







 VideoFusion是阿里达摩院提出的一种新型视频生成技术,它利用DPM对图像和视频序列进行生成,摒弃了传统的super-resolution方法。该方法通过分解噪声来处理视频的时间相关性,基础噪声确保帧间一致性,残差噪声则增加多样性。实验在多个数据集上展示了其效果,并且提供了开源代码和预训练模型。
VideoFusion是阿里达摩院提出的一种新型视频生成技术,它利用DPM对图像和视频序列进行生成,摒弃了传统的super-resolution方法。该方法通过分解噪声来处理视频的时间相关性,基础噪声确保帧间一致性,残差噪声则增加多样性。实验在多个数据集上展示了其效果,并且提供了开源代码和预训练模型。
前言
VideoFusion[1] 是阿里达摩院在今年3月提出的一种新的基于 DPM 的视频生成方法。和之前的一些视频生成方法(Imagen Video、Make-A-Video等)相比,VideoFusion 摒弃了常见的 spatial/temporal super-resolution 方法,完全使用 DPM 来做图像和视频序列的生成。此外,VideoFusion 相关的模型和代码也在达摩院的 ModelScope 上进行了开源[2] ,可以直接在网页上直接实现相关的 demo。本文将简要介绍 VideoFusion 的原理以及相应的本地部署方法。
原理
扩散模型(Diffusion Probabilistic Model,DPM)在图像生成领域取得了非常大的进展,可以生成高质量、多样的图像。因此,一种非常自然的想法就是利用扩散模型来生成视频。然而,目前基于扩散模型的视频生成还处于一个比较初级的阶段。因为视频和图像相比是更高维的数据(多了一个时间维度),并且在 spatial-temporal 上具有更强的相关性。
扩散模型一般有两个过程,加噪(noising)过程和去噪(denoising)过程[3]。之前的一些工作中,当作者使用DPMs 来生成图像时,不同的关键帧往往使用不同的 noise。然而,我们知道,视频的帧与帧之间具有很强的相关性,相邻两帧的图像往往大部分内容是相似的,只有少部分内容是不同的。使用不同噪声生成的图像,很难保证具有足够强的相关性。因此,VideoDefusion 尝试将视频生成过程中的噪声(noise)进行分解,将噪声分成基础噪声(base noise)和残差噪声(residual noise)。其中,基础噪声保证视频帧与帧之间大部分内容的一致性,是视频中所有帧共享的噪声;残差噪声负责保证帧与帧之间的差异,保证视频的多样性,不同帧的残差噪声是不相同的。

此外,作者还发现,使用这种方法实际上是将视频的风格和动作进行了分解(就像是 GAN-based 方法的 content code 和 motion code)。作者给出了一张图来演示这种区别,Figure 1 中演示了三段视频,每一行都是一个视频。第一行和第二行两个视频共享基础噪声,所以体现到生成的视频中就是视频风格(背景、穿着、色调)相同,动作不同;第二行和第三行两个视频共享残差噪声,体现到生成的视频中就是动作相同,视频风格不同。
方法
图像 DPM(Diffusion Probabilistic Model)

视频DPM

分解 Diffusion 过程

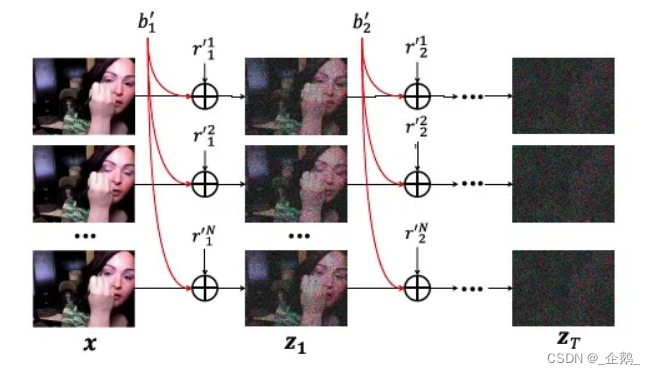
作者也贴了张图介绍了一下 VideoFusion 的 noising 过程,实际就是每次 noising 加上两个噪声,一个是基础噪声b,只根据扩散 step 变化,加到视频中所有帧上,另一个是残差噪声r,每一帧每一个 step 的残差噪声都不同。
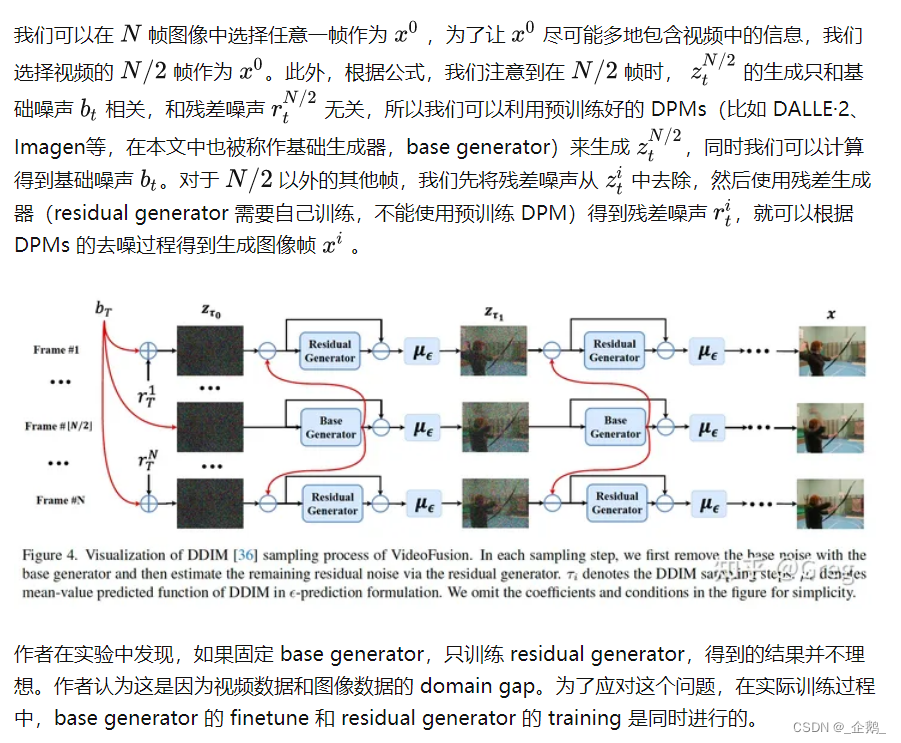
使用预训练的DPM
实验
作者主要使用了三个数据集(UCF101、Sky Time-lapse、TaiChi-HD做定量分析,用 Fréchet Video Distance (FVD) 、Kernel Video Distance (KVD) 、Inception Score (IS)作为评价指标。此外,作者在 WebVid-10M 上训练了一个 text-to-video 的模型,用来定性评估模型图像的生成效果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









