







 这篇博客探讨了如何使用Python模拟交换机,包括添加、查询和转发MAC地址,以及爬取豆瓣前50书单的爬虫实践。同时,讲解了UDP伪首部在计算校验和中的作用,以及超五类和六类双绞线的区别。
这篇博客探讨了如何使用Python模拟交换机,包括添加、查询和转发MAC地址,以及爬取豆瓣前50书单的爬虫实践。同时,讲解了UDP伪首部在计算校验和中的作用,以及超五类和六类双绞线的区别。
1.模拟交换机(Python)
这个程序模拟了一个交换机的基本功能,包括添加、删除和查询MAC地址表项,处理数据包转发等功能。添加了两个MAC地址表项,并尝试转发两个数据包。如果源MAC地址或目标MAC地址在MAC地址表中不存在,程序会相应地输出相关信息。
1.1关键流程图如下:
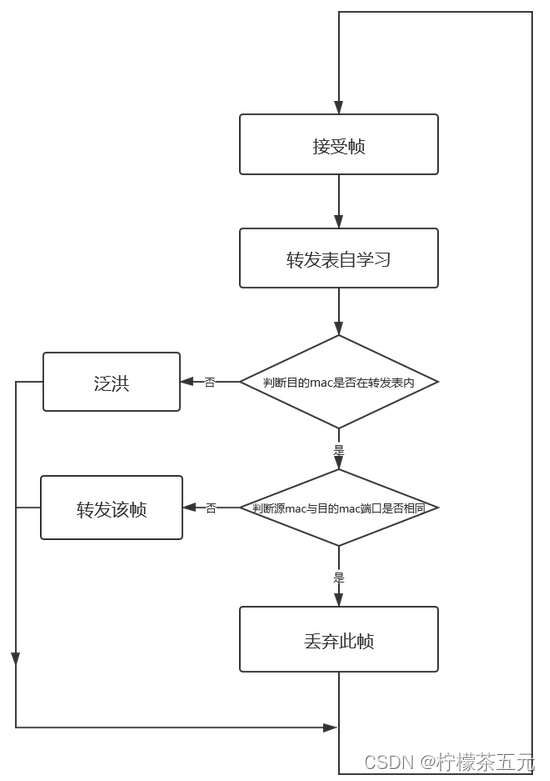
1.2代码如下:
# -*-coding:utf-8 -*-
class Switch:
def __init__(self):
self.mac_table = {} # MAC地址表
def add_mac_entry(self, mac_address, port):
self.mac_table[mac_address] = port
def remove_mac_entry(self, mac_address):
if mac_address in self.mac_table:
del self.mac_table[mac_address]
def lookup_mac_entry(self, mac_address):
if mac_address in self.mac_table:
return self.mac_table[mac_address]
else:
return None
def process_packet(self, source_mac, destination_mac, packet):
source_port = self.lookup_mac_entry(source_mac) # 查找源MAC地址对应的端口
destination_port = self.lookup_mac_entry(destination_mac) # 查找目标MAC地址对应的端口
if source_port is None:
print("Unknown source MAC address, dropping packet.") # 如果源MAC地址未知,则丢弃数据包并打印消息
return
if destination_port is None:
print("Unknown destination MAC address, broadcasting packet.") # 如果目标MAC地址未知,则广播数据包并打印消息
self.broadcast_packet(source_port, packet)
else:
print("Forwarding packet from port", source_port, "to port", destination_port) # 如果目标MAC地址已知,则转发数据包并打印消息
def broadcast_packet(self, source_port, packet):
for mac_address, port in self.mac_table.items():
if port != source_port:
print("Forwarding packet from port", source_port, "to port", port) # 广播数据包到除源端口外的所有端口
# 示例用法
switch = Switch()
switch.add_mac_entry("00:11:22:33:44:55", 1) # 将MAC地址与端口号添加到MAC地址表中
switch.add_mac_entry("66:77:88:99:AA:BB", 2)
switch.process_packet("11:11:22:33:44:55", "66:77:88:99:AA:BB", "Hello!")
