







2024版
PyPDF2更新了一些用法,记录一下。
实现目标:
我的目标是将一个签名签到一个报告文件的首页,其他页保持不变。目标图如下:

代码:
在网络上搜到了解决方案,但是两年前的,稍微改了一下,代码如下。
from PyPDF2 import PdfWriter, PdfReader
def sign_pdf(input_path, output_path, sign_path):
"""
将源pdf首页签名,生成新的pdf文件(不改动源文件)
:param input_path: 源文件 路径
:param output_path: 新的签名pdf 路径
:param sign_path: 仅含有签名的pdf文件 路径
:return:
"""
# 读取含有签名的PDF文件内容,由于它只有一页,且第一页含有目标签名,所以取索引0
sign_pdf_obj = PdfReader(sign_path)
sign_page = sign_pdf_obj.pages[0]
# 读取待签名PDF,即源文件,并创建一个reader对象,用于内容处理
pdf_reader = PdfReader(input_path)
# 给签名文件创建一个writer对象,用于之后的合并(编辑)操作
pdf_writer = PdfWriter()
# 初始化原本的pdf文件页数列表。
# 一会儿需要将列表页加入到输出文件中,因为合并会导致输出文件变为一页
raw_page_list = pdf_reader.pages
# 给第一页加上签名 实际原理是将第一页与签名pdf文件的内容合并了
page = pdf_reader.pages[0]
page.merge_page(sign_page)
# 这里是将原本消失的页加回去
for _page in raw_page_list:
pdf_writer.add_page(_page)
# 保存为新的文档
with open(output_path, 'wb') as f:
pdf_writer.write(f)
# 以上注释是对代码作些解释,为了方便我以后能快速回顾我写的东西,实际编写代码入库时不要这么写。参数说明:
input_path 是源文件,即我想要给它签名的文件,它上面还没有签名。
output_path是结果文件,即我最后想获取到的目标文件,它和源文件一致,只是第一页有了签名。
sign_path是签名文件,它是一个仅有一页的pdf文件,上面有一个签名。如下图。
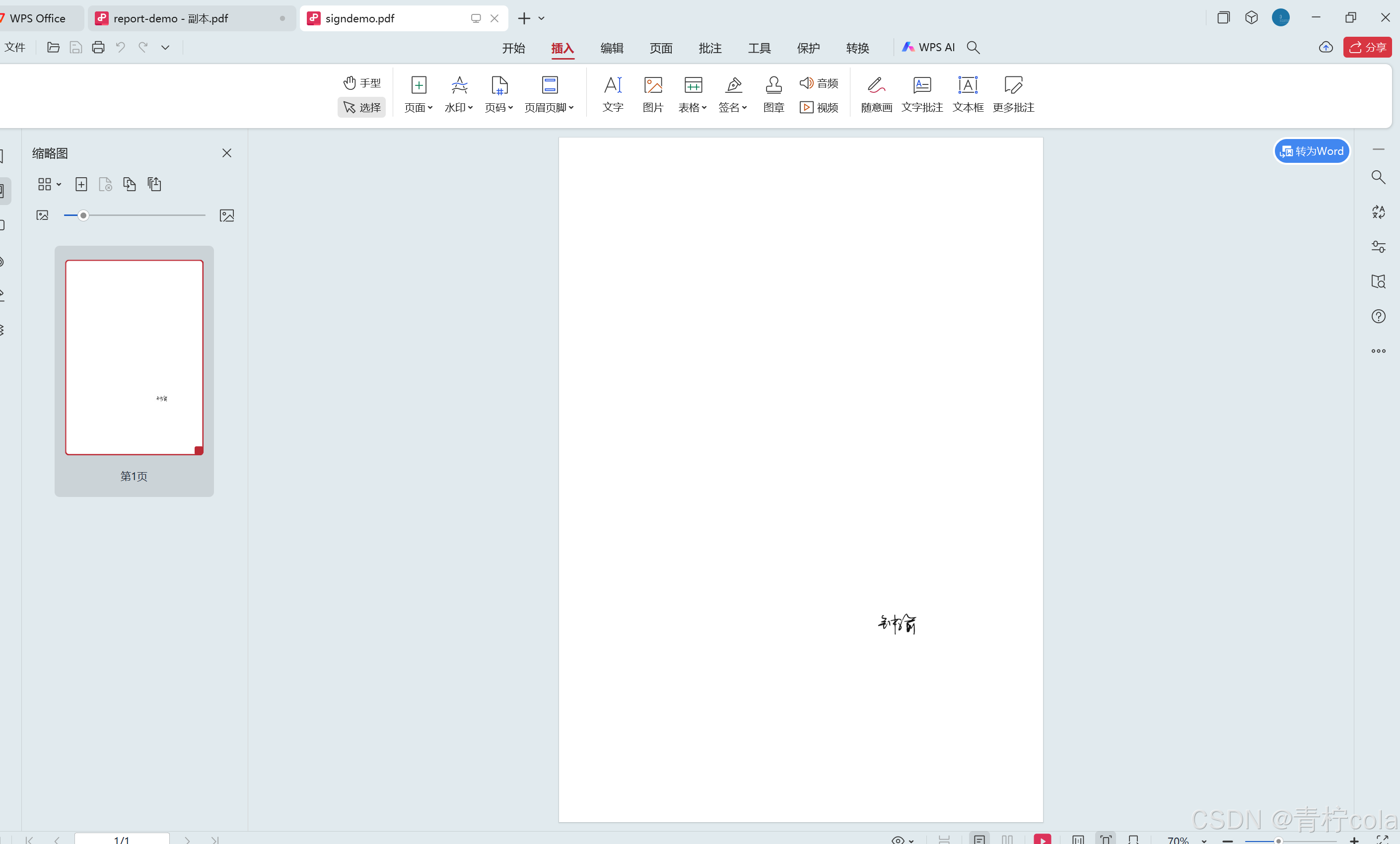
注意,这三个文件都得是pdf,在代码里我没有做文件类型检查,是因为我的程序其他部分确保了这三个文件的类型都是pdf。
接下来是这个函数的使用:
如下所见,report-demo.pdf是我的没签名的报告源文件,output.pdf是已签名的报告文件,我可以随意写它的路径和名字,signdemo.pdf就是上图的仅有签名的文件。
if __name__ == "__main__":
sign_pdf("./report-demo.pdf", "output.pdf", "./signdemo.pdf")最终效果会以signdemo.pdf文件中签名的位置而定,注意调好模板签名的位置。
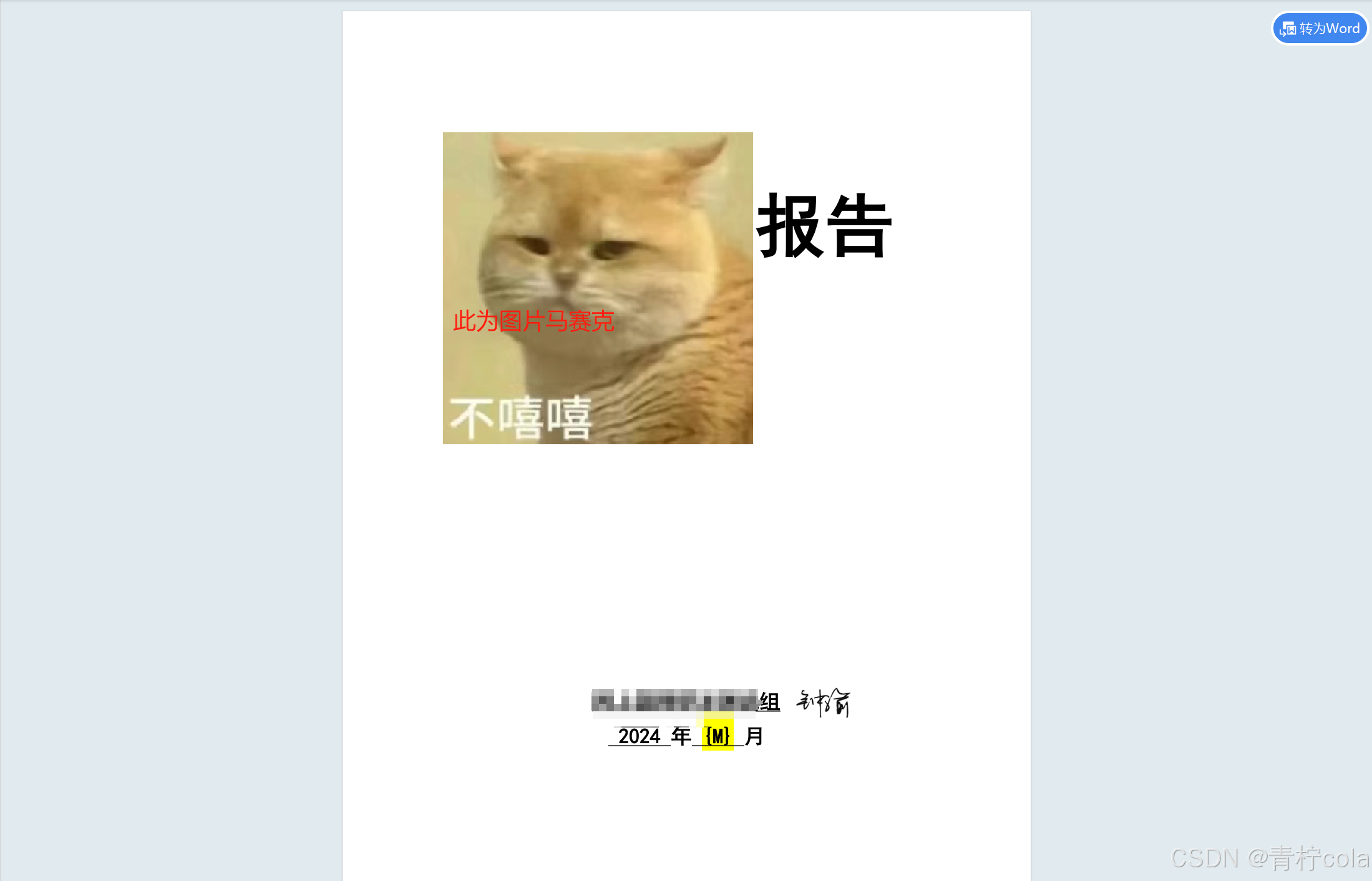
以上代码输出的output.pdf的效果如下。

















 412
412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









