







目录
4.1.4 std::recursive_timed_mutex
5. lock_guard 和 unique_lock(使用以及底层探索)
多线程是多任务处理的一种特殊形式,多任务处理允许让电脑同时运行两个或两个以上的程序。一般情况下,两种类型的多任务处理:基于进程和基于线程。
- 基于进程的多任务处理是程序的并发执行。
- 基于线程的多任务处理是同一程序的片段的并发执行。
多线程程序包含可以同时运行的两个或多个部分。这样的程序中的每个部分称为一个线程,每个线程定义了一个单独的执行路径。
Linux 操作系统,我们要使用 POSIX 编写多线程 C++ 程序。POSIX Threads 或 Pthreads 提供的 API 可在多种类 Unix POSIX 系统上可用,比如 FreeBSD、NetBSD、GNU/Linux、Mac OS X 和 Solaris。
在C++11之前,涉及到多线程问题,都是和平台相关的,比如windows和linux下各有自己的接口,这使得代码的可移植性比较差。C++11中最重要的特性就是对线程进行支持了,使得C++在并行编程时不需要依赖第三方库,而且在原子操作中还引入了原子类的概念。要使用标准库中的线程,必须包含< thread >头文件。
- 线程是操作系统中的一个概念,线程对象可以关联一个线程,用来控制线程以及获取线程的状态。
- 当创建一个线程对象后,没有提供线程函数,该对象实际没有对应任何线程。

1. pthread 和 thread的区别
std::thread是C++11接口,pthread是C++98接口且只支持Linux。C++的thread是经过良好设计并且跨平台的线程表示方式,然而pthread是“粗犷、直接、暴力”的类UNIX平台线程表示方式,如你在C++11的thread你可以使用lock_guard等来实现RAII方式的lock管理,而pthread则很难。
pthread是linux下的多线程API,头文件为pthread.hstd::thread是c++标准库中的线程库,其意义在于可以跨平台不改代码
- std::thread配合lambda表达式创建个线程运行,很方便!
- thread对象直接join或者detach,很方便!
- 使用thread再配合mutex的std::unique_lock和std::lock_guard使用,很方便!
- 使用thread再配合条件变量使用,很方便!
- 使用std::this_thread::sleep_for(xxx)休眠某段时间,很方便!
2. thread的使用
thread是一个类,可以通过创建类对象来创建一个新线程,并通过初始化来关联一个可执行对象,使线程完成特定的工作。
1. thread类是防拷贝的,不允许拷贝构造以及赋值,但是可以移动构造和移动赋值,即将一个线程对象关联线程的状态转移给其他线程对象,转移期间不影响线程的执行。
2. 可以通过jionable()函数判断线程是否是有效的,如果是以下任意情况,则线程无效
- 采用无参构造函数构造的线程对象
- 线程对象的状态已经转移给其他线程对象
- 线程已经调用jion或者detach结束
int main()
{
size_t n = 100;
thread t1([n]{
for (size_t i = 0; i < n; i += 2){
cout << i << endl;}
});
thread t2([n]{
for (size_t i = 1; i < n; i += 2){
cout << i << endl;}
});
t1.join();
t2.join();
return 0;
}2.1 线程函数
当创建一个线程对象后,并且给线程关联线程函数,该线程就被启动,与主线程一起运行。线程函数一般情况下可按照以下三种方式提供:
- 函数指针
- lambda表达式
- 函数对象
void ThreadFunc(int a)
{
cout << "Thread1" << a << endl;
}
class TF
{
public:
void operator()()
{
cout << "Thread3" << endl;
}
};
int main()
{
// 线程函数为函数指针
thread t1(ThreadFunc, 10);
// 线程函数为lambda表达式
thread t2([]{cout << "Thread2" << endl; });
// 线程函数为函数对象
TF tf;
thread t3(tf);
t1.join();
t2.join();
t3.join();
cout << "Main thread!" << endl;
return 0;
}
2.2 线程函数参数
线程函数的参数是以值拷贝的方式拷贝到线程栈空间中的,因此:即使线程参数为引用类型,在线程中修改后也不能修改外部实参,因为其实际引用的是线程栈中的拷贝,而不是外部实参。
