






最近在训练自己的PaddleOCR模型时,尝试多次每次评估acc始终为零,也一直没有出现最佳参数结果,但训练acc早达到了0.98,这是为什么呢?
 为了找出具体原因,于是进入train.py文件中debug查找原因,PaddleOCR在训练模型时,按照官方的指导教程,一般是在终端输入一下命令行的方式配置运行进行训练,如果想通过tools\train.py在右键运行或进入debug模式,就需要修改代码,具体参考PaddleOCR 如何修改代码进入手动调试模式-CSDN博客。
为了找出具体原因,于是进入train.py文件中debug查找原因,PaddleOCR在训练模型时,按照官方的指导教程,一般是在终端输入一下命令行的方式配置运行进行训练,如果想通过tools\train.py在右键运行或进入debug模式,就需要修改代码,具体参考PaddleOCR 如何修改代码进入手动调试模式-CSDN博客。
经排查发现是数据集量与配置文件中设置的不合适所导致,为了保证正常出现best_accuracy,在修改configs配置文件时,其中主要有两大注意点:
- 保证eval_batch_step(迭代次数要在总迭代次数内),以configs\rec\PP-OCRv3中的ch_PP-OCRv3_rec_distillation.yml文件为例
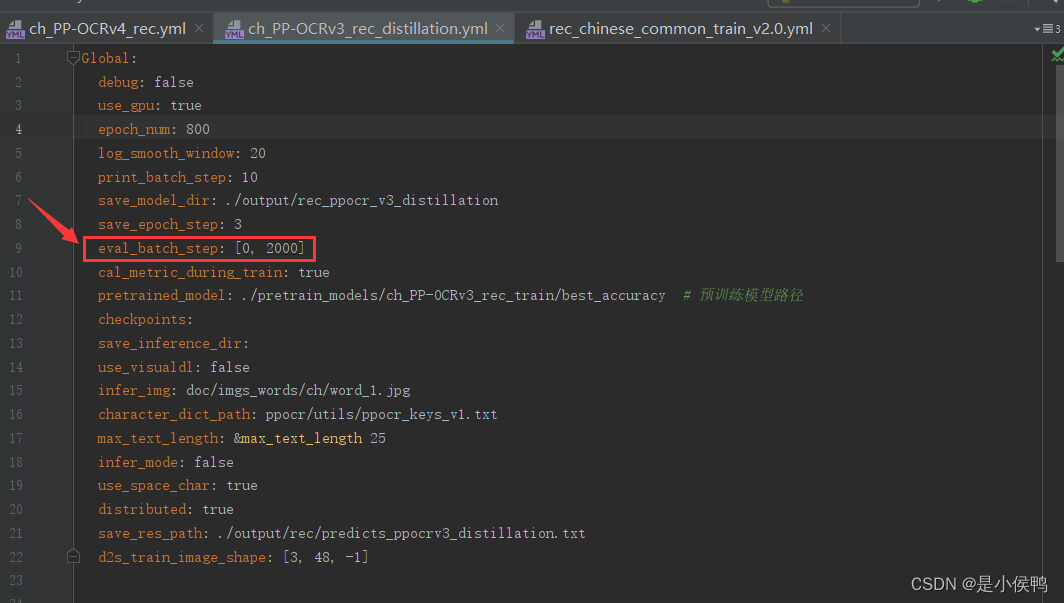
eval_batch_step设置位置,如上图所示标记处,官方的具体解释如下图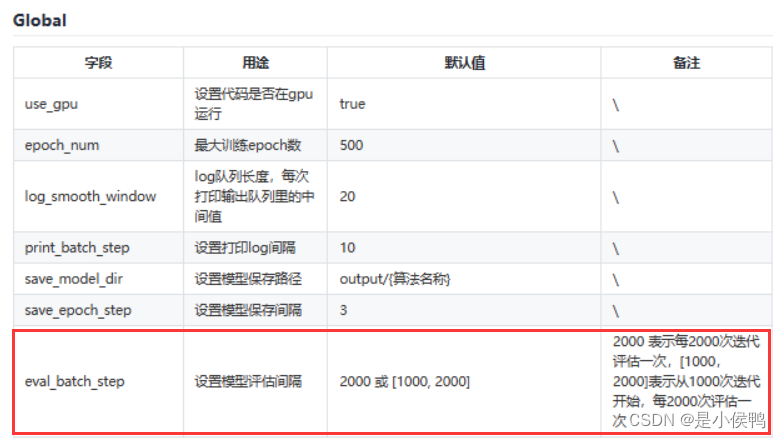
