







 本文分享了计网兴趣作业,包括仿写ping命令并实现可视化,详细介绍了实现思路、代码及运行结果。同时探讨了路由器中数据包的排队位置,分析了输入端口、交换结构和输出端口的排队情况,并讨论了路由器的排队规则。此外,还介绍了模拟路由器转发分组的实现。最后,提到了生成多项式的概念、由来、条件和讲究。
本文分享了计网兴趣作业,包括仿写ping命令并实现可视化,详细介绍了实现思路、代码及运行结果。同时探讨了路由器中数据包的排队位置,分析了输入端口、交换结构和输出端口的排队情况,并讨论了路由器的排队规则。此外,还介绍了模拟路由器转发分组的实现。最后,提到了生成多项式的概念、由来、条件和讲究。
1.仿写ping命令并实现可视化
1.1思路如下:
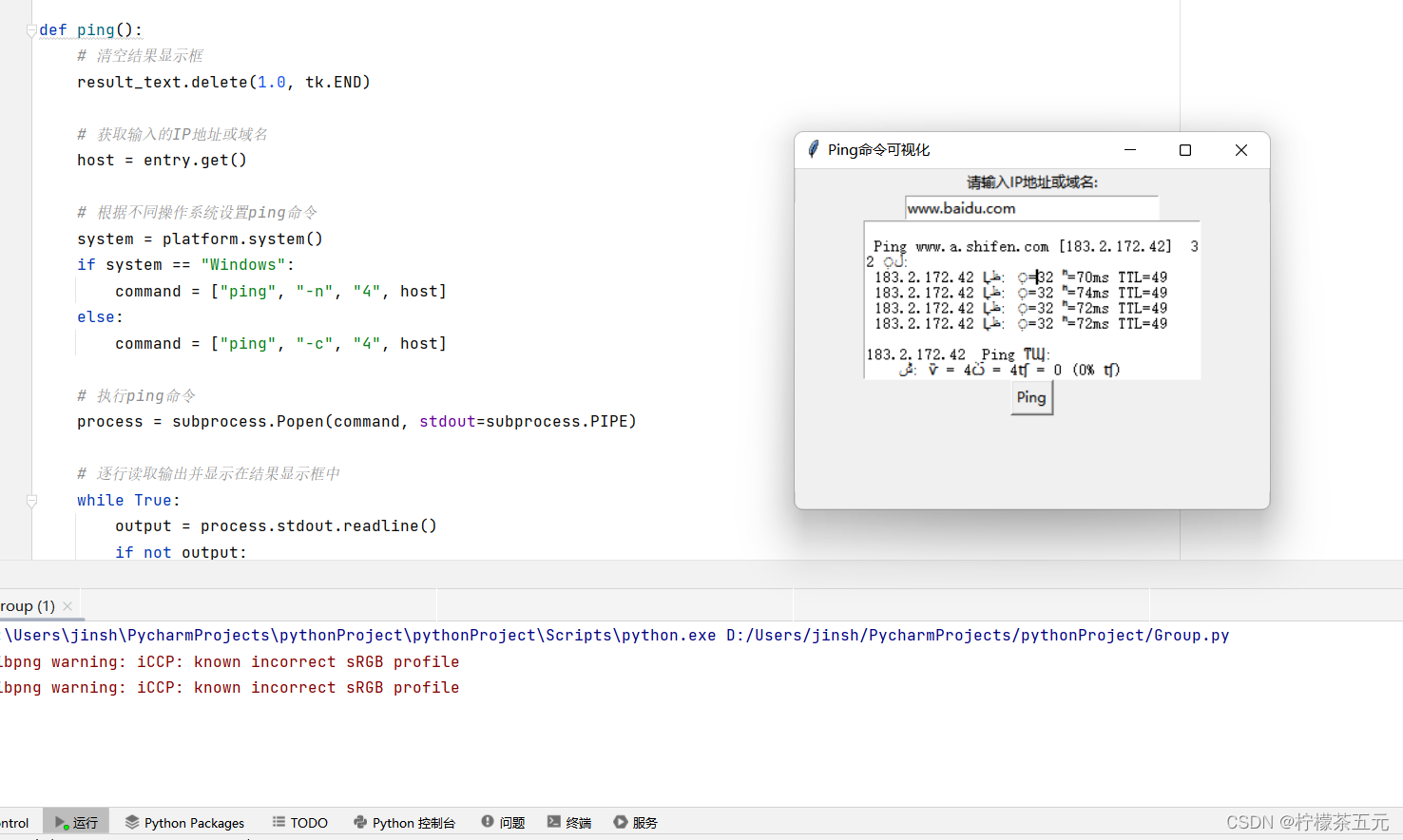
在代码中定义了一个名为ping的函数,用于执行ping命令。首先,函数会清空结果显示框。然后获取输入框中输入的IP地址或域名。根据不同的操作系统,设置不同的ping命令。使用subprocess模块的Popen方法执行ping命令,并将输出结果保存在process对象中。通过循环逐行读取输出结果,并将其插入到结果显示框中。创建了一个按钮,当点击该按钮时,会调用ping函数执行ping命令,最后一行的window.mainloop()用于运行主窗口,使程序进入消息循环,等待用户的操作。
1.2代码如下:
# -*-coding:utf-8 -*-
import os
import platform
import subprocess
import tkinter as tk
# 创建主窗口
window = tk.Tk()
window.title("Ping命令可视化")
window.geometry("400x300")
# 创建标签和输入框
label = tk.Label(window, text="请输入IP地址或域名:")
label.pack()
entry = tk.Entry(window, width=30)
entry.pack()
# 创建结果显示框
result_text = tk.Text(window, width=40, height=10)
result_text.pack()
def ping():
# 清空结果显示框
result_text.delete(1.0, tk.END)
# 获取输入的IP地址或域名
host = entry.get()
# 根据不同操作系统设置ping命令
system = platform.system()
if system == "Windows":
