







 文章详细解释了JavaHashMap在初次put操作时的初始化过程,以及后续扩容策略,包括table的初始化时机、长度、阈值计算,以及putVal方法中的扩容逻辑。重点强调了负载因子和阈值的重要性,以及数组下标的计算方式。
文章详细解释了JavaHashMap在初次put操作时的初始化过程,以及后续扩容策略,包括table的初始化时机、长度、阈值计算,以及putVal方法中的扩容逻辑。重点强调了负载因子和阈值的重要性,以及数组下标的计算方式。
if (oldCap > 0) { // 条件不满足,往下走
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults 走到这里,进行默认初始化
newCap = DEFAULT_INITIAL_CAPACITY; // DEFAULT_INITIAL_CAPACITY = 1 << 4 = 16, newCap = 16;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); // newThr = 0.75 * 16 = 12;
}
if (newThr == 0) { // 条件不满足
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr; // threshold = 12; 重置阀值为12
@SuppressWarnings({“rawtypes”,“unchecked”})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; // 初始化 newTab, length = 16;
table = newTab; // table 初始化完成, length = 16;
if (oldTab != null) { // 此时条件不满足,后续扩容的时候,走此if分支 将数组元素复制到新数组
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab; // 新数组
}
自此,问题 1 的答案就明了了
table 的初始化时机是什么时候
一般情况下,在第一次 put 的时候,调用 resize 方法进行 table 的初始化(懒初始化,懒加载思想在很多框架中都有应用!)
初始化的 table.length 是多少、阀值(threshold)是多少,实际能容下多少元素
-
默认情况下,table.length = 16; 指定了 initialCapacity 的情况放到问题 5 中分析
-
默认情况下,threshold = 12; 指定了 initialCapacity 的情况放到问题 5 中分析
-
默认情况下,能存放 12 个元素,当存放第 13 个元素后进行扩容
问题 2 :table 的扩容
putVal 源码如下
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don’t change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold) // 当size(已存放元素个数) > thrshold(阀值),进行扩容
resize();
afterNodeInsertion(evict);
return null;
}
还是调用 resize() 进行扩容,但与初始化时不同(注意看注释)
/**
* Initializes or doubles table size. If null, allocates in
* accord with initial capacity target held in field threshold.
* Otherwise, because we are using power-of-two expansion, the
* elements from each bin must either stay at same index, or move
* with a power of two offset in the new table.
*
* @return the table
*/
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table; // 此时的 table != null,oldTab 指向旧的 table
int oldCap = (oldTab == null) ? 0 : oldTab.length; // oldCap = table.length; 第一次扩容时是 16
int oldThr = threshold; // threshold=12, oldThr = 12;
int newCap, newThr = 0;
if (oldCap > 0) { // 条件满足,走此分支
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && // oldCap左移一位; newCap = 16 << 1 = 32;
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold // newThr = 12 << 1 = 24;
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY; // DEFAULT_INITIAL_CAPACITY = 1 << 4 = 16, newCap = 16;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) { // 条件不满足
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr; // threshold = newThr = 24; 重置阀值为 24
@SuppressWarnings({“rawtypes”,“unchecked”})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; // 初始化 newTab, length = 32;
table = newTab; // table 指向 newTab, length = 32;
if (oldTab != null) { // 扩容后,将 oldTab(旧table) 中的元素移到 newTab(新table)中
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e; //
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
自此,问题 2 的答案也就清晰了
什么时候触发扩容,扩容之后的 table.length、阀值各是多少
-
当 size > threshold 的时候进行扩容
-
扩容之后的 table.length = 旧 table.length * 2,
-
扩容之后的 threshold = 旧 threshold * 2
问题 3、4 :2 的 n 次幂
table 是一个数组,那么如何最快的将元素 e 放入数组 ?当然是找到元素 e 在 table 中对应的位置 index ,然后 table[index] = e; 就好了;如何找到 e 在 table 中的位置了 ?
我们知道只能通过数组下标(索引)操作数组,而数组的下标类型又是 int ,如果 e 是 int 类型,那好说,就直接用 e 来做数组下标(若 e > table.length,则可以 e % table.length 来获取下标),可 key - value 中的 key 类型不一定,所以我们需要一种统一的方式将 key 转换成 int ,最好是一个 key 对应一个唯一的 int (目前还不可能, int有范围限制,对转换方法要求也极高),所以引入了 hash 方法
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); // 这里的处理,有兴趣的可以琢磨下;能够减少碰撞
}
实现 key 到 int 的转换(关于 hash,本文不展开讨论)。拿到了 key 对应的 int h 之后,我们最容易想到的对 value 的 put 和 get 操作也许如下
// put
table[h % table.length] = value;
// get
e = table[h % table.length];
直接取模是我们最容易想到的获取下标的方法,但是最高效的方法吗 ?
我们知道计算机中的四则运算最终都会转换成二进制的位运算
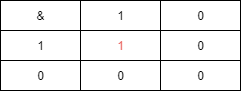
图片
我们可以发现,只有 & 数是1时,& 运算的结果与被 & 数一致
1&1=1;
0&1=0;
1&0=0;
0&0=0;
这同样适用于多位操作数
1010&1111=1010; => 10&15=10;
小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数初中级Java工程师,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》送给大家,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频
如果你觉得这些内容对你有帮助,可以添加下面V无偿领取!(备注Java)

结尾

这不止是一份面试清单,更是一种”被期望的责任“,因为有无数个待面试者,希望从这篇文章中,找出通往期望公司的”钥匙“,所以上面每道选题都是结合我自身的经验于千万个面试题中经过艰辛的两周,一个题一个题筛选出来再次对好答案和格式做出来的,面试的答案也是再三斟酌,深怕误人子弟是小,影响他人仕途才是大过,也希望您能把这篇文章分享给更多的朋友,让他帮助更多的人,帮助他人,快乐自己,最后,感谢您的阅读。
由于细节内容实在太多啦,在这里我花了两周的时间把这些答案整理成一份文档了,在这里只把部分知识点截图出来粗略的介绍,每个小节点里面都有更细化的内容!
qaM1y-1711134484072)]
[外链图片转存中…(img-6wHSfg7G-1711134484073)]
[外链图片转存中…(img-5woc4wdV-1711134484073)]
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频
如果你觉得这些内容对你有帮助,可以添加下面V无偿领取!(备注Java)
[外链图片转存中…(img-n3MSUDMZ-1711134484074)]
结尾
[外链图片转存中…(img-z8KexdBU-1711134484074)]
这不止是一份面试清单,更是一种”被期望的责任“,因为有无数个待面试者,希望从这篇文章中,找出通往期望公司的”钥匙“,所以上面每道选题都是结合我自身的经验于千万个面试题中经过艰辛的两周,一个题一个题筛选出来再次对好答案和格式做出来的,面试的答案也是再三斟酌,深怕误人子弟是小,影响他人仕途才是大过,也希望您能把这篇文章分享给更多的朋友,让他帮助更多的人,帮助他人,快乐自己,最后,感谢您的阅读。
由于细节内容实在太多啦,在这里我花了两周的时间把这些答案整理成一份文档了,在这里只把部分知识点截图出来粗略的介绍,每个小节点里面都有更细化的内容!















 6435
6435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