全局的总迭代次数global_step在训练的终端中有打印出来,如下图所示,因此对照此值,即小于此值模型训练才会进入eval评估(本图中总迭代次数为1500,而评估间隔为2000,所以未评估)。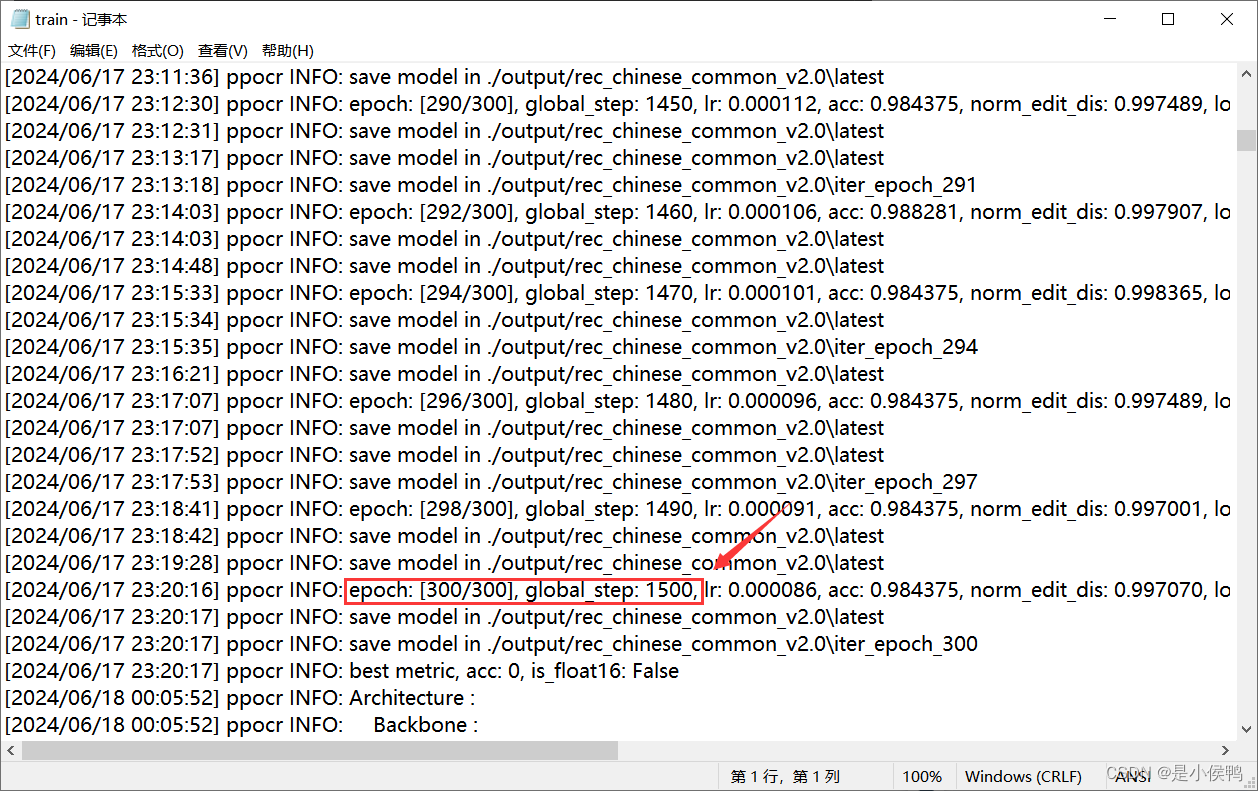
综上:如果没有根据总迭代次数,设置合理的评估区间,就不会出现best_accuracy,同时为确保best_accuracy值更准确,评估的次数要均匀合适。
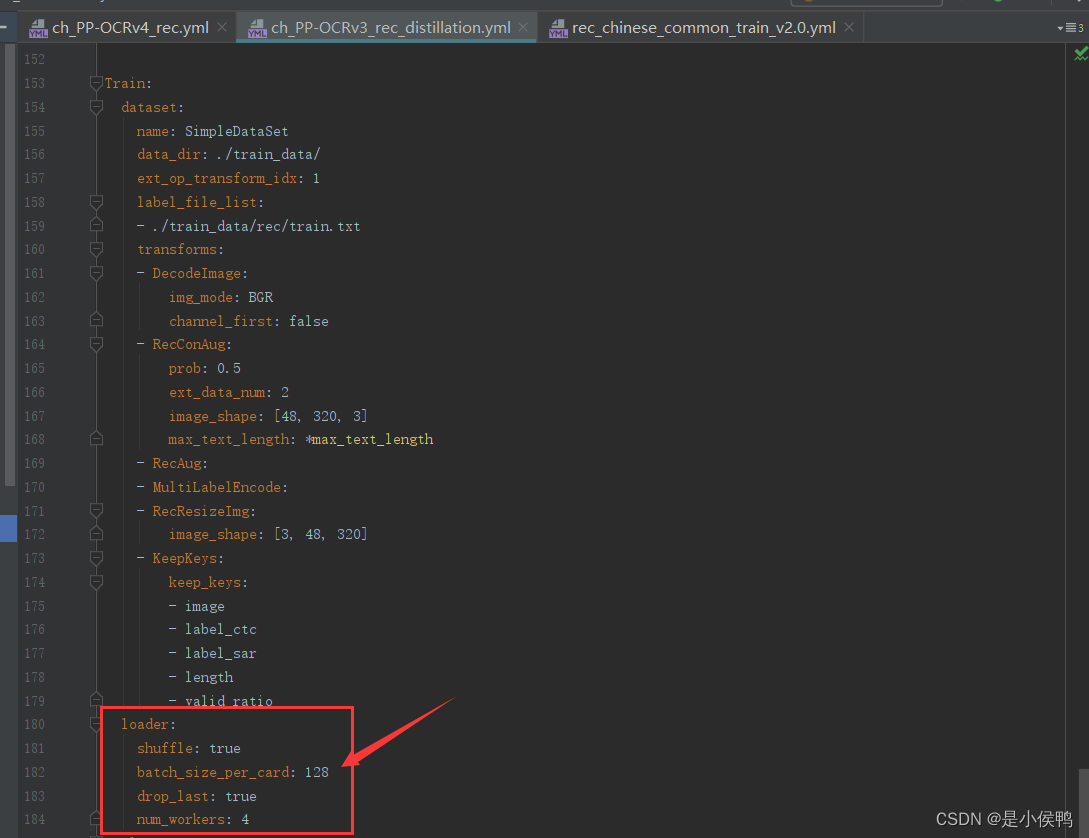
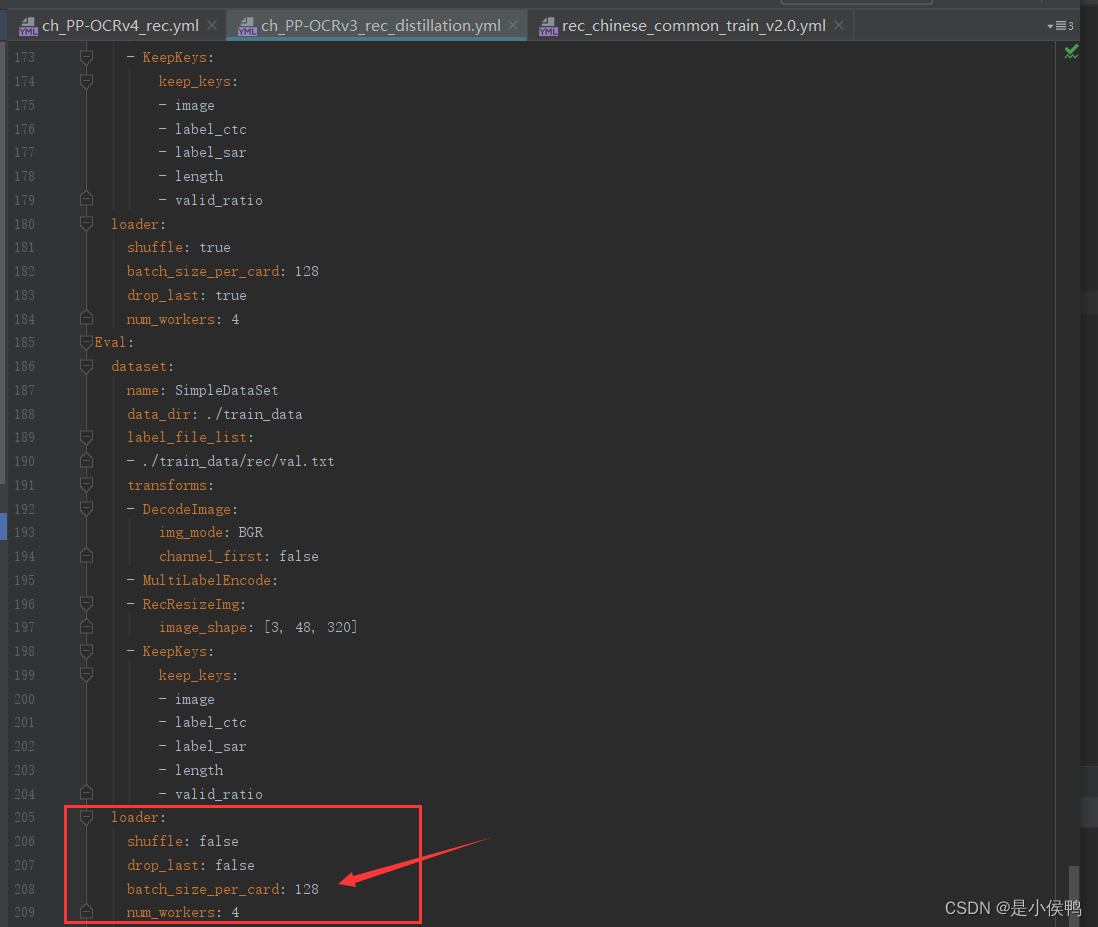
- train与eval中的数据集加载器loader中的batch_size_per_card大小需数据集大小而定,要确保其迭代次数大于等于1,如下图,具体迭代次数在训练信息目录最后两行。
