







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
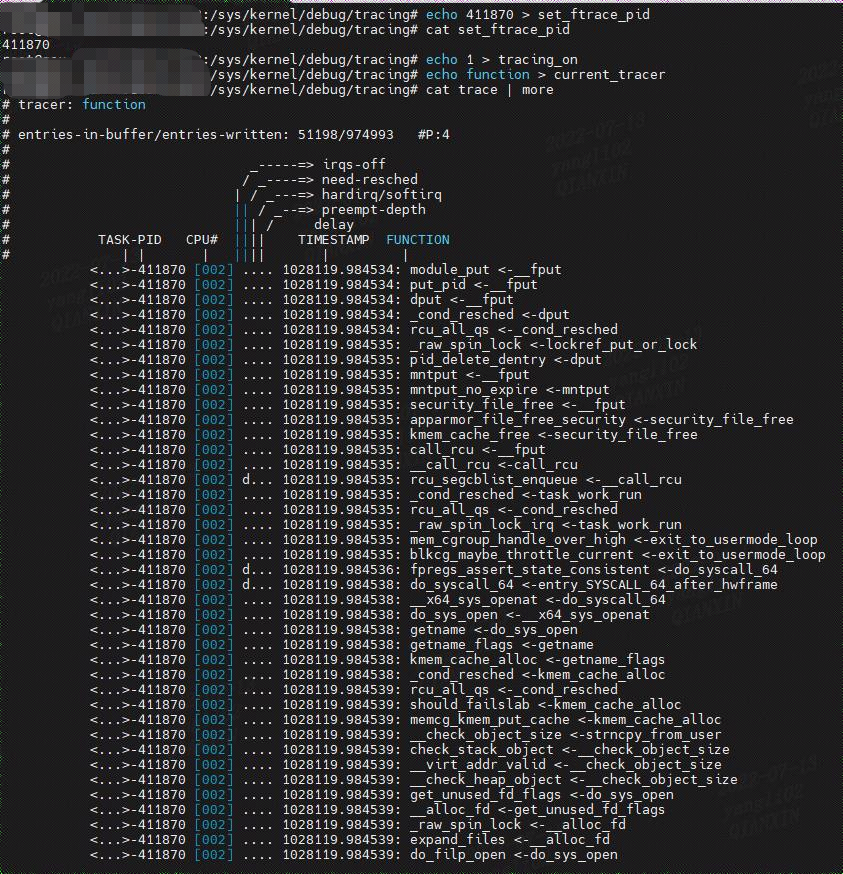
## 二、Ftrace function\_graph
### 2.1 Graph Tracing
此跟踪器类似于函数跟踪器,只是它在函数的入口和出口处探测函数。 这是通过在每个 task\_struct 中使用动态分配的返回地址堆栈来完成的。 在函数进入时,跟踪器会覆盖每个跟踪函数的返回地址以设置自定义探针。 因此原始返回地址存储在task\_struct中的返回地址堆栈中。
在函数的两端进行探测会导致特殊功能,例如:
(1)衡量函数执行时间。
(2)有一个可靠的调用栈来绘制函数调用图。
这个跟踪器在以下几种情况下是有用的:
(1)想找到内核异常行为的原因,需要详细了解在任何区域(或特定区域)发生了什么。
(2)正在经历不寻常的延迟,但很难找到它的起源。
(3)快速找到特定功能所采用的路径
(4)查看运行中的内核,看看那里发生了什么。
有几列可以动态启用/禁用。 您可以根据需要使用所需的每种选项组合:
function\_graph 跟踪器打印函数的调用图,展示其代码流。

只跟踪一个函数及其所有子函数,将其名称echo 到 set\_graph\_function 中:
echo do_nanosleep > set_graph_function
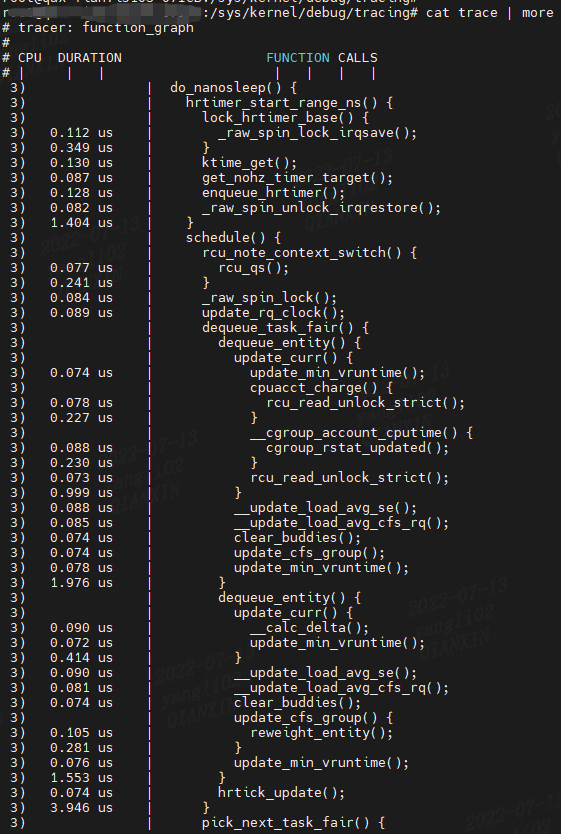
下面使用 do\_nanosleep() 函数上的 function\_graph 跟踪器来显示其子函数调用:
echo do_nanosleep > set_graph_function
echo function_graph > current_tracer
echo nop > current_tracer
echo > set_graph_function
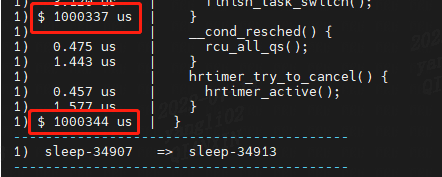
输出显示子调用和代码流:do\_nanosleep() 调用 hrtimer\_start\_range\_ns().左侧的列显示了 CPU(在此输出中,主要是 CPU 3)和函数的持续时间,以便可以识别延迟.高延迟包括一个字符符号以帮助您注意它们,在此输出中,延迟为 1000337 微秒(1.0 秒)旁边的“$”。
$: Greater than 1 second
@: Greater than 100 ms
*: Greater than 10 ms
#: Greater than 1 ms
!: Greater than 100 μs
+: Greater than 10 μs
这个例子特意没有设置函数过滤器(set\_ftrace\_filter),这样所有子调用都可以看到。 但是,这确实会产生一些开销,从而夸大了报告的持续时间。 它通常对于定位高延迟的来源仍然很有用,这会使增加的开销相形见绌。 当您希望给定函数的时间更准确时,可以使用函数过滤器来减少跟踪的函数。 例如,仅跟踪 do\_nanosleep():
echo do_nanosleep > set_ftrace_filter
以 do\_sys\_open 函数为例子来测试function\_graph:
echo do_sys_open > set_graph_function
echo function_graph > current_tracer
echo funcgraph-proc > trace_options
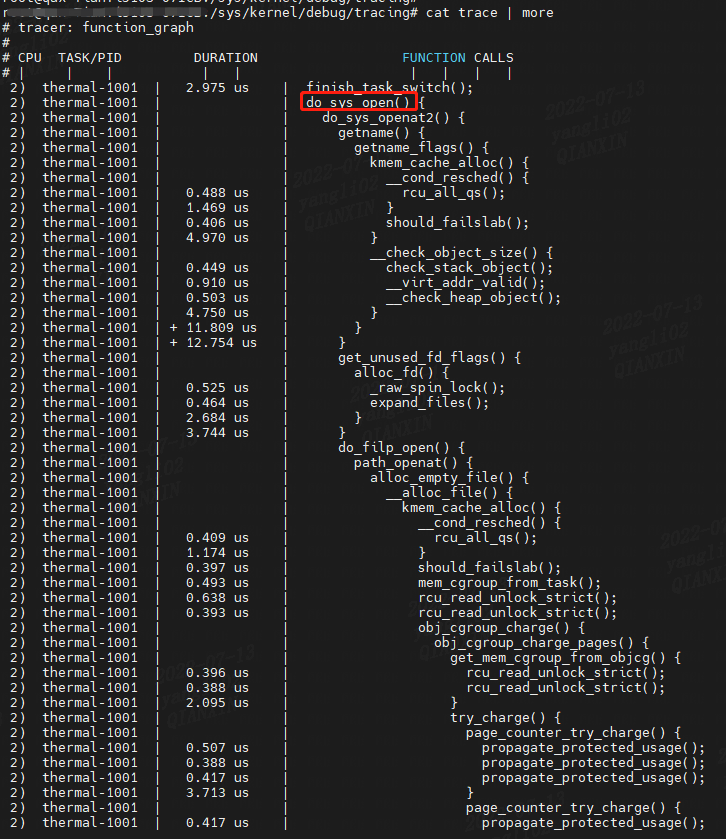
CPU 字段给出了执行函数的 CPU 号,本例中为2 号 CPU
TASK/PID 地段给出进程名称和进程PID号
DURATION 字段给出了函数执行的时间长度,以 us 为单位。
FUNCTION CALLS 则给出了调用的函数,并显示了调用流程。
需要注意:
对于不调用其它函数的函数,其对应行以“;”结尾,而且对应的 DURATION 字段给出其运行时长;
对于调用其它函数的函数,则在其“}”对应行给出了运行时长,该时间是一个累加值,包括了其内部调用的函数的执行时长。DURATION 字段给出的时长并不是精确的,它还包含了执行 ftrace 自身的代码所耗费的时间,所以示例中将内部函数时长累加得到的结果会与对应的外围调用函数的执行时长并不一致;不过通过该字段还是可以大致了解函数在时间上的运行开销的。
**备注:function graph trace 实际是在要跟踪函数的入口处和返回处分别放置了钩子函数,在要跟踪函数的入口处插入钩子函数ftrace\_caller,在要跟踪函数的返回处插入钩子函数return\_to\_handler。因此function\_graph tracer即可以跟踪到函数的入口还可以跟踪到函数的返回**
### 2.2 Options
选项可用于更改输出,可以在选项options目录中列出:
ls options/funcgraph-*

这些调整输出并且可以包括或排除详细信息,例如 CPU ID (funcgraph-cpu)、进程名称 (funcgraph-proc)、函数持续时间 (funcgraph-duration) 和延迟标记 (funcgraph-overhead)。
(1)
执行函数的 CPU 编号默认启用。 有时最好只跟踪一个 cpu,或者您有时可能会在 cpu 跟踪切换时看到无序的函数调用。
hide: echo nofuncgraph-cpu > trace_options
show: echo funcgraph-cpu > trace_options
(2)
持续时间(函数的执行时间)显示在函数的右括号行上,或者在叶子函数的情况下显示在与当前函数相同的行上。 它是默认启用的。
hide: echo nofuncgraph-duration > trace_options
show: echo funcgraph-duration > trace_options

叶子函数:没有调用其他的函数。
(3)
task/pid 字段显示执行该函数的线程 cmdline 和 pid。 默认禁用。
hide: echo nofuncgraph-proc > trace_options
show: echo funcgraph-proc > trace_options
比如:
tracer: function_graph
CPU TASK/PID DURATION FUNCTION CALLS
| | | | | | | | |
- sh-4802 | | d_free() {
- sh-4802 | | call_rcu() {
