报错了
- 优化内核参数
一般来讲有下面两个逻辑:
- 哈希表扩容(
nf_conntrack_buckets、nf_conntrack_max) - 让哈希表里面的元素尽快释放(超时相关参数)
对于nf_conntrack_buckets 和 nf_conntrack_max的值,官方给了一个推荐大小
nf_conntrack_buckets - INTEGER
the default size is calculated by dividing total memory
by 16384 to determine the number of buckets but the hash table will
never have fewer than 32 and limited to 16384 buckets. For systems
with more than 4GB of memory it will be 65536 buckets.
This sysctl is only writeable in the initial net namespace.
nf_conntrack_max - INTEGER
Size of connection tracking table. Default value is
nf_conntrack_buckets value * 4
可以看到nf_conntrack_max与宿主机的内存相关,有个默认算法
#其中 x 为 CPU架构,值为 32 或 64
CONNTRACK_MAX = RAMSIZE (in bytes) / 16384 / (x / 32)
假设宿主机架构为 64 位且内存为 64GB,所以nf_conntrack_max值如下:
CONNTRACK_MAX = 64 * 1024 * 1024 * 1024 / 16384 / (64 / 32) = 2097152
又因为nf_conntrack_max = nf_conntrack_buckets value * 4
nf_conntrack_buckets = 2097152 / 4 = 524288
nf_conntrack_max = 2097152
nf_conntrack_buckets = 524288
PS:要根据自身服务器配置情况来进行配置,切勿一刀切!
对于超时时间,下列给出一些官方默认参数供大家参考,结合自身服务器情况进行修改
nf_conntrack_tcp_timeout_established:默认 432000 秒(5天)
代表 nf_conntrack 的 TCP 连接记录时间默认是五天,五天后该记录就被删除掉
攻击者可以根据这个参数,与你的服务器三次握手一建立就关闭 socket,分分钟把你的连接跟踪表打爆
net.netfilter.nf_conntrack_icmp_timeout:默认 30s
谁家 ping 等 30s 才算超时?
nf_conntrack_tcp_timeout_syn_sent:默认 120s
谁家程序的 connect timeout 需要 120s
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 823
823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