switch.process_packet("00:11:22:33:44:55", "66:77:88:99:AA:BB", "Hello, World!") # 处理数据包,从端口1转发到端口2
switch.process_packet("00:11:22:33:44:55", "FF:FF:FF:FF:FF:FF", "Hello, Everyone!") # 处理数据包,从端口1广播到所有端口
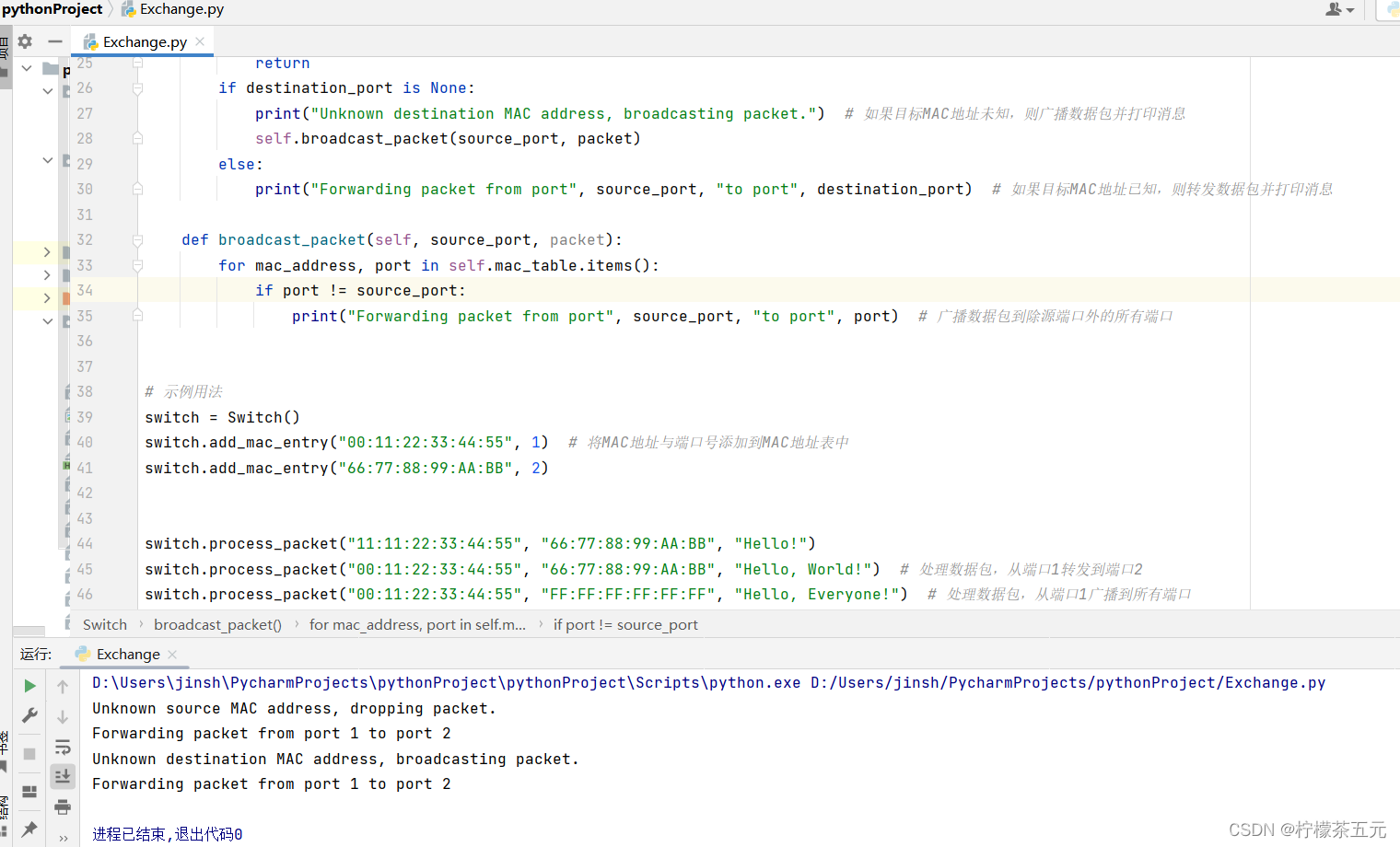
1.3运行结果如下:
2.爬虫:爬取豆瓣前50的书单
这是一个爬虫程序用来爬取豆瓣排行版前五十的书单,并将结果导入文件中。本次使用python编程,采用pycharm编辑器所编写的一段简单代码。
2.1代码如下:
# coding=utf-8
import requests
from bs4 import BeautifulSoup
# 获取书单,然后将结果存储在列表中
def get_book_list():
# 使用了豆瓣图书排行榜的网页URL
url = 'https://book.douban.com/top250?start={}'
headers = {
# 使用合适的请求头和间隔时间来模拟正常用户的访问
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36'
}
book_list = []
for start in range(0, 50, 25):
# 发起HTTP请求,获取网页内容
response = requests.get(url.format(start), headers=headers)
# 解析HTML,并提取出书籍的信息
soup = BeautifulSoup(response.text, 'html.parser')
books = soup.find_all('div', class_='pl2')
# 循环遍历网页的每页内容,并将每本书的信息存储在 book_list 列表中
for book in books:
book_info = book.a.text.strip()
book_list.append(book_info)
return book_list
# 将列表中的内容写入到文件中
def save_book_list(filename, book_list):
with open(filename, 'w', encoding='utf-8') as f:
f.write('\n'.join(book_list))
if __name__ == '__main__':
book_list = get_book_list()
save_book_list('books.txt', book_list)
print('Books saved to books.txt.')
