







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前在阿里
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

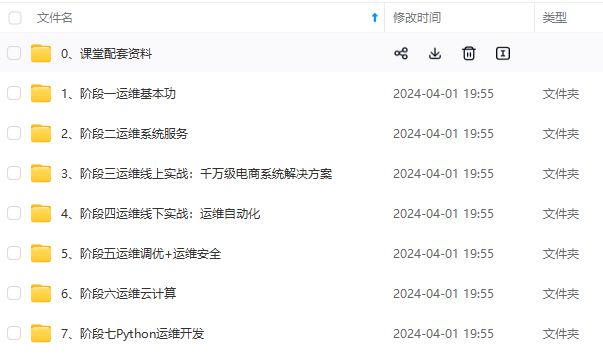
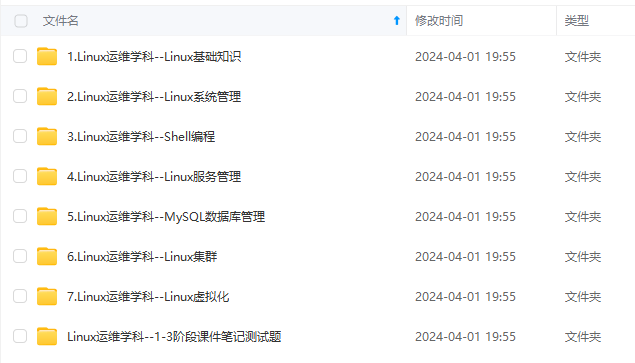
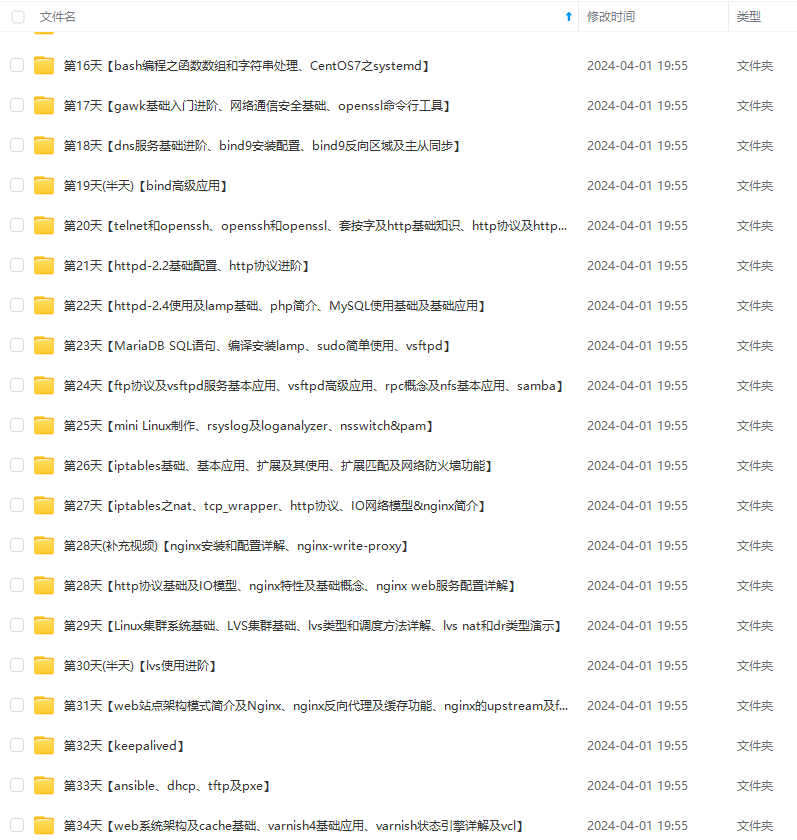
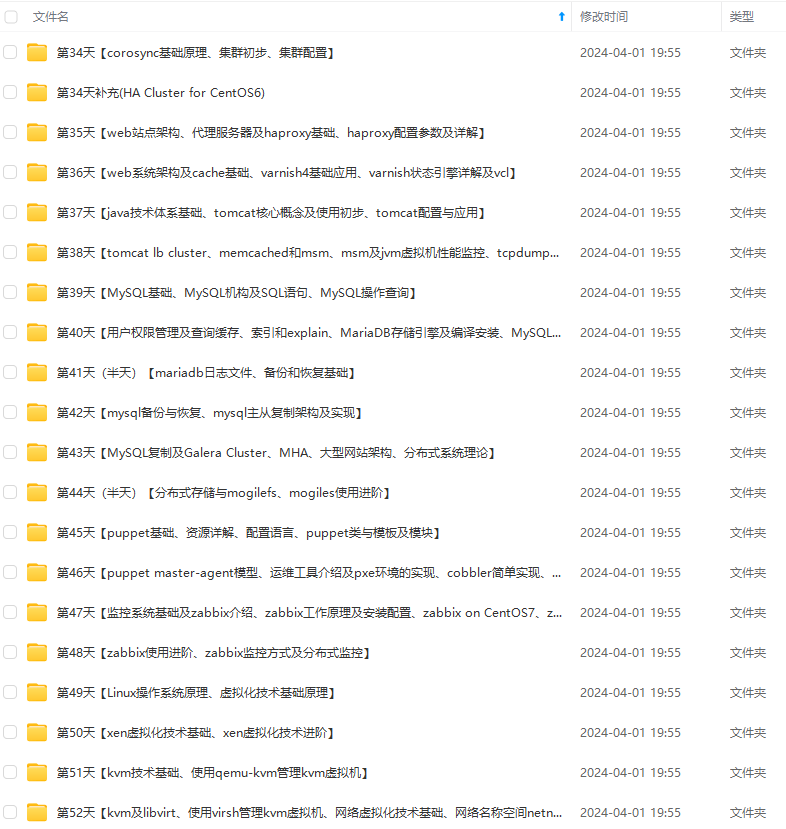
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
一、部署Zookeeper
1、创建一个网络
# app-tier:网络名称 # –driver:网络类型为bridge
docker network create app-kafka --driver bridge
2、拉取Zookeeper镜像
docker pull bitnami/zookeeper:latest
3、运行Zookeeper
# Kafka依赖zookeeper所以先安装zookeeper
# -p:设置映射端口(默认2181)
# -d:后台启动
docker run -d --name zookeeper-server \
-p 2181:2181 \
--network app-kafka \
-e ALLOW_ANONYMOUS_LOGIN=yes \
bitnami/zookeeper:latest
二、部署Kafka
1、拉取Kafka镜像
docker pull bitnami/kafka:latest
2、运行Kafka