void ThreadFunc1(int& x){
x += 10;}
void ThreadFunc2(int* x){
*x += 10;}
int main()
{
int a = 10;
//在线程函数中对a修改,不会影响外部实参,
//因为:线程函数参数虽然是引用方式,但其实际引用的是线程栈中的拷贝
thread t1(ThreadFunc1, a);
t1.join();
cout << a << endl;
// 如果想要通过形参改变外部实参时,必须借助std::ref()函数
thread t2(ThreadFunc1, std::ref(a));
t2.join();
cout << a << endl;
// 地址的拷贝
thread t3(ThreadFunc2, &a);
t3.join();
cout << a << endl;
}

2.3 join与detach:为了回收资源
启动了一个线程后,当这个线程结束的时候,如何去回收线程所使用的资源呢?thread库给我们两种选择:
(1)join()方式:
主线程被阻塞,当新线程终止时,join()会清理相关的线程资源,然后返回,主线程再继续向下执行,然后销毁线程对象。由于join()清理了线程的相关资源,thread对象与已销毁的线程就没有关系了,因此一个线程对象只能使用一次join(),否则程序会崩溃。但是,采用jion()方式结束线程时,jion()的调用位置非常关键,有可能发生函数返回了join没有调用,比如下面代码。为了避免该问题,可以采用RAII的方式对线程对象进行封装,比如
(2)detach()方式
该函数被调用后,新线程与线程对象分离,不再被线程对象所表达,就不能通过线程对象控制线程了,新线程会在后台运行,其所有权和控制权将会交给c++运行库。同时,C++运行库保证,当线程退出时,其相关资源的能够正确的回收。
总结:线程对象销毁前,要么以jion()的方式等待线程结束,要么以detach()的方式将线程与线程对象分离。
// jion()的误用一
void ThreadFunc() { cout<<"ThreadFunc()"<<endl; }
bool DoSomething() { return false; }
int main()
{
std::thread t(ThreadFunc);
if(!DoSomething())
return -1;
t.join();
return 0;
}
//说明:如果DoSomething()函数返回false,主线程将会结束,jion()没有调用,
//线程资源没有回收,造成资源泄漏。
// jion()的误用二
void ThreadFunc() { cout<<"ThreadFunc()"<<endl; }
void Test1() { throw 1; }
void Test2()
{
int* p = new int[10];
std::thread t(ThreadFunc);
try
{
Test1();
}
catch(...)
{
delete[] p;
throw;
}
t.jion();
}3. 原子性操作库(atomic)
多线程最主要的问题是共享数据带来的问题(即线程安全)。如果共享数据都是只读的,那么没问题,因为只读操作不会影响到数据,更不会涉及对数据的修改,所以所有线程都会获得同样的数据。但是,当一个或多个线程要修改共享数据时,就会产生很多潜在的麻烦。比如
std::mutex m;
unsigned long sum = 0;
void fun(size_t num)
{
for (size_t i = 0; i < num; ++i)
{
m.lock();//加锁
sum++;
m.unlock();//解锁
}
}
int main()
{
cout << "Before joining,sum = " << sum << std::endl;
thread t1(fun, 10000000);
thread t2(fun, 10000000);
t1.join();
t2.join();
cout << "After joining,sum = " << sum << std::endl;
}
虽然加锁可以解决,但是加锁有一个缺陷就是:只要一个线程在对sum++时,其他线程就会被阻塞,会影响程序运行的效率,而且锁如果控制不好,还容易造成死锁。因此C++11中引入了原子操作。所谓原子操作:即不可被中断的一个或一系列操作,C++11引入的原子操作类型,使得线程间数据的同步变得非常高效。以上代码可以优化为:
atomic<long> sum = 0;//这个可以把对sum的操作(++或—)变成原子操作
//atomic_long sum = { 0 };//这样写也可以