- sh-4802 | | __call_rcu() {
- sh-4802 | 0.616 us | rcu_process_gp_end();
- sh-4802 | 0.586 us | check_for_new_grace_period();
- sh-4802 | 2.899 us | }
- sh-4802 | 4.040 us | }
- sh-4802 | 5.151 us | }
- sh-4802 | + 49.370 us | }
(4)
在达到持续时间阈值的情况下,开销字段在持续时间字段之前。
hide: echo nofuncgraph-overhead > trace_options
show: echo funcgraph-overhead > trace_options
depends on: funcgraph-duration
比如:
-
1837.709 us | } /* __switch_to */
-
| finish\_task\_switch() { - 0.313 us | _raw_spin_unlock_irq();
- 3.177 us | }
-
1889.063 us | } /* __schedule */
- ! 140.417 us | } /* __schedule */
-
2034.948 us | } /* schedule */
- * 33998.59 us | } /* schedule_preempt_disabled */
[…]
- 0.260 us | msecs_to_jiffies();
- 0.313 us | __rcu_read_unlock();
-
- 61.770 us | }
-
- 64.479 us | }
- 0.313 us | rcu_bh_qs();
- 0.313 us | __local_bh_enable();
- ! 217.240 us | }
- 0.365 us | idle_cpu();
-
| rcu\_irq\_exit() { - 0.417 us | rcu_eqs_enter_common.isra.47();
- 3.125 us | }
- ! 227.812 us | }
- ! 457.395 us | }
- @ 119760.2 us | }
[…]
-
| handle\_IPI() { - 6.979 us | }
- 0.417 us | scheduler_ipi();
- 9.791 us | }
-
- 12.917 us | }
- 3.490 us | }
-
- 15.729 us | }
-
- 18.542 us | }
- $ 3594274 us | }
- means that the function exceeded 10 usecs.
! means that the function exceeded 100 usecs.
means that the function exceeded 1000 usecs.
* means that the function exceeded 10 msecs.
@ means that the function exceeded 100 msecs.
$ means that the function exceeded 1 sec.
