







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Python全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。






既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Python知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024c (备注Python)

正文
pip install beautifulsoup4
实例代码:
from bs4 import BeautifulSoup
import requests
发送请求获取到 html 内容
response = requests.get(“https://www.example.com”)
html_content = response.text
创建 BeautifulSoup 对象
soup = BeautifulSoup(html,‘html.parser’)
创建 CSS 选择器查找元素
elements = soup.select(“.class-name”)
for element in elements:
print(element.text)
demo:
比如我现在想获取新浪新闻的列表:
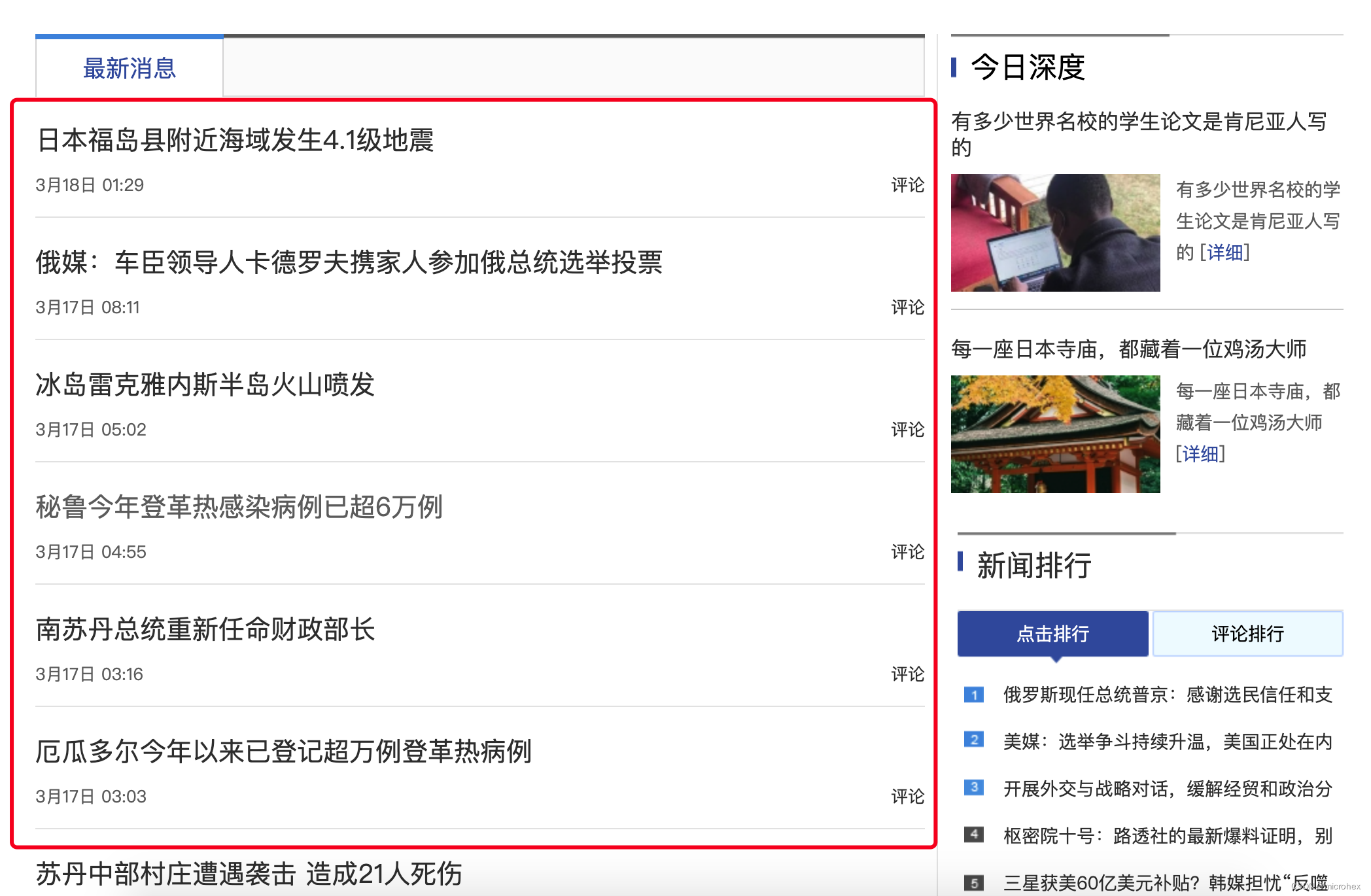
对 html 进行分析,我们可以发现 class name:

那么我们可以直接填入代码:
def try_to_get_world_news() :
response = requests.get("https://news.sina.com.cn/world/")
response.encoding = "utf-8"
html_data = response.text
# 创建 BeautifulSoup 对象
soup = BeautifulSoup(html_data, "html.parser")
# 通过css选择器cha查找元素
elements = soup.select(".news-item")
for element in elements:
if element is not None:
a_links = element.find_all('a')
if a_links is not None and len(a_links) > 0 :
a_link = a_links[0]
a_text = a_link.text.strip()
a_href = a_link.get('href')
print("文本:" + a_text + ",链接:" + a_href)
可以看到结果:

#### 2. lxml
另外一个强大的python库,也是用来处理 HTML 和 XML 文档。当然,它提供了XPath和CSS选择器等功能,也可以很方面的定位和提取HTML库。
安装
pip install lxml
当然你还可能需要安装一下 cssselect 这个库
pip install cssselect
代码实例
from lxml import html
import requests
import cssselect
创建请求对象,获取请求内容
response = requests.get(“https://www.example.com”)
html_content = response.text
创建 lxml 的 HTML 对象
tree = html.fromstring(html_content)
通过 css 选择器查找
elements = tree.cssselect(“.class-name”)
for element in elements:
print(element.text)
demo:
同样也是上面的例子,直接贴代码:
response = requests.get("https://news.sina.com.cn/world/")
response.encoding = "utf-8"
html_data = response.text
tree = html.fromstring(html_data)
elements = tree.cssselect(".news-item")

感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
料的朋友,可以添加V获取:vip1024c (备注python)**
[外链图片转存中…(img-Ce9FcxxH-1713163697672)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 988
988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