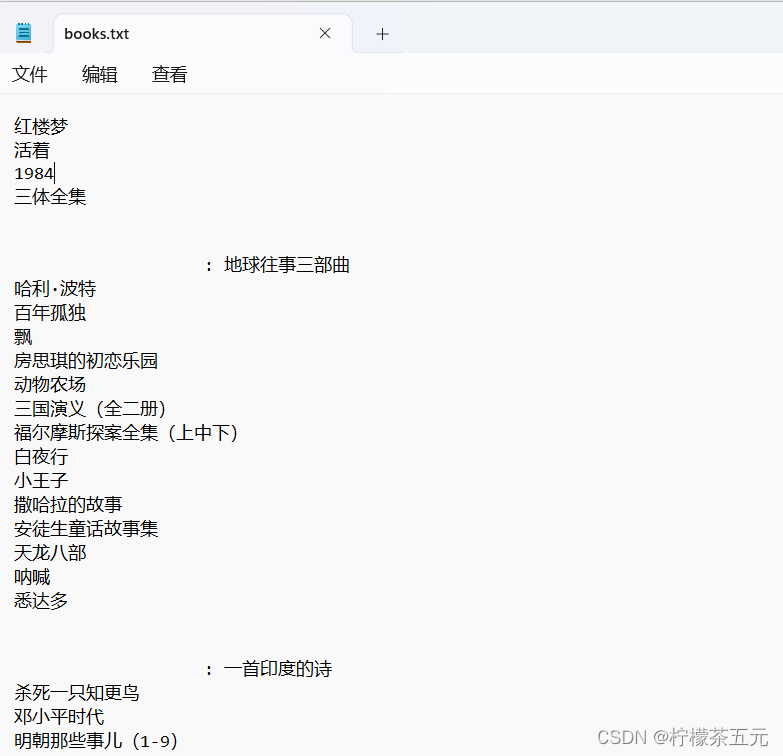
2.2运行结果展示:
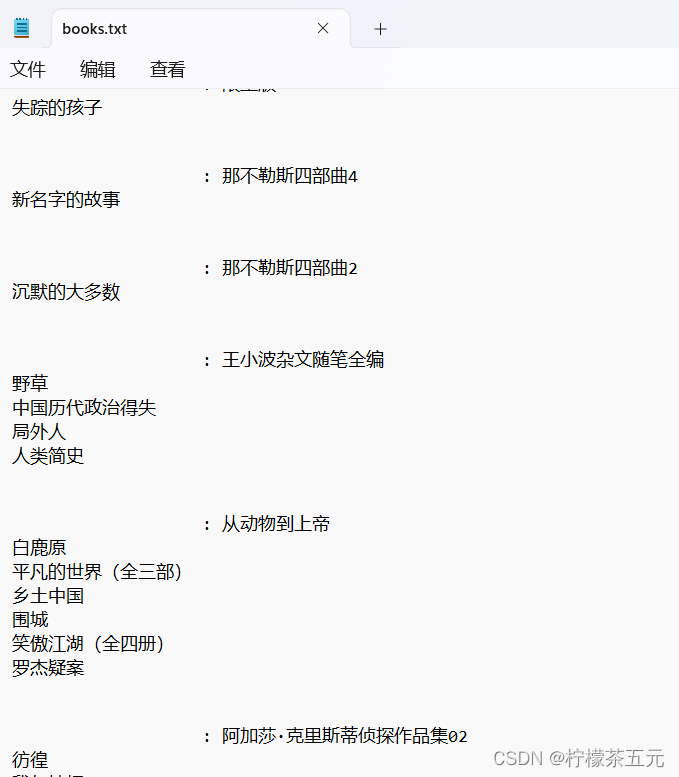
3.UDP中的伪首部的构造
UDP的伪首部是在计算UDP校验和时使用的。它是由源IP地址、目标IP地址、保留字段、协议类型(UDP)和UDP长度组成,并与UDP首部拼接在一起进行校验和计算。
伪首部的构造主要有以下原因:
1.校验和计算:UDP的校验和用于检测数据传输过程中是否发生了错误或丢失。为了增加校验和的准确性,需要在计算校验和时包含一些关键信息,如源IP地址和目标IP地址。
2.网络层辅助验证:UDP是传输层协议,它依赖于网络层协议(如IPv4或IPv6)来提供IP地址等必要的信息。伪首部中的IP地址字段可以帮助验证UDP数据包是否送达正确的目标。
3.防止冲突:通过在伪首部中添加保留字段和协议类型字段,可以防止与其他协议或数据产生冲突。这样可以确保在进行校验和计算时不会与其他协议或数据混淆。
4.支持多路复用和分解:UDP允许在同一个主机上使用不同的源端口和目标端口进行多路复用。通过包含源IP地址和目标IP地址,伪首部可以帮助接收方正确地将接收到的数据包分解到相应的应用程序或进程。
5.提供额外的校验信息:伪首部中的IP地址字段和协议类型字段提供了额外的校验信息,可以帮助接收方验证UDP数据包是否符合预期的网络层条件。这样可以增加数据传输的可靠性和安全性。
6.防止欺骗和篡改:通过包含源IP地址和目标IP地址,伪首部可以帮助检测和防止欺骗、伪装和篡改攻击。接收方可以验证发送方的身份,并确保接收到的数据包没有被更改过。
7.路由选择和负载均衡:伪首部中的IP地址字段可以帮助路由器选择适当的路径进行数据传输,并支持负载均衡机制。
!!!!!需要注意的是,伪首部只在计算校验和时使用,并不在实际的UDP数据包中传输。它的目的是增加校验和的准确性和可靠性,以提高数据传输的可靠性和完整性。!!!!!