(5)
对于开始在跟踪缓冲区中的函数,可以在右括号(the closing bracket)后显示函数名称,从而可以更轻松地使用 grep 搜索函数持续时间。 默认禁用。
hide: echo nofuncgraph-tail > trace_options
show: echo funcgraph-tail > trace_options
nofuncgraph-tail 示例(默认):
-
| putname() { -
| kmem\_cache\_free() { - 0.518 us | __phys_addr();
- 1.757 us | }
- 2.861 us | }
funcgraph-tail 示例:
-
| putname() { -
| kmem\_cache\_free() { - 0.518 us | __phys_addr();
- 1.757 us | } /* kmem_cache_free() */ 右括号(代表函数结束)显示函数名称
- 2.861 us | } /* putname() */ --右括号(代表函数结束)显示函数名称
(6)
可以使用 trace\_printk() 对特定函数 function() 添加一些注释 例如,如果您想在 function() 函数中添加注释,您只需包含 <linux/ftrace.h> 并在 function() 中调用 trace\_printk() :
trace_printk(“I’m a comment!\n”)
将产生:
-
| function() { -
| /\* I'm a comment! \*/ - 1.449 us | }
## 三、tracepoint
### 3.1 tracepoint简介
参考:[Event Tracing](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)
tracepoint是内核静态检测,跟踪点在技术上只是放置在内核源代码中的跟踪函数; 它们从定义和格式化它们的参数的跟踪事件接口中使用。 跟踪事件在 tracefs 中可见,并与 Ftrace 共享输出和控制文件
无需创建自定义内核模块即可使用tracepoint来使用 event tracing infrastructure 注册探测功能。
并非所有tracepoint都可以使用 event tracing system 进行跟踪; 内核开发人员必须提供代码片段,这些代码片段定义了如何将跟踪信息保存到跟踪缓冲区中,以及应该如何打印跟踪信息。
基于 ftrace 跟踪内核静态跟踪点,包括全部可用于跟踪的静态跟踪点,可跟踪的完整列表可通过 available\_events 查看:
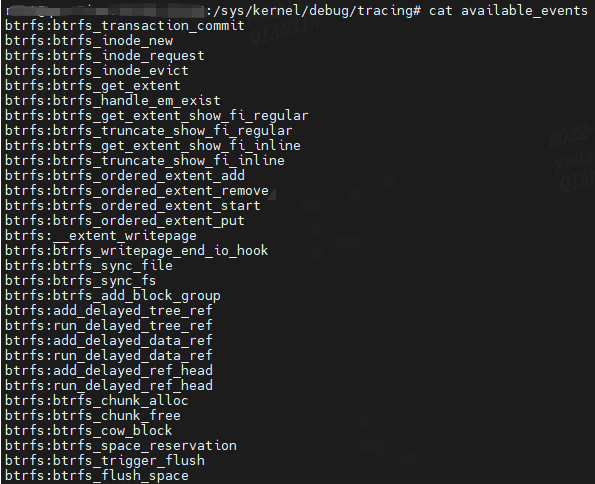
events 目录下查看到各分类的子目录:
ls -F events

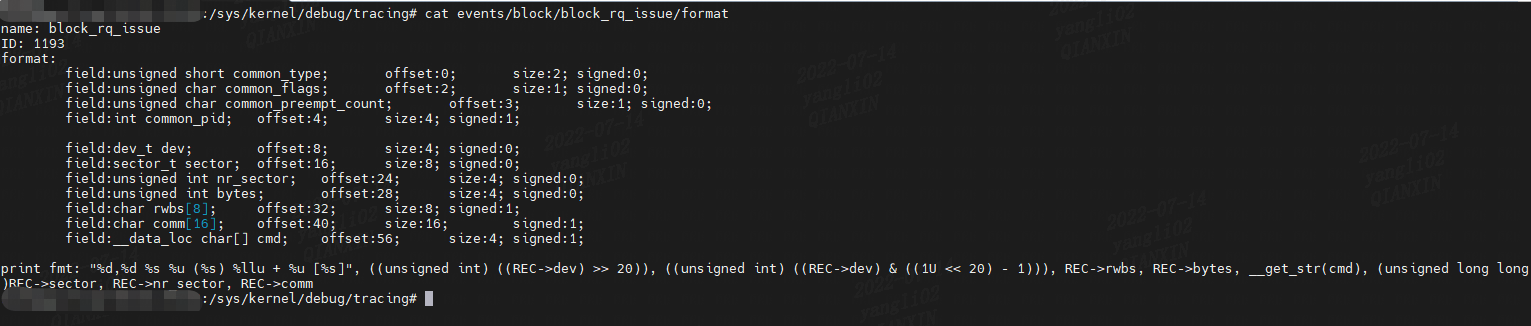
例如,以下启用 block:block\_rq\_issue 跟踪点并实时监视事件。 此示例通过禁用跟踪点完成:
echo 1 > events/block/block_rq_issue/enable
cat trace_pipe | more
前五列是:进程名称“-”PID、CPU ID、标志、时间戳(秒)和事件名称。其余的是跟踪点的格式字符串。

echo 0 > events/block/block_rq_issue/enable
从这个例子中可以看出,跟踪点在事件下的目录结构中有控制文件。 每个跟踪系统都有一个目录(例如,“block”)和每个事件的子目录(例如,“block\_rq\_issue”):

这些控制文件记录在 Linux 源代码的 Documentation/trace/events.rst 下,在此示例中,启用文件用于打开和关闭跟踪点。 其他文件提供过滤和触发功能。
### 3.2 Filter
可以包含过滤器以仅在满足布尔表达式时记录事件。 它有一个受限制的语法:
field operator value
(1)数字运算符是以下之一:==、!=、<、<=、>、>=、&;
(2)对于字符串:==、!=、~。
(3)“~”运算符执行 shell glob 样式的匹配,带有通配符:\*、?、[]。
这些布尔表达式可以用括号分组并使用:&&、|| 组合。
备注:
通配符\*:表示字符在匹配模式的文本中出现0次或多次
通配符?:表示字符在匹配模式的文本中出现0次或1次
通配符[]: []表示字符组,可以定义用来匹配文本模式中某个位置的一组字符。如果字符组中某个字符出现在了数据流中,就匹配该模式。
例如,以下对已启用的 block:block\_rq\_insert 跟踪点设置过滤器以仅跟踪字节字段大于 64 KB 的事件:
echo ‘bytes > 65536’ > events/block/block_rq_insert/filter
输出现在只包含较大的 I/O。
echo 0 > events/block/block_rq_insert/filter //echo 0 重置过滤器
### 3.3 Trigger
触发事件时,触发器会运行额外的跟踪命令。 该命令可能是启用或禁用其他跟踪、打印堆栈跟踪或获取跟踪缓冲区的快照。 当前未设置触发器时,可以从触发器文件中列出可用的触发器命令。 例如:
cat events/block/block_rq_issue/trigger

触发器的一个用例是当您希望查看导致错误条件的事件时:可以将触发器放置在错误条件上,该条件可以禁用跟踪 (traceoff),以便跟踪缓冲区仅包含先前的事件,或者获取 一个快照(snapshot)来保存它。
触发器可以通过使用 if 关键字与上一节中显示的过滤器结合使用。 这可能是匹配错误条件或有趣事件所必需的。 例如,要在大于 64 KB 的块 I/O 排队时停止记录事件:
echo ‘traceoff if bytes > 65536’ > events/block/block_rq_insert/trigger
## 四 、kprobes
参考:[Kprobe-based Event Tracing](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)
这些事件类似于基于跟踪点的事件。 它不是基于 Tracepoint,而是基于 kprobes(kprobe 和 kretprobe)。 所以它可以探测 kprobes 可以探测的任何地方(这意味着,除了那些带有 \_\_kprobes/nokprobe\_inline 注释和那些标记为 NOKPROBE\_SYMBOL 的函数之外的所有函数)。 与基于 Tracepoint 的事件不同,它可以动态添加和删除.
要启用此功能,请使用 CONFIG\_KPROBE\_EVENTS=y 构建内核。
与events tracer(tracepoint)类似,这不需要通过 current\_tracer 激活。 取而代之的是,通过 /sys/kernel/debug/tracing/kprobe\_events 添加探测点,并通过 /sys/kernel/debug/tracing/events/kprobes//enable 启用它。
您也可以使用 /sys/kernel/debug/tracing/dynamic\_events 而不是 kprobe\_events。 该接口也将提供对其他动态事件的统一访问。
kprobes 是内核动态检测机制,允许我们跟踪函数任意位置,还可用于获取函数参数与结果返回值。kprobe 机制跟踪函数须是 available\_filter\_functions 列表中的子集。
kprobes 创建 kprobe 事件供跟踪器使用,它与 Ftrace 共享 tracefs 输出和控制文件。kprobes 类似于 Ftrace 函数跟踪器,因为它们跟踪核函数。然而,kprobes 可以进一步定制,可以放置在函数偏移量(单独的指令)上,并且可以报告函数参数和返回值。
### 4.1 Event Tracing
每个探针事件过滤功能允许您在每个探针上设置不同的过滤器,并为您提供将在跟踪缓冲区中显示的参数。 如果在 kprobe\_events 中的 ‘p:’ 或 ‘r:’ 之后指定了事件名称,它会在 tracking/events/kprobes/ 下添加一个事件,在该目录中您可以看到 id、enable、format 、filter 和 trigger。
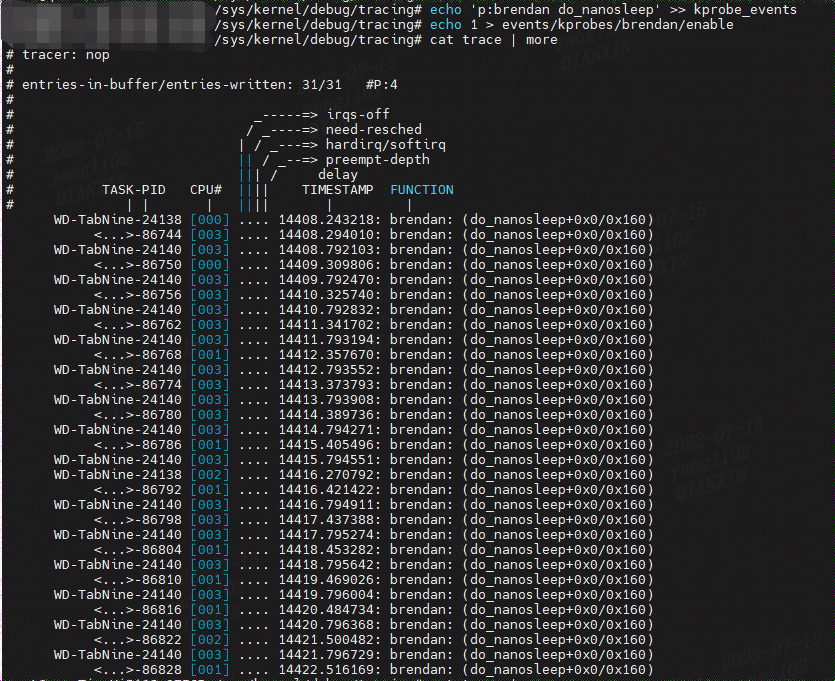
例如,以下使用 kprobes 检测 do\_nanosleep() 内核函数:
echo ‘p:brendan do_nanosleep’ >> kprobe_events
echo 1 > events/kprobes/brendan/enable
cat trace | more

enable:
You can enable/disable the probe by writing 1 or 0 on it.
format:
This shows the format of this probe event.
filter:
You can write filtering rules of this event.
id:
This shows the id of this probe event.
trigger:
This allows to install trigger commands which are executed when the event is hit
echo 0 > events/kprobes/brendan/enable
echo ‘-:brendan’ >> kprobe_events
通过将特殊语法附加到 kprobe\_events 来创建和删除 kprobe。 创建后,它会与跟踪点一起出现在 events 目录中,并且可以以类似的方式使用。kprobe 语法在 Documentation/trace/kprobetrace.rst 下的内核源代码中有完整说明。kprobes 能够跟踪内核函数的进入和返回以及函数偏移量。
kprobe\_events 概要:
p[:[GRP/]EVENT] [MOD:]SYM[+offs]|MEMADDR [FETCHARGS] : Set a probe
r[MAXACTIVE][:[GRP/]EVENT] [MOD:]SYM[+0] [FETCHARGS] : Set a return probe
p:[GRP/]EVENT] [MOD:]SYM[+0]%return [FETCHARGS] : Set a return probe
-:[GRP/]EVENT : Clear a probe
GRP : Group name. If omitted, use “kprobes” for it.
EVENT : Event name. If omitted, the event name is generated
based on SYM+offs or MEMADDR.
MOD : Module name which has given SYM.
SYM[+offs] : Symbol+offset where the probe is inserted.
SYM%return : Return address of the symbol
MEMADDR : Address where the probe is inserted.
MAXACTIVE : Maximum number of instances of the specified function that
can be probed simultaneously, or 0 for the default value
as defined in Documentation/trace/kprobes.rst section 1.3.1.
FETCHARGS : Arguments. Each probe can have up to 128 args.
%REG : Fetch register REG
@ADDR : Fetch memory at ADDR (ADDR should be in kernel)
@SYM[+|-offs] : Fetch memory at SYM +|- offs (SYM should be a data symbol)
$stackN : Fetch Nth entry of stack (N >= 0)
$stack : Fetch stack address.
$argN : Fetch the Nth function argument. (N >= 1) (\*1)
$retval : Fetch return value.(\*2)
$comm : Fetch current task comm.
+|-[u]OFFS(FETCHARG) : Fetch memory at FETCHARG +|- OFFS address.(\*3)(\*4)
\IMM : Store an immediate value to the argument.
NAME=FETCHARG : Set NAME as the argument name of FETCHARG.
FETCHARG:TYPE : Set TYPE as the type of FETCHARG. Currently, basic types
(u8/u16/u32/u64/s8/s16/s32/s64), hexadecimal types
(x8/x16/x32/x64), “string”, “ustring” and bitfield
are supported.
(\*1) only for the probe on function entry (offs == 0).
(\*2) only for return probe.
(\*3) this is useful for fetching a field of data structures.
(\*4) “u” means user-space dereference. See :ref:user_mem_access.
