







a = open('Z:/test.txt','r')
# for line in f 的方式循环遍历每一行, 功能和readline类似,返回的line是字符串,所以可以使用字符串的成员函数
for line in a:
print(line.strip())
#执行结果:
hello world
hello python
#或者:使用列表解析语法
a = open('Z:/test.txt','r')
data = [line.strip() for line in a.readlines()]
print(data) #['hello world', 'hello python']
readlines和for line in f: 的区别:
第一种方法是全部读取->只读取一次 时间快,但是占空间。第二种方式是隔行读取 ->读取多次,时间慢,但是省空间。读取大文件选方式2
写文件
write: 向文件中写一段字符串
本文作者链接:https://blog.csdn.net/chuxinchangcun?spm=1019.2139.3001.5343 (反爬)
- 如需写文件, 必须要按照 ‘w’ 或者 ‘a’ 的方式打开文件. 否则会写失败.
a = open('Z:/test.txt','r')
a.write("hello Mango") #io.UnsupportedOperation: not writable
a = open('Z:/test.txt','w')
a.write("hello Mango") #用w方式打开,原文件的内容被删除
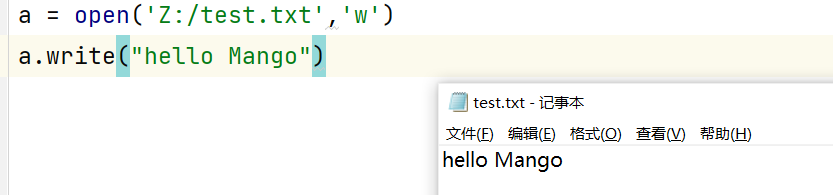
a = open('Z:/test.txt','a')
a.write("hello Lemon") #以a的方式打开->追加
writelines: 参数是一个列表, 列表中的每一个元素是一个字符串.
a = open('Z:/test.txt','w')
w = ['Mango\n','hello\n',' world\n']
a.writelines(w)#把列表的内容写入到文件中

并没有一个 writeline 这样的函数. 因为这个动作等价于 write 时在字符串后面加上 ‘\n’. 同理, 使用
writelines的时候, 也需要保证每一个元素的末尾, 都带有 ‘\n’
关于读写缓冲区
学习Linux我们知道, C语言库函数中的fread, fwrite和系统调用read, write相比, 功能是类似的. 但是
fread/fwrite是带有缓冲区的
Python的文件读写操作, 既可以支持带缓冲区, 也可以选择不带缓冲区.
在使用open函数打开一个文件的时候, 其实还有第三个参数, 可以指定是否使用缓冲区, 以及缓冲区的大小是多少 (查看 help(open) 以及 print(_doc_) ).
a = open('Z:/test.txt','r')
print(a.__doc__)
print(help(open))
本文作者链接:https://blog.csdn.net/chuxinchangcun?spm=1019.2139.3001.5343 (反爬)
使用flush方法可以立即刷新缓冲区
操作文件指针
文件具备随机访问能力. 这个过程是通过操作文件指针完成的.
seek: 将文件指针移动到从文件开头算起的第几个字节上. 有两个参数.
第一个参数offset表示偏移的字节数.
第二个参数whence表示偏移量的起始位置在哪. 值为0, 表示从开头计算, 值为1, 表示从当前位置, 值为2, 表示从文件结尾位置.
tell: 获取当前文件指针指向的位置. 返回当前位置到文件开头的偏移量.
文件对象内建属性