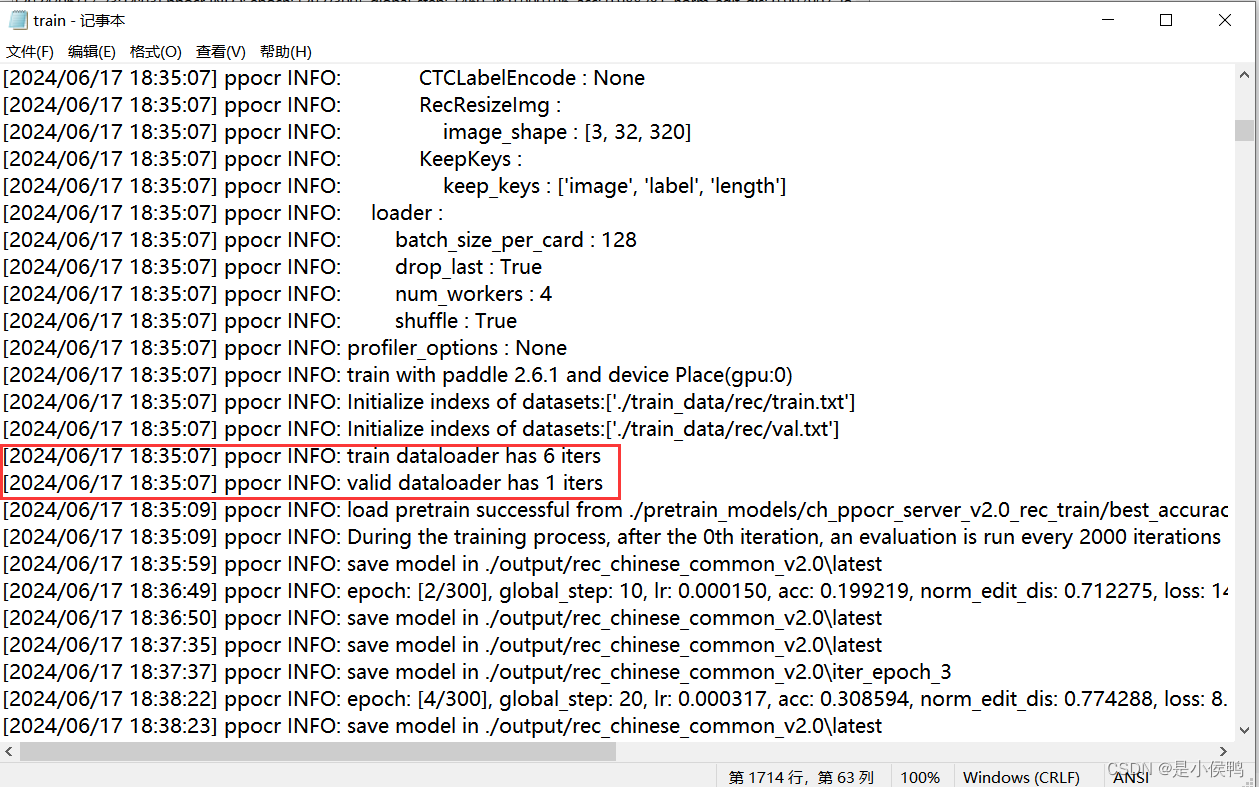 而其设置在configs配置文件中如下图所示位置,迭代次数等于train或eval中的图片数除batch大小,其中除不尽的余数也算计数1轮,所以我们要根据自己数据集大小合理设置其大小。
而其设置在configs配置文件中如下图所示位置,迭代次数等于train或eval中的图片数除batch大小,其中除不尽的余数也算计数1轮,所以我们要根据自己数据集大小合理设置其大小。















 1383
1383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