在上面的示例中,字符串“p:brendan do\_nanosleep”为内核符号 do\_nanosleep() 创建了一个名为“brendan”的探针 (p:)。 字符串“-:brendan”删除名称为“brendan”的探测。
### 4.2 Arguments
与函数跟踪不同,kprobes 可以检查函数参数和返回值。 例如,这里是前面跟踪的 do\_nanosleep() 函数的声明,来自 kernel/time/hrtimer.c,其中突出显示了参数变量类型:
static int __sched do_nanosleep(struct hrtimer_sleeper *t, enum hrtimer_mode mode)
{
hrtimer_init_sleeper(t, current);
do {
set\_current\_state(TASK_INTERRUPTIBLE);
hrtimer\_start\_expires(&t->timer, mode);
if (likely(t->task))
freezable\_schedule();
hrtimer\_cancel(&t->timer);
mode = HRTIMER_MODE_ABS;
} while (t->task && !signal\_pending(current));
\_\_set\_current\_state(TASK_RUNNING);
return t->task == NULL;
}
跟踪 Intel x86\_64 系统上的前两个参数并将它们打印为十六进制(默认值):
echo ‘p:brendan do_nanosleep hrtimer_sleeper= a r g 1 h r t i m e r m o d e = arg1 hrtimer_mode= arg1hrtimermode=arg2’ >> kprobe_events

echo 0 > events/kprobes/brendan/enable
echo ‘-:brendan’ >> kprobe_events
在第一行的事件描述中添加了额外的语法:例如,字符串“hrtimer\_sleeper=$arg1”跟踪函数的第一个参数并使用自定义名称“hrtimer\_sleeper”。 这已在输出中突出显示。
在 Linux 4.20 中添加了访问
a
r
g
1
、
arg1、
arg1、arg2 等函数的参数。 以前的 Linux 版本需要使用寄存器名称。 这是使用寄存器名称的等效 kprobe 定义:
echo ‘p:brendan do_nanosleep hrtimer_sleeper=%di hrtimer_mode=%si’ >> kprobe_events
要使用寄存器名称,您需要知道处理器类型和使用的函数调用约定。 x86\_64 uses the AMD64 ABI,所以前两个参数在寄存器 rdi 和 rsi 中可用。
### 4.3 Return Values
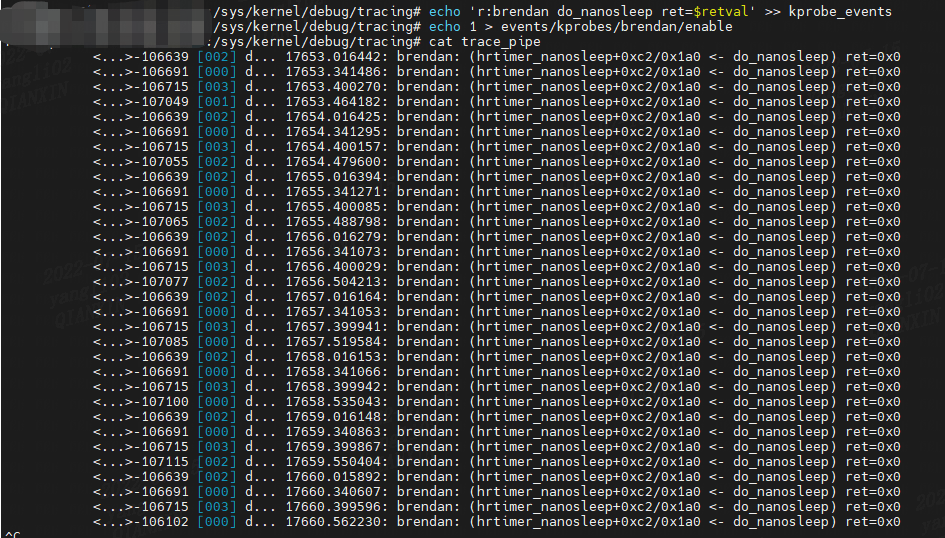
返回值的特殊别名 $retval 可用于 kretprobes。 以下示例使用它来显示 do\_nanosleep() 的返回值:
echo ‘r:brendan do_nanosleep ret=$retval’ >> kprobe_events
echo 1 > events/kprobes/brendan/enable
cat trace_pipe
echo 0 > events/kprobes/brendan/enable
echo ‘-:brendan’ >> kprobe_events
此输出表明,在跟踪时,do\_nanosleep() 的返回值始终为“0”(成功)。
### 4.4 Filters and Triggers
Filters and triggers可以在 events/kprobes/… 目录中使用,就像 tracepoints一样。
这是带有参数的 do\_nanosleep() 上早期 kprobe 的格式文件(来自小节 4.2 Arguments):
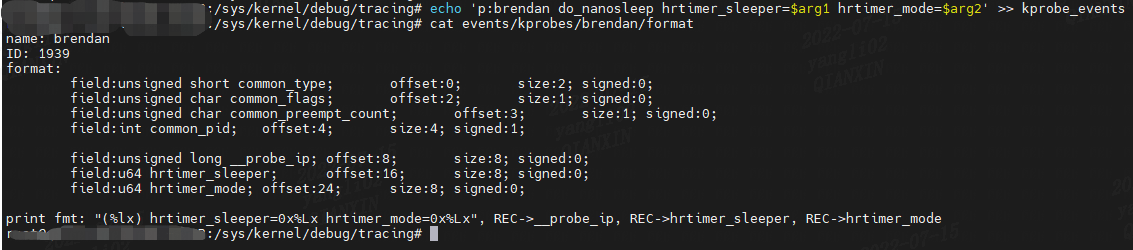
请注意,我的自定义 hrtimer\_sleeper 和 hrtimer\_mode 变量名称作为可与过滤器一起使用的字段可见。 例如:
echo ‘hrtimer_mode != 1’ > events/kprobes/brendan/filter
这只会跟踪 hrtimer\_mode 不等于 1 的 do\_nanosleep() 调用。
### 4.5 kprobe Profiling
启用 kprobe 时,Ftrace 会计算它们的事件。 这些计数可以打印在 kprobe\_profile 文件中。 例如:
echo ‘p:brendan do_nanosleep’ >> kprobe_events