所谓“伪首部”是因为这种伪首部并不是UDP用户数据报的真正首部。只是在计算校验和时,临时添加在UDP数据报前面,得到的临时用户数据报。校验和就是按照这个临时的UDP用户数据报来计算的。伪首部仅仅是为了计算校验和。
通过查阅资料,发现关于伪首部,还有一个解释是历史遗留,stackoverflow上有相应解释,附上链接:What is the Significance of Pseudo Header used in UDP/TCP
4.超五类和六类双绞线的区别
"超五类"指的是超五类非屏蔽双绞线(UTP—Unshielded Twisted Pair)非屏蔽双绞线电缆是由多对双绞线和一个塑料外皮构成。五类是指国际电气工业协会为双绞线电缆定义的五种不同的质量级别.超五类双绞线也是采用4个绕对和1条抗拉线,线对的颜色与五类双绞线完全相同,分别为白橙、橙、白绿、绿、白蓝、蓝、白棕和棕。裸铜线径为0.51mm(线规为24AWG),绝缘线径为0.92mm,UTP电缆直径为5mm
"六类"是指六类非屏蔽双绞线,六类非屏蔽双绞线的各项参数都有大幅提高,带宽也扩展至250MHz或更高。六类双绞线在外形上和结构上与五类或超五类双绞线都有一定的差别,不仅增加了绝缘的十字骨架,将双绞线的四对线分别置于十字骨架的四个凹槽内,而且电缆的直径也更粗。电缆中央的十字骨架随长度的变化而旋转角度,将四对双绞线卡在骨架的凹槽内,保持四对双绞线的相对位置,提高电缆的平衡特性和串扰衰减。另外,保证在安装过程中电缆的平衡结构不遭到破坏。六类非屏蔽双绞线裸铜线径为0.57mm(线规为23AWG),绝缘线径为1.02mm,UTP电缆直径为6.53mm
“按照电气性能的不同,双绞线可分为三类、五类、超五类、六类和七类双绞线。不同类别的双绞线价格相差较大甚至是悬殊,应用范围也大不相同。 除了传统的语音系统仍然使用三类双绞线以外,网络布线目前基本上都在采用超五类或六类非屏蔽双绞线。五类非屏蔽双绞线虽仍然可以支持1000Base-T,但由于在价格上与超五类非屏蔽双绞线相差无几,因此,已经逐渐淡出布线市场。”
主要区别如下:
1、传输速率不同:六类线是100M/s;而超5类线则可达1000Mbps。
2、带宽占用率不一样:由于超五类线和普通6类产品相比有更大的数据传输量(即更高的网速),因此它们对网络设备的选择和设置提出了更高要求。
3、信号衰减情况不同:4类、6类、8类、10类、12类、20类等几大类非屏蔽双绞线都有各自不同的特点及适用领域:6类双绞线上允许最大300MHz的频率范围,10类双绞线上的频率范围为200-450 Mhz,8类、10类、12类、20类双绞网上的频率范围分别为150-350MHz,100-300MHz,80-240MHz,40-100Hz,20-50HZ,12-20 Hz.12类以上的电缆可以支持高达1Gbps的下载速度;6类、7类、9类、10类电缆可提供500-800MBps的数据传送能力;3类、5类、3A类、1B型2D型的3种型号的双绞缆只可用于语音通讯;2D型和4D型的两种型号的电缆只能用来进行低速数据通信。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