command = ["ping", "-n", "4", host]
else:
command = ["ping", "-c", "4", host]
# 执行ping命令
process = subprocess.Popen(command, stdout=subprocess.PIPE)
# 逐行读取输出并显示在结果显示框中
while True:
output = process.stdout.readline()
if not output:
break
result_text.insert(tk.END, output.decode("utf-8",errors='ignore'))
# 创建按钮
button = tk.Button(window, text="Ping", command=ping)
button.pack()
# 运行主窗口
window.mainloop()
1.3运行结果如下:
2.路由器中数据包排队的位置
数据包在路由器中排队的位置主要由路由器的结构决定,主要在以下位置:
-
输入端口的内存中
-
交换结构中(内存式交换)
-
输出端口中
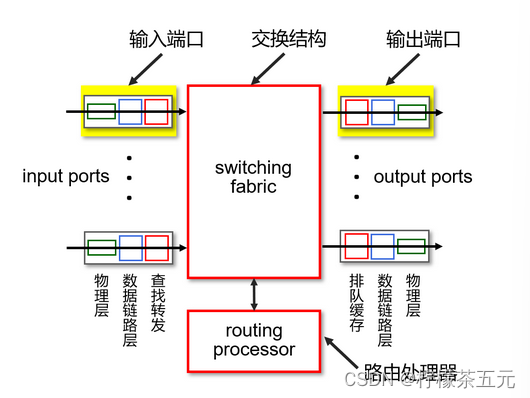
输入端口排队:
当交换结构的速度慢于输入端口的速度时,就会在输入端口的缓冲区发生排队。
会导致排队延时和由于输入缓冲区溢出导致的丢包!
线头阻塞:在队列前面的被阻塞的数据报会阻止队列中的其它数据报被转发。
交换结构:
对于某些路由器,数据包可能会被放置在交换结构的缓存区中进行临时存储和排队,等待进行输出操作。
输出端口排队:
当经过交换结构到达的速度快于输出端口的处理线速时,就会在输出端口的缓冲区发生排队。
当输出端口的缓冲区溢出时就会发生丢包!
排队的时间取决于多个因素,包括网络拥塞情况、数据包大小和路由器的处理能力等。
最长的排队时间是在网络非常拥塞且路由器处理能力不足的情况下,可能会出现排队延迟。
最短的排队时间是在网络畅通且路由器处理能力强大的情况下,数据包可以迅速得到处理。
因此为了减少排队速度,路由器会遵循不同的规则来确定保留哪些数据包以及丢弃哪些数据包,具体有以下重要的排队规则:
-
先进先出队列(FIFO)
-
优先排队(PQ)
-
加权公平排队(WFQ)
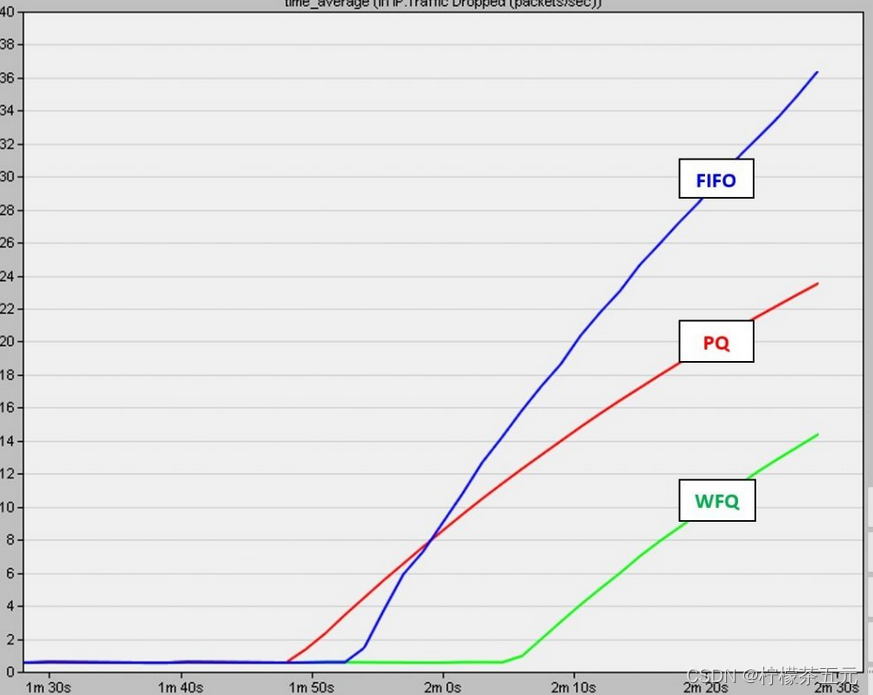
不同排队规则丢弃的数据包数量与时间的关系(在Riverbed Modeler上运行模拟)
结果分析如下:
-
在所有机制中, 从开始到特定点都没有丢包。这是因为填满路由器缓冲存储器需要有限的时间。由于数据包丢弃仅在缓冲区已满后发生, 因此有一个初始时间段, 因为尚未达到缓冲区容量, 所以没有丢包.