void fun(size_t num)
{
for (size_t i = 0; i < num; ++i)
sum++; // 这里对sum操作便是原子操作
}
int main()
{
cout << "Before joining, sum = " << sum << std::endl;
thread t1(fun, 1000000);
thread t2(fun, 1000000);
t1.join();
t2.join();
cout << "After joining, sum = " << sum << std::endl;
}在C++11中,程序员不需要对原子类型变量进行加锁解锁操作,线程能够对原子类型变量互斥的访问。更为普遍的,程序员可以使用atomic类模板,定义出需要的任意原子类型。
atmoic<T> t; // 声明一个类型为T的原子类型变量t
注意:原子类型通常属于"资源型"数据,多个线程只能访问单个原子类型的拷贝,因此在C++11中,原子类型只能从其模板参数中进行构造,不允许原子类型进行拷贝构造、移动构造以及operator=等,为了防止意外,标准库已经将atmoic模板类中的拷贝构造、移动构造、赋值运算符重载默认删除掉了。
#include <atomic>
int main()
{
atomic<int> a1(0);
//atomic<int> a2(a1); // 编译失败
atomic<int> a2(0);
//a2 = a1; // 编译失败
}
4. 互斥和同步
在多线程环境下,如果想要保证某个变量的安全性,只要将其设置成对应的原子类型即可,即高效又不容易出现死锁问题。但是有些情况下,我们可能需要保证一段代码的安全性,那么就只能通过锁的方式来进行控制。
4.1 互斥量(互斥锁)
多线程中对临界资源的访问会出现线程安全的问题,比如多个线程同时对一份资源进行写操作时,会造成数据混乱,因此引入了互斥的概念,即同一时刻只允许一个线程访问临界资源。互斥可以通过上锁和解锁来实现,在C++11中,Mutex总共包了四个互斥量的种类:
4.1.1 std::mutex
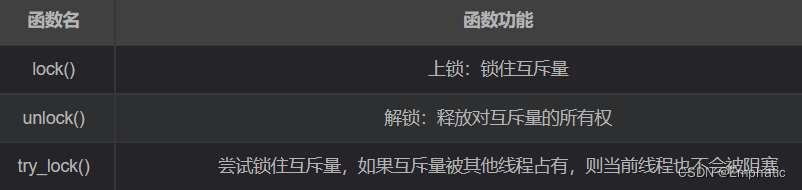
C++11提供的最基本的互斥量,该类的对象之间不能拷贝,也不能进行移动。mutex最常用的三个函数
4.1.2 std::recursive_mutex
其允许同一个线程对互斥量多次上锁(即递归上锁),来获得对互斥量对象的多层所有权,释放互斥量时需要调用与该锁层次深度相同次数的 unlock(),除此之外,std::recursive_mutex 的特性和std::mutex 大致相同。
4.1.3 std::timed_mutex
比 std::mutex 多了两个成员函数,try_lock_for(),try_lock_until() 。
- try_lock_for()
接受一个时间范围,表示在这一段时间范围之内线程如果没有获得锁则被阻塞住(与 std::mutex的 try_lock() 不同,try_lock 如果被调用时没有获得锁则直接返回 false),如果在此期间其他线程释放了锁,则该线程可以获得对互斥量的锁,如果超时(即在指定时间内还是没有获得锁),则返回 false。- try_lock_until()
接受一个时间点作为参数,在指定时间点未到来之前线程如果没有获得锁则被阻塞住,如果在此期间其他线程释放了锁,则该线程可以获得对互斥量的锁,如果超时(即在指定时间内还是没有获得锁),则返回 false。
4.1.4 std::recursive_timed_mutex
4.2 条件变量(同步)
条件变量是为了实现进程间同步(让进程按照一定的次序进行),具体用法可参照下面的例题交替打印。
C++11 提供了条件变量condition variable用于实现线程间的同步操作,需要包含头文件#include <condition_variable>,并且一般都是与互斥量mutex配合使用。
条件变量的工作方式为:
- 使用条件变量的线程首先对互斥量加锁
- 检查某个条件,如果条件不满足,则释放互斥锁量,进入休眠;如果条件满足,则继续执行资源操作,执行完操作后释放互斥量
- 另外一个线程加锁执行资源操作,使条件满足后,释放互斥量,唤醒等待的线程
5. lock_guard 和 unique_lock(使用以及底层探索)
直接使用mutex会有一些缺陷,锁控制不好时,可能会造成死锁,最常见的比如在锁中间代码返回,或者在锁的范围内抛异常,会造成资源浪费。因此:C++11采用RAII的方式对锁进行了封装,即lock_guard和unique_lock。
5.1 lock_guard
template<class _Mutex>
class lock_guard
{
public:
// 在构造lock_gard时,_Mtx还没有被上锁