# 安装并运行Kafka,
# –name:容器名称
# -p:设置映射端口(默认9092 )
# -d:后台启动
# ALLOW_PLAINTEXT_LISTENER任何人可以访问
# KAFKA_CFG_ZOOKEEPER_CONNECT链接的zookeeper
# KAFKA_ADVERTISED_HOST_NAME当前主机IP或地址(重点:如果是服务器部署则配服务器IP或域名否则客户端监听消息会报地址错误)
# -e KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://8.142.83.78:9092 这个IP一定要是外网IP,不要设置为内网IP
docker run -d --name kafka-server \
--network app-kafka \
-p 9092:9092 \
-e ALLOW_PLAINTEXT_LISTENER=yes \
-e KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper-server:2181 \
-e KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://8.142.83.78:9092 \
bitnami/kafka:latest
三、kafka-map图形化管理工具
# 图形化管理工具
# 访问地址:http://服务器IP:9101/
# DEFAULT_USERNAME:默认账号admin
# DEFAULT_PASSWORD:默认密码admin
# Git 地址:https://github.com/dushixiang/kafka-# map/blob/master/README-zh_CN.md
docker run -d --name kafka-map \
--network app-kafka \
-p 9101:8080 \
-v /opt/kafka-map/data:/usr/local/kafka-map/data \
-e DEFAULT_USERNAME=admin \
-e DEFAULT_PASSWORD=admin \
--restart always dushixiang/kafka-map:latest