echo 1 > events/kprobes/brendan/enable
cat trace_pipe
cat /sys/kernel/debug/tracing/kprobe_profile

通过 /sys/kernel/debug/tracing/kprobe\_profile 检查探测命中和探测未命中的总数。 第一列是事件名称,第二列是探测命中数,第三列是探测未命中数。
event name probe hits probe miss-hits
虽然您已经可以使用 function profiler 获取函数计数,但我发现 kprobe 探查器可用于检查监控软件使用的始终启用的 kprobe,以防某些触发过于频繁而应禁用( 如果可能的话)。
为了做好运维面试路上的助攻手,特整理了上百道 **【运维技术栈面试题集锦】** ,让你面试不慌心不跳,高薪offer怀里抱!
这次整理的面试题,**小到shell、MySQL,大到K8s等云原生技术栈,不仅适合运维新人入行面试需要,还适用于想提升进阶跳槽加薪的运维朋友。**

本份面试集锦涵盖了
* **174 道运维工程师面试题**
* **128道k8s面试题**
* **108道shell脚本面试题**
* **200道Linux面试题**
* **51道docker面试题**
* **35道Jenkis面试题**
* **78道MongoDB面试题**
* **17道ansible面试题**
* **60道dubbo面试题**
* **53道kafka面试**
* **18道mysql面试题**
* **40道nginx面试题**
* **77道redis面试题**
* **28道zookeeper**
**总计 1000+ 道面试题, 内容 又全含金量又高**
* **174道运维工程师面试题**
> 1、什么是运维?
> 2、在工作中,运维人员经常需要跟运营人员打交道,请问运营人员是做什么工作的?
> 3、现在给你三百台服务器,你怎么对他们进行管理?
> 4、简述raid0 raid1raid5二种工作模式的工作原理及特点
> 5、LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
> 6、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
> 7、Tomcat和Resin有什么区别,工作中你怎么选择?
> 8、什么是中间件?什么是jdk?
> 9、讲述一下Tomcat8005、8009、8080三个端口的含义?
> 10、什么叫CDN?
> 11、什么叫网站灰度发布?
> 12、简述DNS进行域名解析的过程?
> 13、RabbitMQ是什么东西?
> 14、讲一下Keepalived的工作原理?
> 15、讲述一下LVS三种模式的工作过程?
> 16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
> 17、如何重置mysql root密码?
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以点击这里获取!](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
*
* **174道运维工程师面试题**
> 1、什么是运维?
> 2、在工作中,运维人员经常需要跟运营人员打交道,请问运营人员是做什么工作的?
> 3、现在给你三百台服务器,你怎么对他们进行管理?
> 4、简述raid0 raid1raid5二种工作模式的工作原理及特点
> 5、LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
> 6、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
> 7、Tomcat和Resin有什么区别,工作中你怎么选择?
> 8、什么是中间件?什么是jdk?
> 9、讲述一下Tomcat8005、8009、8080三个端口的含义?
> 10、什么叫CDN?
> 11、什么叫网站灰度发布?
> 12、简述DNS进行域名解析的过程?
> 13、RabbitMQ是什么东西?
> 14、讲一下Keepalived的工作原理?
> 15、讲述一下LVS三种模式的工作过程?
> 16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
> 17、如何重置mysql root密码?
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以点击这里获取!](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 3181
3181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









