







-
丰富数据集的操作功能,支持在线弹性扩缩容、元数据备份和恢复。
-
支持多样环境配置部署,满足用户的个性化部署配置需求。
-
新增数据缓存引擎实现,增加用户在公有云上的引擎选择。
Fluid 开源项目地址:https://github.com/fluid-cloudnative/fluid
这三大主要功能的开发需求来自众多社区用户的实际生产反馈,此外 Fluid v0.5 还进行了一些 bug 修复和文档更新,欢迎使用体验 Fluid v0.5!
Fluidv0.5 下载链接:https://github.com/fluid-cloudnative/fluid/releases
下文是本次新版本发布功能的进一步介绍。
===============================================================================
在本版本中 Fluid 重点丰富了核心抽象对象 —— Dataset(数据集)的相关操作功能,从而使数据密集型应用能够更好地利用云原生提供的弹性、可观测性等基础功能,并增强了用户对数据集管理的灵活性。
这是社区用户一直期待的功能!在 Fluid v0.5 之前,如果用户想要调整数据集的缓存能力,需要以全部卸载缓存引擎再重部署的方式完成。这种方式耗时耗力,还必须考虑数据缓存全部丢失的高昂代价。因此,在新版本中,我们为数据集提供了对缓存弹性扩缩容的支持,用户可以根据自己的场景需求,以不停机方式 on-the-fly 地按需增加某数据集的缓存容量以加速数据访问(扩容)或减少某个不频繁使用的数据集的缓存容量(缩容),从而实现更加精细的弹性资源分配,提高资源利用率。Fluid 内置的控制器会根据策略选择合适的扩缩容节点,例如在缩容时会结合节点上运行任务情况和节点缓存比例作为筛选条件。
执行弹性数据集的缓存能力弹性扩缩容,用户只需运行如下命令:
kubectl scale alluxioruntimes.data.fluid.io {datasetName} --replicas={num}
其中 datasetName 对应于数据集的名称,replicas 指定缓存节点的数目。
有关数据集手动扩缩容及其效果的演示视频:http://cloud.video.taobao.com/play/u/2987821887/p/1/e/6/t/1/302459823704.mp4
更多关于数据集手动扩缩容的操作细节,请参考 Github 上的示例文档。
该功能增强了 Fluid 数据集元数据管理的灵活性。先前的 Fluid v0.4 已经支持将数据集的元数据(例如,文件系统 inode tree)加载至本地,并且会记录数据集的一些关键统计信息(例如,数据量大小和文件数量)。然而,一旦用户销毁本地数据集,这些元数据信息也都将丢失,重新构建数据集时需再次从底层存储系统获取。
因此,在 Fluid v0.5 中,我们新增了一个 K8s 自定义资源对象 —— DataBackup,为用户提供了声明式的 API 接口,以控制数据备份的相关行为。DataBackup 自定义资源对象构建的一个简单示例如下所示:
apiVersion: data.fluid.io/v1alpha1
kind: DataBackup
metadata:
name: hbase-backup
spec:
dataset: hbase
backupPath: pvc://<pvcName>/subpath1/subpath2/
再次创建数据集时,只需新增一个指定备份文件位置的字段:
apiVersion: data.fluid.io/v1alpha1
kind: Dataset
metadata:
name: hbase
spec:
dataRestoreLocation:
path: pvc://pvc-local/subpath1/
mounts:
- mountPoint: https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/2.2.6/
此时,Fluid 将首先从备份文件加载元数据和数据集统计信息,从而很大地提高元数据加载速度。
更多关于进行数据集元数据备份与恢复的操作细节,请参考 Github 上的示例文档。
Fluid v0.5 还进一步增强了数据集的可观测性能力,具体包括两个部分:
[](
)1)与 Prometheus 相结合
该特性能够支持数据集的可用性和性能指标收集,并且通过 Grafana 进行可视化展示。目前已支持 AlluxioRuntime 的实现,使用者可以方便地了解当前可缓存节点、缓存空间、现有缓存比例、远程读、短路读等性能指标。整个配置过程非常简单,达到了对于数据集监控系统“开箱即用"的效果。
具体的使用方法,请参考 Github 上的示例文档。
[](
)2)新增数据集缓存命中率指标
该功能可以标识过去 1 分钟内对该数据集的全部访问中有多少访问命中了分布式缓存。该指标一方面能够帮助用户分析他们数据密集型应用中的性能瓶颈,量化查看 Fluid 在整个应用运行的工作流中起到的效果;另一方面能够帮助用户在应用性能提升和缓存资源占用间进行行权衡,做出合理的扩缩容决策。
这一指标被添加在 Fuild v0.5 的 Dataset.Status.CacheStates 的 Dataset CRD 资源状态中,具体来说包括:
-
Cache Hit Ratio:过去一分钟分布式缓存命中的访问百分比。
-
Local Hit Ratio:过去一分钟本地缓存命中的访问百分比。
-
Remote Hit Ratio:过去一分钟远程缓存命中的访问百分比。
注: 对于分布式缓存而言,数据命中有两种不同的缓存命中情况。本地缓存命中指的是访问发起者可直接在同结点访问到缓存数据。远程缓存命中指的是访问发起者需要通过网络访问其他结点上的缓存数据。
在 Fluid v0.5 中,用户可以使用以下命令方便地查看缓存命中率指标:
kubectl get dataset <dataset-name> -o wide
NAME ... CACHE HIT RATIO AGE
<dataset-name> ... 86.2% 16m
===============================================================================
自 Fluid 0.4 版本发布以来,我们根据社区用户实际部署反馈的问题和需求,对 Fluid 在多样环境下的部署配置增加了更多支持。