-
在FIFO方案中, 数据包丢弃在PQ之后但在WFQ之前开始。更重要的是, 在FIFO的情况下, 丢弃的数据包数量最大。这是由于以下事实:一旦拥塞, 所有应用程序的所有传入流量都将被完全丢弃, 不会有任何歧视.
-
在PQ方案中, 数据包丢弃最早开始。由于PQ根据优先级对队列进行划分, 因此将各个队列的总大小进行了划分。假设将内存简单划分为“重要”队列和“不太重要”队列, 队列大小减半。因此, 定向到子队列的数据包将导致队列更早被填充(由于较小的容量), 因此数据包丢弃将更早开始
-
3.模拟路由器转发分组
首先定义了一个
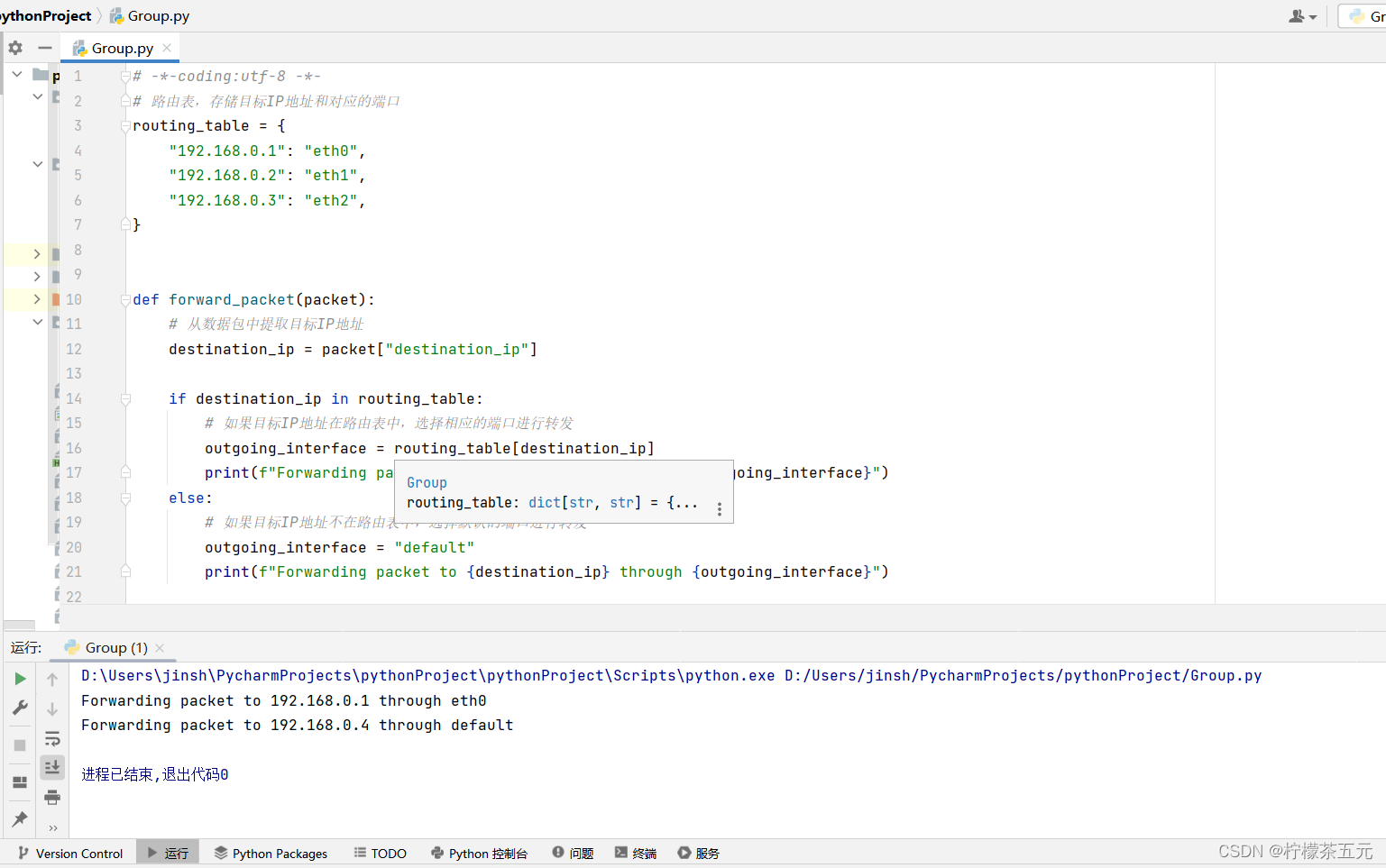
routing_table字典,其中存储了目标IP地址和对应的端口,定义了一个函数,该函数接收一个数据包作为输入。函数首先提取数据包中的目标IP地址,然后检查该地址是否在路由表中。如果目标IP地址在路由表中就选择相应的端口进行转发,并打印相应的信息。如果目标IP地址不在路由表中,选择默认的端口进行转发,并打印相应的信息。
模拟了两个数据包,并通过调用
forward_packet函数进行转发。3.1代码如下:
# -*-coding:utf-8 -*- # 路由表,存储目标IP地址和对应的端口 routing_table = { "192.168.0.1": "eth0", "192.168.0.2": "eth1", "192.168.0.3": "eth2", } def forward_packet(packet): # 从数据包中提取目标IP地址 destination_ip = packet["destination_ip"] if destination_ip in routing_table: # 如果目标IP地址在路由表中,选择相应的端口进行转发 outgoing_interface = routing_table[destination_ip] print(f"Forwarding packet to {destination_ip} through {outgoing_interface}") else: # 如果目标IP地址不在路由表中,选择默认的端口进行转发 outgoing_interface = "default" print(f"Forwarding packet to {destination_ip} through {outgoing_interface}") # 