






一说起QQ空间,那就是满满的回忆杀。那年咱还是一名初中生,昵称也是相当霸气——“穿着拖鞋爬墙头”,为了上网聊天玩游戏,那学校的墙头时常闪现咱和几位同学的身影,可以说,当年眼观六路耳听八方,身手相当不俗~

说起游戏,屋主玩过 CS(当年还叫半条命),红警,星际争霸,传奇……
说到聊天,那必须是QQ,那年为了在QQ空间偷菜,没有少定时,比每天起床还要准时,当然挂QQ等级也是日常不可少的项目~
那么问题来了?
你还记得当年在QQ空间发布过哪些说说吗?与哪些好友互动交流过?又留下了哪些珍贵的图片和“惊世骇俗”的言论?突然的回首,翻一翻当年玩得不亦乐乎的空间,发现原来自己这么diao?忧郁风,非主流玩得相当溜……
恢复QQ空间删除的说说相册留言
这是一款开源的神器,专为QQ空间用户设计,它能够帮助大家获取并保存自己或他人QQ空间的历史说说内容。
该软件通过模拟登录QQ空间,获取历史消息列表,并进行数据分析,利用Python等编程语言中的网络请求库(如requests)和网页解析库(如BeautifulSoup),软件能够精确地提取出说说内容、发布时间、点赞数、评论数等关键信息。
随后,这些信息被结构化地存储在本地数据库或文件中,供大家随时查阅和分析。最终将获取的说说存放到指定目录下。
对于希望回顾过去、保存珍贵记忆或进行数据备份的用户来说,GetQzonehistory无疑是一款不可或缺的神器。

