







但这个技术是不利于爬虫的爬取的,所以这个时候,我们就要费点功夫了。
很幸运的是,拉钩采用了这种技术。异步加载的信息,我们需要借助chrome浏览器的小工具进行分析,按F12即可打开,点击Nerwork进入网络分析界面,界面如下:
这时候是一片空白,我们按F5刷新一下刷新一下,就可以看到一系列的网络请求了。
然后我们就开始找可疑的网页资源。首先,图片,css什么之类的可以跳过,一般来说,关注点放在xhr这种类型请求上,如下:
这类数据一般都会用json格式,我们也可以尝试在过滤器中输入json,来筛选寻找。
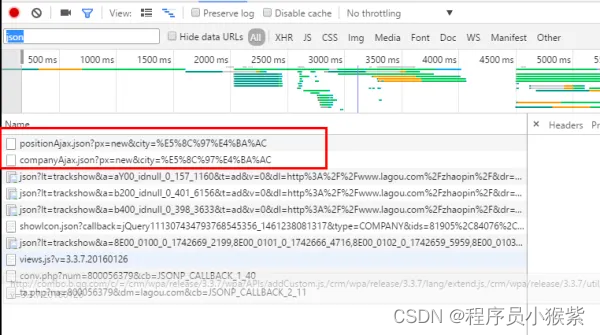
上图发现了两个xhr请求,从字面意思看很有可能是我们需要的信息,右键点击,在另一个界面打开:

what is this?Are you kidding me?嗯,这里是个坑,同样在写爬虫代码时候,如果在http请求中,不加入请求头信息,服务器返回信息也是这样的,但是笔者不明白的是,为什么,在这里笔者直接用浏览器新开窗口,也是这个拒绝访问的界面。如果有大神知道,希望给解解惑,拜谢!
回到正题,虽然新开窗口,无法访问,但条条大陆通罗马,我们可以在右边的框中,切换到“Preview”,然后点content——positionResult查看,能看到是关于职位的信息,以键值对的格式呈现,这就是json格式,特别适合网页数据交换。
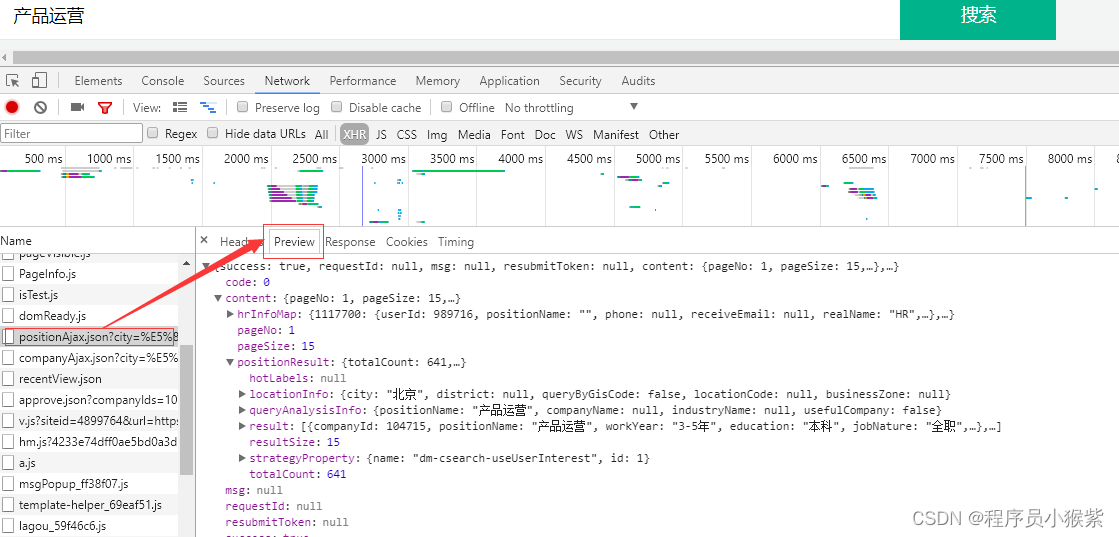