模拟两个数据包 packet1 = {"destination_ip": "192.168.0.1"} packet2 = {"destination_ip": "192.168.0.4"} # 分别进行数据包转发 forward_packet(packet1) forward_packet(packet2) 3.2运行结果如下:
4.生成多项式
生成多项式是接受方和发送方的一个约定,也就是一个二进制数,在整个传输过程中,这个数始终保持不变。在发送方,利用生成多项式对信息多项式做模2除生成校验码。在接收方利用生成多项式对收到的编码多项式做模2除检测和确定错误位置。
4.1由来:
生成多项式就是用来把要进行防错处理的二进制码流进行转换生成校验码,然后接收方会收到原始的二进制码流和校验码,按照与发送方相同的多项式再次进行转换生成校验码,与发来的校验码进行比较。如果一致则说明接收到的二进制码流是正确的;反之则说明接收到的二进制码流包含错误。
4.2条件:
-
生成多项式的最高位和最低位必须为1。
-
当被传送信息(CRC码)任何一位发生错误时,被生成多项式做除后应该使余数不为0。
-
不同位发生错误时,应该使余数不同。
-
对余数继续做除,应使余数循环。
4.3讲究:
4.3.1生成原则
(1) 为了确保选取的生成多项式校验性能是最优的,考察在具体嵌入式网络系统中传输数据帧最大长度的情况下,码重最大,漏检率最低的生成多项式。
(2)为了确保选取的生成多项式有较广的使用范围和良好的可移植性,分别考察小于和大于最大数据帧长度的情况,生成多项式的码重及漏检率的情况。
4.3.2生成方法
利用CRC进行检错的过程可简单描述为:在发送端根据要传送的k位二进制码序列,以一定的规则产生一个校验用的r位监督码(CRC码),附在原始信息后边,构成一个新的二进制码序列数共k+r位,然后发送出去。在接收端,根据信息码和CRC码之间所遵循的规则进行检验,以确定传送中是否出错。这个规则,在差错控制理论中称为“生成多项式”。
4.3.3生成步骤

参考文献:
[1] 吕喜在,黄芝平,苏绍璟.BCH码生成多项式快速识别方法.《西安电子科技大学学报》,2011
[2] 廖斌,张玉,杨晓静.含错扰码序列生成多项式的快速恢复方法.《CNKI;WanFang》,2014


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