软件下载地址
百度网盘:https://pan.baidu.com/s/1DH6_QnBBuizukmkyr267iw?pwd=6666
夸克网盘:https://pan.quark.cn/s/a54b0ec780b6
GetQzonehistory QQ空间恢复工具
历史说说获取:
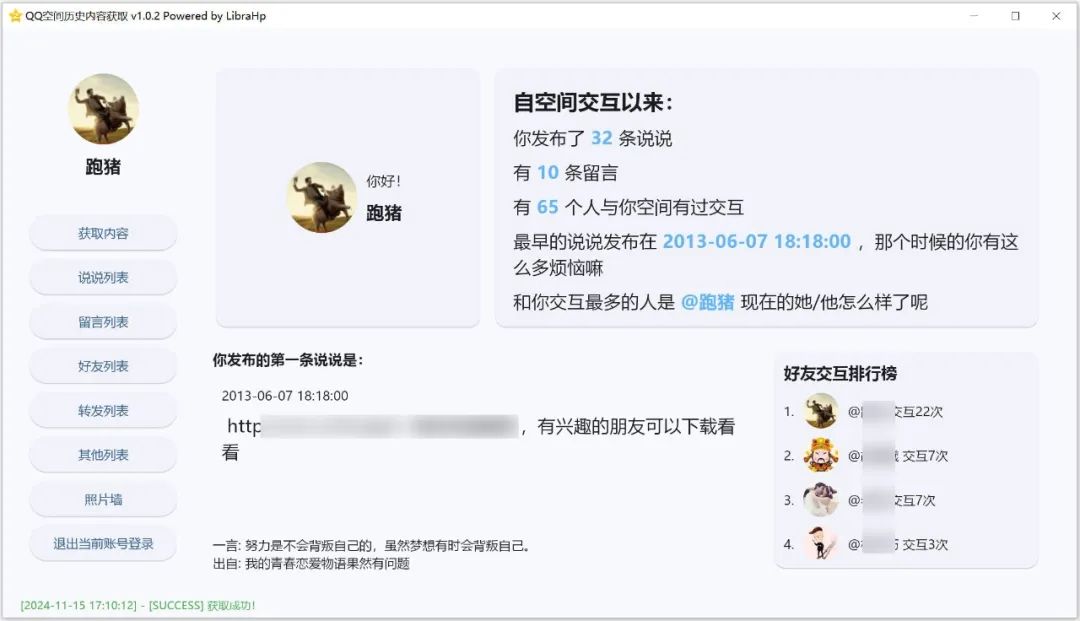
GetQzonehistory能够深入QQ空间的历史记录,抓取大家发布过的所有说说内容。
无论是几年前的旧帖还是近期的新动态,都能一网打尽。
这一功能让大家能够轻松回顾自己在QQ空间的成长历程,找回那些可能已被遗忘的美好瞬间。
数据保存与导出:
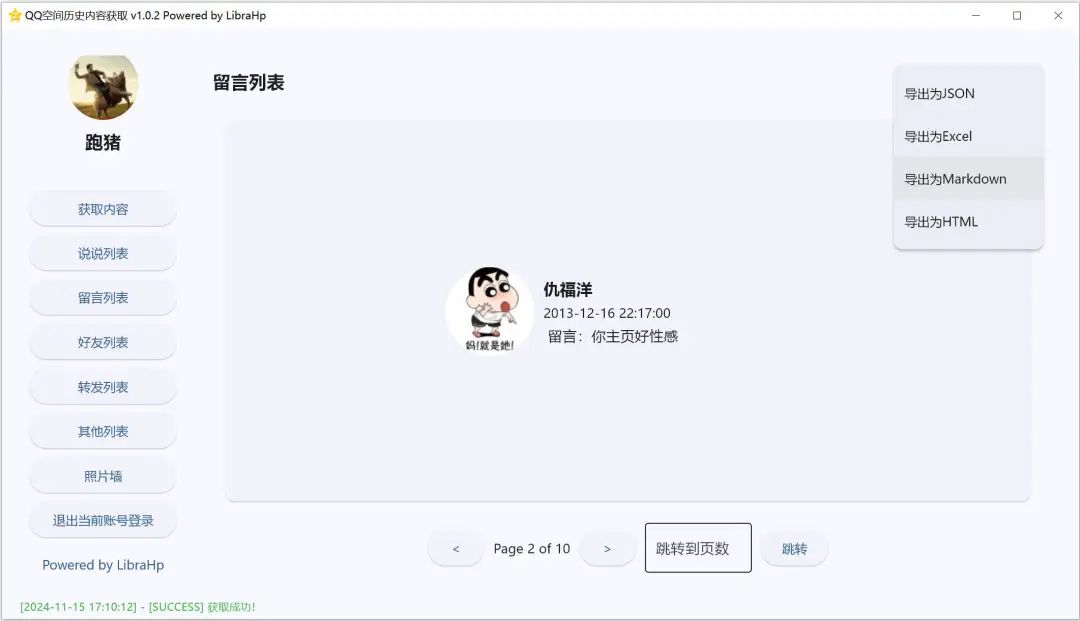
软件不仅支持在线查看说说内容,还提供了数据保存功能。
大家可以将抓取到的说说内容导出为多种格式的文件,如TXT、CSV等,方便在本地进行存储和备份。
这样,即使未来QQ空间发生变动或数据丢失,大家也能保留自己的珍贵回忆。
隐私保护与权限管理:
在使用GetQzonehistory时,大家无需担心隐私泄露问题。软件遵循严格的隐私政策,仅抓取公开可见的说说内容,对于设置了隐私权限的说说则无法获取。
此外大家还可以根据需要设置抓取范围和权限,确保只获取自己想要的数据。
多账号支持与批量操作:
如果你需要管理多个QQ账号,GetQzonehistory提供了多账号支持功能。你可以在同一界面下切换不同账号,进行批量抓取和导出操作。这大大提高了工作效率,减少了重复劳动的时间成本。
最后:
GetQzonehistory 免费且开源,能够帮助大家实现QQ空间内容的获取和整理保存到本地,相当Nice~

















 2479
2479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