在 Fluid 中,Dataset 资源对象中所定义的远程文件是可被调度的,这意味着你能够像管理 Pod 一样管理远程文件缓存到 Kubernetes 集群上的位置。执行计算的 Pod 可以通过 Fuse 客户端访问数据文件。在先前版本的 Fluid 中,Fuse 客户端总是会调度到缓存所在的节点上,但是用户不能自由控制 Fuse 的调度。
在 Fluid v0.5 中,我们为 Fuse 新增了 global 部署模式。在该模式下,Fuse 默认会全局部署到所有节点上。用户也可以通过指定 Fuse 的 nodeSelector 来影响 Fuse 的调度结果。同时,缓存会优先调度部署在执行计算 Pod 数量较多的节点上。
具体使用非常简单,可以参考 Github 上的示例文档。
很多社区用户使用分布式缓存系统 Alluxio 作为 Fluid 数据集的缓存引擎。在数据集持久化存储于 HDFS 文件系统的情况下,要使得 Alluxio 能够正常访问底层 HDFS,Alluxio 集群需要提前获取该 HDFS 的各类配置信息。
在 Fluid v0.5 中,我们使用 Kubernetes 的原生资源为上述场景提供支持。用户首先需要将 HDFS 的相关配置文件(e.g. hdfs-site.xml 和 core-site.xml)以 ConfigMap 方式创建到 Kubernetes 环境中,接着在创建的 AlluxioRuntime 资源对象中引用上述创建的 ConfigMap 从而实现上述功能。
AlluxioRuntime 资源对象的一个示例如下所示:
apiVersion: data.fluid.io/v1alpha1
kind: AlluxioRuntime
metadata:
# **Kafka**进阶篇知识点

**Kafka**高级篇知识点

**44个Kafka知识点(基础+进阶+高级)解析如下**
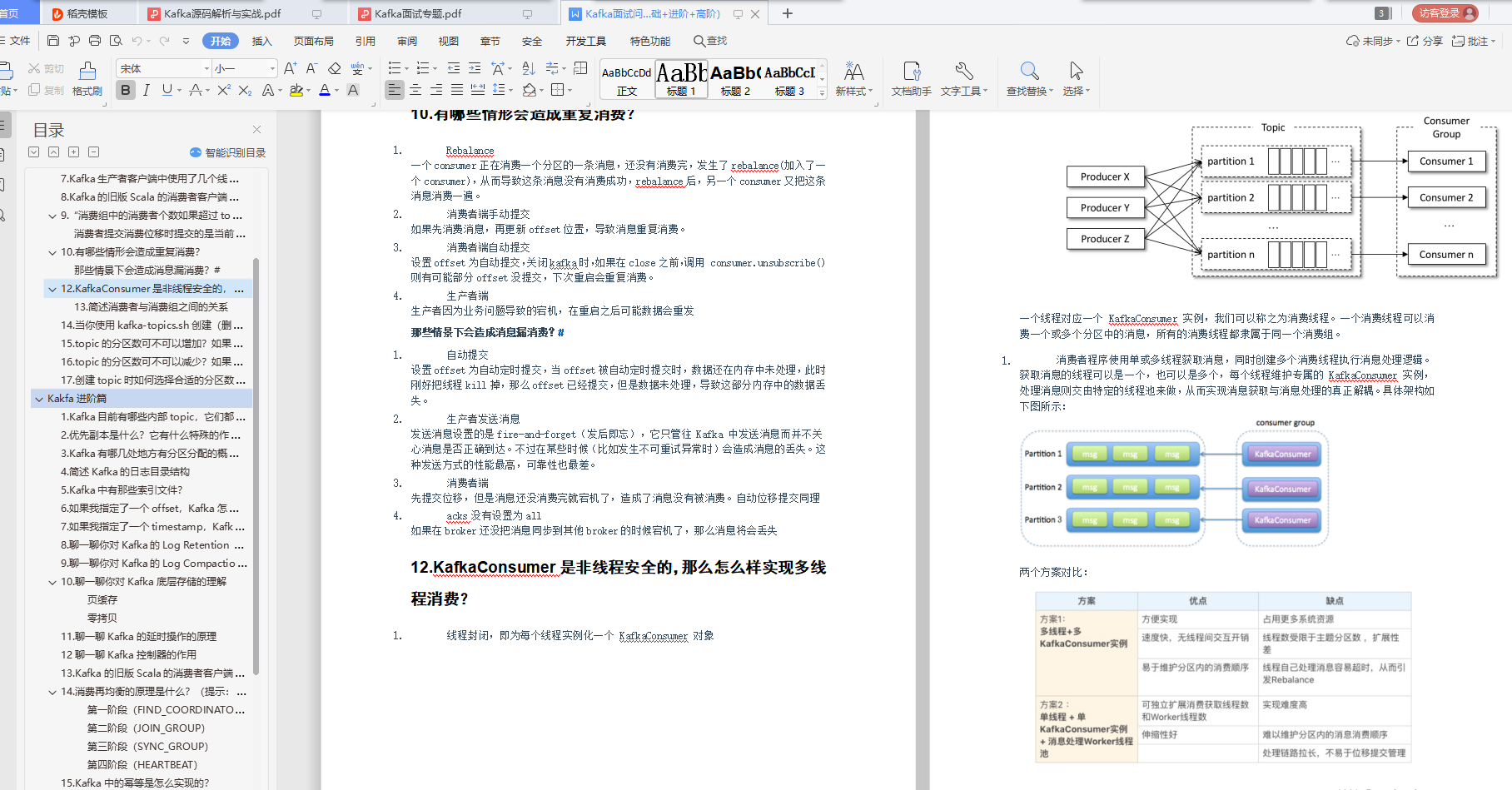
由于篇幅有限,小编已将上面介绍的**《Kafka源码解析与实战》、Kafka面试专题解析、复习学习必备44个Kafka知识点(基础+进阶+高级)都整理成册,全部都是PDF文档**
etadata:
# **Kafka**进阶篇知识点
[外链图片转存中...(img-DVBAAldr-1630634183475)]
**Kafka**高级篇知识点
[外链图片转存中...(img-lF83yP28-1630634183476)]
**44个Kafka知识点(基础+进阶+高级)解析如下**
[外链图片转存中...(img-ogxofiQS-1630634183477)]
由于篇幅有限,小编已将上面介绍的**《Kafka源码解析与实战》、Kafka面试专题解析、复习学习必备44个Kafka知识点(基础+进阶+高级)都整理成册,全部都是PDF文档**
**[CodeChina开源项目:【一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频】](https://codechina.csdn.net/m0_60958482/java-p7)**















 571
571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