explicit lock_guard(_Mutex& _Mtx)
: _MyMutex(_Mtx)
{
_MyMutex.lock();
}
// 在构造lock_gard时,_Mtx已经被上锁,此处不需要再上锁
lock_guard(_Mutex& _Mtx, adopt_lock_t)
: _MyMutex(_Mtx)
{}
// 在析构函数时,会自动解锁
~lock_guard() _NOEXCEPT
{
_MyMutex.unlock();
}
lock_guard(const lock_guard&) = delete;
lock_guard& operator=(const lock_guard&) = delete;
private:
_Mutex& _MyMutex;
};lock_guard类模板主要是通过RAII的方式,对其管理的互斥量进行了封装,在需要加锁的地方,只需要用上述介绍的任意互斥体实例化一个lock_guard,调用构造函数成功上锁,出作用域
前,lock_guard对象要被销毁,调用析构函数自动解锁,可以有效避免死锁问题。
//无论是正常执行、还是中途返回、还是抛异常,都能保证这里锁一定解锁了
mutex mtx;
lock_guard<mutex> lg(mtx);
FILE* fout = fopen("test.txt", "r");
if (fout == nullptr){
// ....}
//若只想让锁保护打开文件这段代码?可以定义一个匿名的局部域
{
mutex mtx;
lock_guard<mutex> lg(mtx);
FILE* fout = fopen("test.txt", "r");
if (fout == nullptr){
// ....}
}
5.2 unique_lock
与lock_guard不同的是,unique_lock更加的灵活,提供了更多的成员函数:
上锁/解锁操作:lock、try_lock、try_lock_for、try_lock_until和unlock,可以更加灵活
class LogFile {
std::mutex _mu;
ofstream f;
public:
LogFile() {
f.open("log.txt");
}
~LogFile() {
f.close();
}
void shared_print(string msg, int id) {
{
std::lock_guard<std::mutex> guard(_mu);
//do something 1
}
//do something 2
{
std::lock_guard<std::mutex> guard(_mu);
// do something 3
f << msg << id << endl;
cout << msg << id << endl;
}
}
};上面的代码中,一个函数内部有两段代码需要进行保护,这个时候使用lock_guard就需要创建两个局部对象来管理同一个互斥锁(其实也可以只创建一个,但是锁的力度太大,效率不行),修改方法是使用unique_lock。它提供了lock()和unlock()接口,能记录现在处于上锁还是没上锁状态,在析构的时候,会根据当前状态来决定是否要进行解锁(lock_guard就一定会解锁)。上面的代码修改如下:
class LogFile {
std::mutex _mu;
ofstream f;
public:
LogFile() {
f.open("log.txt");
}
~LogFile() {
f.close();
}
void shared_print(string msg, int id) {
std::unique_lock<std::mutex> guard(_mu);
//do something 1
guard.unlock(); //临时解锁
//do something 2
guard.lock(); //继续上锁
// do something 3
f << msg << id << endl;
cout << msg << id << endl;
// 结束时析构guard会临时解锁
// 这句话可要可不要,不写,析构的时候也会自动执行
// guard.ulock();
}
};上面的代码可以看到,在无需加锁的操作时,可以先临时释放锁,然后需要继续保护的时候,可以继续上锁,这样就无需重复的实例化lock_guard对象,还能减少锁的区域。同样,可以使用std::defer_lock设置初始化的时候不进行默认的上锁操作:
void shared_print(string msg, int id) {
std::unique_lock<std::mutex> guard(_mu, std::defer_lock);
//do something 1
guard.lock();
