







头指针VS头结点
头指针和头结点是两个不同概念。
链表是它们的范畴。
1.头指针是指向链表第一个节点的指针,如果此链表第一个节点是头结点,那么头指针就指向头结点。
2.头结点内通常不储存数据,但不排除例外,有时候可能会储存链表长度。
理解头指针:
void ListTemp<T>::addHead(const T& newData)//这里展示的双向链表从头插入新的结点的过程
{
Node* newHead = new Node;
newHead->data = newData;
if (size == 0)
{
newHead->next = head;
newHead->pre = head;//注意:这里的head,包括前面定义Node * head 的地方,head都是头指针的意思。
head = newHead;
size++;
}
else
{
newHead->next = head;
head->pre = newHead;
newHead->pre = NULL;
head = newHead;
size++;
}
}
代码过程图示
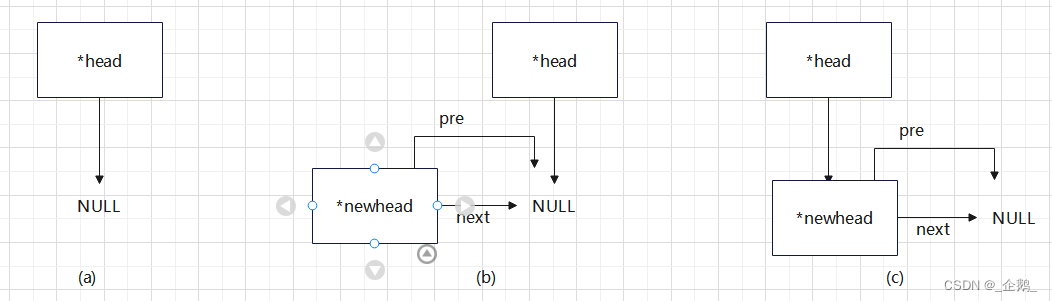
理解头结点:
链表分为带头结点的链表和不带头结点的链表。
(无论带不带头结点,头指针是一直存在的)
如何理解它们的概念呢?
以单链表为例:
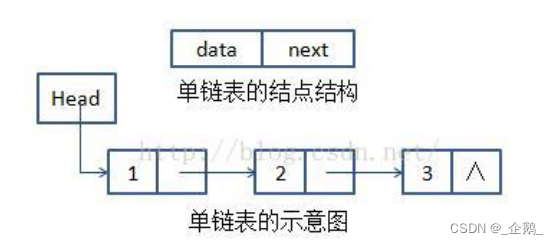
这是不带头结点的单链表。

这是带头结点的单链表。
下面展示二者在代码上的区别
//不带头结点的单链表的初始化
void LinkedListInit1(LinkedList L)
{
L=NULL;
}
//带头结点的单链表的初始化
void LinkedListInit2(LinkedList L)
{
L=(LNode *)malloc(sizeof(LNode));
if(L==NULL)
{
printf("申请空间失败!");
exit(0);
}
L->next=NULL;
}
从代码的角度来讲,我们更愿意使用带头结点的单链表,因为如果不带头结点,在对链表的增删改查中,我们需要进行分类讨论,很麻烦。
但在学校数据结构课程中,实验要求使用“空表”,于是,在上述理解头指针部分的代码,是基于无头结点的情况写的。
刚刚上面代码过程示意图(无头结点):
补充一个有头结点的过程示意图(有头结点):
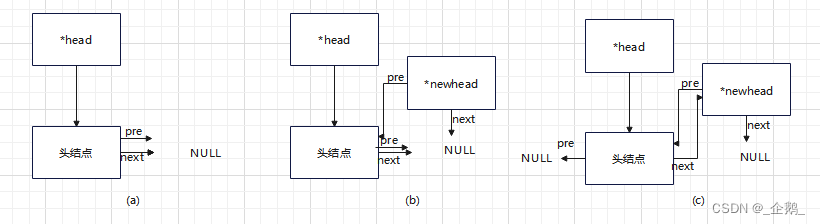
对比两个图就能区分有头结点与没有头结点的两种链表。
也理解了头指针和头结点的关系。
头指针一定指向第一个结点,但这个结点不一定是头结点。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