with语句和上下文管理器
本文作者链接:https://blog.csdn.net/chuxinchangcun?spm=1019.2139.3001.5343 (反爬)
我们刚才说了, 用完的文件对象, 要及时关闭, 否则可能会引起句柄泄露.
但是如果逻辑比较繁琐, 或者我们忘记了手动调用close怎么办?
def func():
f = open('Z:/test.txt','r')
x =10
if x==10:
return
#执行文件操作
f.close() #上面提前return,导致内存泄漏
解决:在每一个return前先关闭文件
def func():
f = open('Z:/test.txt','r')
x =10
if x==10:
f.close()
return
#执行文件操作
f.close()
但是如果抛出异常也会导致文件没有关闭:
def func():
f = open('Z:/test.txt','r')
x =10
a = [1,2,3]
print(a[100]) #越界:IndexError: list index out of range
if x==10:
f.close()
return
#执行文件操作
f.close()
func()
C++中使用 “智能指针” 这样的方式来管理内存/句柄的释放, 借助对象的构造函数和析构函数, 自动完成释
放过程.
但是Python中对象的回收取决于GC机制, 并不像C++中时效性那么强.
Python中引入了上下文管理器来解决这类问题.
def func():
with open('Z:/test.txt','r') as f: #上下文管理器
#文件操作
pass #空语句
可以更改编码格式:
with open('Z:/test.txt', 'r',encoding='utf-8') as f:
print(f.readline())
with open('Z:/test.txt', 'r',encoding='utf-8') as f:
for line in f:
print(line.strip())
#执行结果:
Mango
hello
world
在with语句块内进行文件操作. 当文件操作完毕之后, 出了with语句之外. 就会自动执行f的关闭操作.
一个支持上下文协议的对象才能被应用于with语句中. 我们将这种对象称为上下文管理器. Python中很多
内置对象都是上下文管理器, 例如文件对象, 线程锁对象等.
文件系统的基础操作
文件路径操作
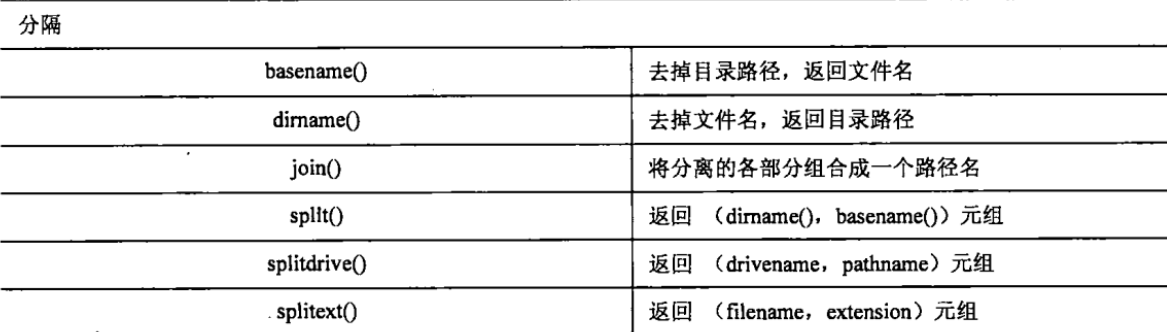
os.path这个模块中, 包含了一些实用的路径操作的函数
basename:去掉目录路径,返回文件名
dirname:去掉文件名,返回目录路径
import os.path
p = '/aaa/bbb/ccc.txt'
print(os.path.dirname(p)) # /aaa/bbb
print(os.path.basename(p)) #ccc.txt
split:返回(dirname(),basename())的元组
本文作者链接:https://blog.csdn.net/chuxinchangcun?spm=1019.2139.3001.5343 (反爬)
import os.path as path
p = '/aaa/bbb/ccc.txt'
print(path.split(p)) #('/aaa/bbb', 'ccc.txt')
splitext:返回(filename,extension)元组 extension:文件的后缀名
import os.path as path
p = '/aaa/bbb/ccc.txt'
print(path.splitext(p))#('/aaa/bbb/ccc', '.txt')
exists:返回文件是否存在
import os.path as path
p = '/aaa/bbb/ccc.txt'
print(path.exists(p)) #False
p = 'Z:/test.txt'
print(path.exists(p)) #True
分隔
信息

查询

常用文件系统操作
os模块中包含了很多对文件/目录的基础操作, 参见下表.
walk:生成一个目录树下的所有文件名
- 返回的是一个三元组:当前目录,当前目录下的目录,当前目录含有哪些文件
- 自动完成递归
本文作者链接:https://blog.csdn.net/chuxinchangcun?spm=1019.2139.3001.5343(反爬)
import os.path as path
import os
p = 'Z:/test'
for item in os.walk(p):
print(item)
#执行结果:
('Z:/test', ['a', 'b'], [])
('Z:/test\\a', ['aa'], [])
('Z:/test\\a\\aa', [], ['aa.txt'])
('Z:/test\\b', ['c'], ['b.txt'])
('Z:/test\\b\\c', [], ['c.txt'])
因为返回的是三元组,所以可以写成: 打印完整路径
base:当前目录
_ 当前目录中含哪些目录,不需要用,所以用占位符代替
files:当前目录含有哪些文件
import os.path as path
import os
p = 'Z:/test'
#打印完整路径
for base,_,files in os.walk(p):
for f in files:
print(base+f)
#执行结果:
Z:/test\a\aaaa.txt
Z:/test\bb.txt
Z:/test\b\cc.txt
remove:删除文件
import os.path as path
import os
p = 'Z:/test/'
print(path.exists(p+'b/b.txt')) #True
os.remove(p+'b/b.txt') #删除路径为: Z:/test/b/b.txt文件
print(path.exists(p+'b/b.txt')) #False
listdir:列出当前目录的文件
import os.path as path
import os
p = 'Z:/test/'
print(os.listdir(p))#列出当前目录的文件 #['a', 'b']
最后
🍅 硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
🍅 技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
🍅 面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
🍅 知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1465
1465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