第一步网页分析,至此结束,下一步,我们来构造请求网址。
第二步,网址构造
在“Headers”中,看到网页地址,通过观察网页地址可以发现推测出: http://www.lagou.com/jobs/positionAjax.json?这一段是固定的,剩下的我们发现有个city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false&isSchoolJob=0
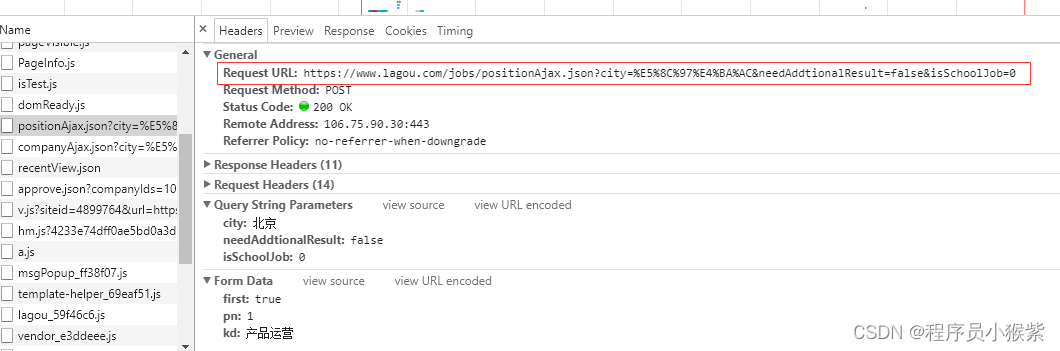
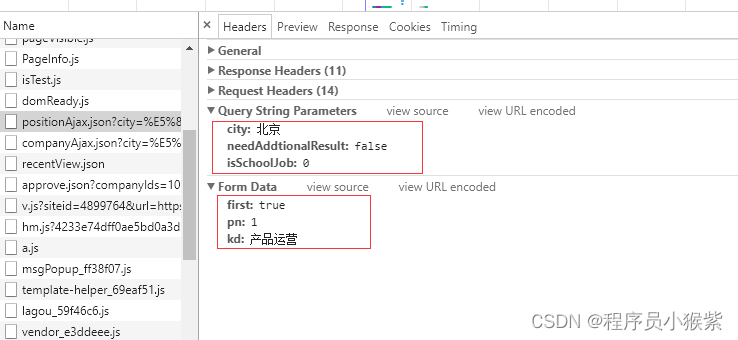
再查看请求发送参数列表,到这里我们可以肯定city参数便是城市,pn参数便是页数,kd参数便是职位关键字。
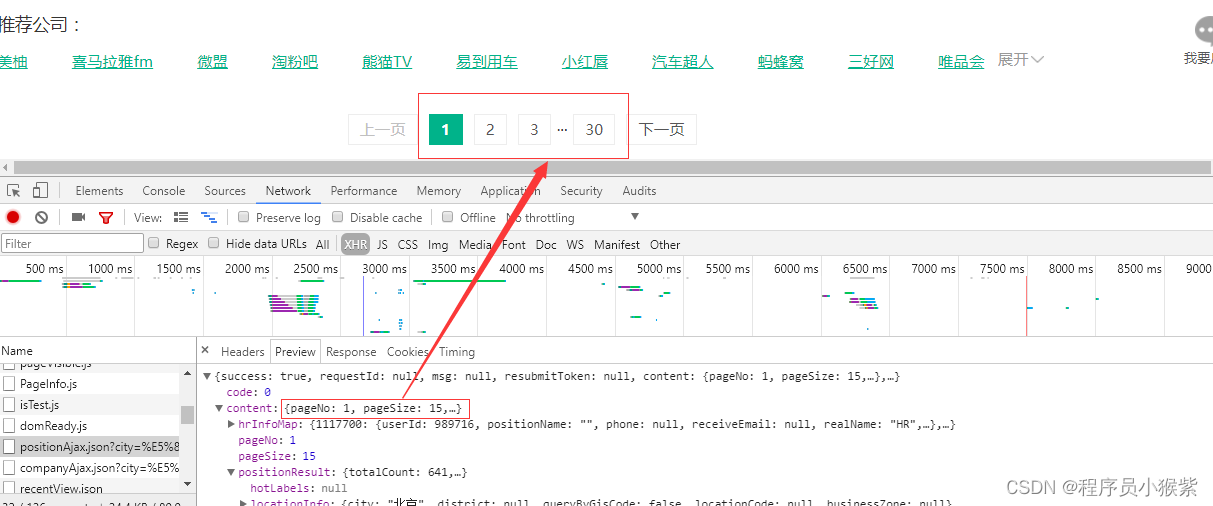
当然这只是一个网页的内容,对于更多页面的内容,怎么获取呢?再来看看关于“产品运营”职位,一共有30页,每页有15个数据,所以我们只需要构造循环,遍历每一页的数据。
第三步,编写爬虫脚本写代码
需要说明的是因为这个网页的格式是用的json,那么我们可以用json格式很好的读出内容。 这里我们切换成到previe
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 927
927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