四、验证是否部署成功
1、查看zookeeper中有关kafka的配置
docker exec -it zookeeper-server /bin/bash
cd /bin
sh zkCli.sh -server 127.0.0.1:2181
[zk: 127.0.0.1:2181(CONNECTED) 7] ls /
[zookeeper, kafka]
[zk: 127.0.0.1:2181(CONNECTED) 8] ls /kafka
[cluster, controller, controller_epoch, brokers, admin, isr_change_notification, consumers, config]
[zk: 127.0.0.1:2181(CONNECTED) 9]
2、进入kafka容器查看
[root@blog]$docker exec -it zookeeper-server bash
[root@blog]$ ps -ef
PID USER TIME COMMAND
1 root 0:08 /usr/lib/jvm/java-1.8-openjdk/jre/bin/java -Xmx1G -Xms1G -server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -XX:MaxIn
502 root 0:00 /bin/sh
506 root 0:00 ps -ef
# 创建主题
kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic mytest
# 查看主题
kafka-topics.sh --list --bootstrap-server localhost:9092
# 发送消息
kafka-console-producer.sh --broker-list localhost:9092 --topic mytest
# 接收消息
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic mytest --from-beginning


五、SpringBoot整合Kafka
1、导入依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
2、修改配置
spring:
kafka:
bootstrap-servers: 192.168.58.130:9092 #部署linux的kafka的ip地址和端口号
producer:
# 发生错误后,消息重发的次数。
retries: 1
#当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。
batch-size: 16384
# 设置生产者内存缓冲区的大小。
buffer-memory: 33554432
# 键的序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 值的序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。
# acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。
# acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
acks: 1
consumer:
# 自动提交的时间间隔 在spring boot 2.X 版本中这里采用的是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5D
auto-commit-interval: 1S
# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
# latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)
# earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录
auto-offset-reset: earliest
# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量
enable-auto-commit: false
# 键的反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 值的反序列化方式
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# 在侦听器容器中运行的线程数。
concurrency: 5
#listner负责ack,每调用一次,就立即commit
ack-mode: manual_immediate
missing-topics-fatal: false
本次测试:linux地址:192.168.58.130
**spring.kafka.bootstrap-servers=**192.168.58.130:9092
**advertised.listeners=**192.168.58.130:9092
3、生产者
import com.alibaba.fastjson.JSON;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
/**
* 事件的生产者
*/
@Slf4j
@Component
public class KafkaProducer {
@Autowired
public KafkaTemplate kafkaTemplate;
/** 主题 */
public static final String TOPIC_TEST = "Test";
/** 消费者组 */
public static final String TOPIC_GROUP = "test-consumer-group";
public void send(Object obj){
String obj2String = JSON.toJSONString(obj);
log.info("准备发送消息为:{}",obj2String);
//发送消息
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(TOPIC_TEST, obj);
//回调
future.addCallback(new ListenableFutureCallback<SendResult<String, Object>>() {
@Override
public void onFailure(Throwable ex) {
//发送失败的处理
log.info(TOPIC_TEST + " - 生产者 发送消息失败:" + ex.getMessage());
}
@Override
public void onSuccess(SendResult<String, Object> result) {
//成功的处理
log.info(TOPIC_TEST + " - 生产者 发送消息成功:" + result.toString());
}
});
}
}
4、消费者
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Component;
import java.util.Optional;
/**
* 事件消费者
*/
@Component
public class KafkaConsumer {
private Logger logger = LoggerFactory.getLogger(org.apache.kafka.clients.consumer.KafkaConsumer.class);
@KafkaListener(topics = KafkaProducer.TOPIC_TEST,groupId = KafkaProducer.TOPIC_GROUP)
public void topicTest(ConsumerRecord<?,?> record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic){
Optional<?> message = Optional.ofNullable(record.value());
if (message.isPresent()) {
Object msg = message.get();
logger.info("topic_test 消费了: Topic:" + topic + ",Message:" + msg);
ack.acknowledge();
}
}
}
5、测试发送消息
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以点击这里获取!](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
essage:" + msg);
ack.acknowledge();
}
}
}
5、测试发送消息
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以点击这里获取!](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 1089
1089











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