// do something protected
guard.unlock(); //临时解锁
//do something 2
guard.lock(); //继续上锁
// do something 3
f << msg << id << endl;
cout << msg << id << endl;
// 结束时析构guard会临时解锁
}6. 应用例题:
6.1 创建两个线程交替打印1,2...100
//只使用互斥量
int main()
{
int n = 100;
mutex mtx;
// 奇数 假设 thread2迟迟没创建好或者没有排到cpu时间片,就会导致t1连续打印奇数,不符合题意要求
thread t1([&](){
int i = 1;
for (; i < n; i += 2){
unique_lock<mutex> lock(mtx);
cout << i << endl;}
});
// 偶数
thread t2([&](){
int j = 2;
for (; j < n; j += 2){
unique_lock<mutex> lock(mtx);
cout << j << endl;}
});
t1.join();
t2.join();
}以上并不安全,有可能线程1打印了1,3,线程2才刚创建好,下面需要使用条件变量
//互斥量+条件变量
int main()
{
int n = 100;
mutex mtx;
condition_variable cv;
bool flag = true;
// 奇数
thread t1([&]() {
int i = 1;
while (i < n){
unique_lock<mutex> lock(mtx);
//wait的第二个参数为可执行对象,可以为lambda表达式
cv.wait(lock, [&flag]()->bool {return flag; }); // true 则不会阻塞,继续执行,
cout << i << endl;
i += 2;
flag = false;//通过flag来控制交替
cv.notify_one();}//唤醒其他在等待的条件变量
});
// 偶数
thread t2([&]() {
int j = 2;
while (j < n){
unique_lock<mutex> lock(mtx);
//wait的第二个参数为可执行对象,可以为lambda表达式
cv.wait(lock, [&flag]()->bool {return !flag; }); // false 释放互斥量,并阻塞休眠(注意:wait的时候会释放锁,所以wait函数才需要一个参数是lock)
cout << j << endl;
j += 2;
flag = true;
cv.notify_one();}
});
t1.join();
t2.join();
}6.2 交替打印数字和字符
#include <thread>
#include <mutex>
#include <condition_variable>
#include <iostream>
using namespace std;
mutex mtx;
condition_variable cv;
bool flag = true;
void print_num() {
for (int i = 1; i <= 26; i++) {
unique_lock<mutex> lock(mtx);
while(!flag)
cv.wait(lock);
cout << i << endl;
flag = false;
cv.notify_one();
}
}
void print_char() {
for (char i = 'a'; i <= 'z'; i++) {
unique_lock<mutex> lock(mtx);
while(flag)
cv.wait(lock);
cout << i << endl;
flag = true;
cv.notify_one();
}
}
int main() {
thread p1(print_num);
thread p2(print_char);
p1.join();
p2.join();
return 0;
}7. 补充:并发与并行的区别?
- 并行是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔发生。
- 并行是在不同实体上的多个事件,并发是在同一实体上的多个事件。
- 在一台处理器上“同时”(这个同时实际上市交替“”)处理多个任务,在多台处理器上同时处理多个任务















 1747
1747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









