







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Python全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。






既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Python知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024c (备注Python)

正文
3.2、连续频率空间插值
为了解决分散数据集的限制,我们解决方案的基础是在客户端之间交换分布信息,以便每个本地客户端都可以访问多源数据分布以学习通用参数。 考虑到禁止共享原始图像,我们建议利用频率空间中固有的信息,这可以将分发(即样式)信息与原始图像分开,以在客户端之间共享而不会造成隐私泄露。 具体来说,给定第k个客户端的样本 )(对于RGB图像,C = 3,对于灰度图像,C = 1),我们可以通过快速傅里叶变换获得其频率空间信号[39]。 ] 作为:
)(对于RGB图像,C = 3,对于灰度图像,C = 1),我们可以通过快速傅里叶变换获得其频率空间信号[39]。 ] 作为:
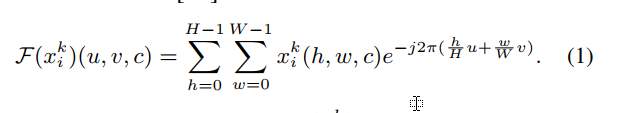
可以将该频率空间信号 )进一步分解为分别反映低电平分布(例如,风格)和振幅分布的振幅谱
)进一步分解为分别反映低电平分布(例如,风格)和振幅分布的振幅谱 )和相位谱
)和相位谱 )。 图像的高级语义(例如,对象)。 为了在各个客户之间交换分配信息,我们首先构造一个分配银行
)。 图像的高级语义(例如,对象)。 为了在各个客户之间交换分配信息,我们首先构造一个分配银行![A=\left [ A{1},...,A{k} \right ]](https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Flatex.codecogs.com%2Fgif.latex%3FA%253D%255Cleft%2520%255B%2520A%255E%257B1%257D%252C...%252CA%255E%257Bk%257D%2520%255Cright%2520%255D&pos_id=img-pvmth9yi-1713134646370) ),其中每个
),其中每个 )包含来自第k个客户端的图像的所有振幅谱,表示
)包含来自第k个客户端的图像的所有振幅谱,表示 )的分布。 然后,该银行就可以作为共享的分销知识供所有客户使用。
)的分布。 然后,该银行就可以作为共享的分销知识供所有客户使用。
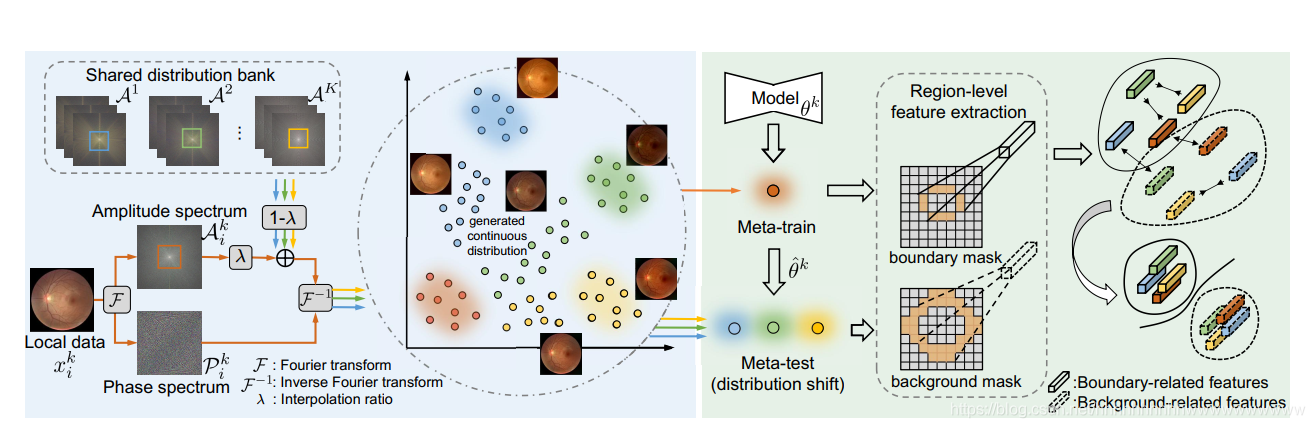
图2.我们在连续频率空间(ELCFS)中提出的情景学习概述。 通过连续的插值机制从频率空间跨客户端交换分布信息,使每个本地客户端都可以访问多源分布。 然后建立一个情景训练范式,以使局部优化暴露于域移位,并进行显式正则化,以促进模棱两可的边界区域的独立于域的特征凝聚和分离,以提高可推广性。
接下来,我们设计一个在频率空间内的连续插值机制,旨在将多源分布信息传输到利用分布库的本地客户端。 如图2的左侧所示,给定客户端k的局部图像xk i,我们可以用分配库A中的振幅频谱替换其振幅频谱的某些低频分量,而其相位频谱不受影响,以保持语义内容。结果,我们可以生成具有变换外观的图像,这些图像表现出其他客户的分布特征。更重要的是,我们不断在本地数据的振幅谱和其他数据的传递的振幅谱之间进行插值 域。 通过这种方式,我们可以受益于专用的密集空间和平滑的分布变化,从而为每个本地客户端丰富已建立的多域分布。 形式上,这是通过从分配库中随机采样振幅谱项 )(n
)(n )k),然后通过在
)k),然后通过在 )和)之间进行插值来合成新的振幅谱来实现的。令
)和)之间进行插值来合成新的振幅谱来实现的。令![M=\mathbb{I}_{(h,w)\epsilon \left [ -\alpha H:\alpha H, -\alpha W:\alpha W \right ]}](https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Flatex.codecogs.com%2Fgif.latex%3FM%253D%255Cmathbb%257BI%257D_%257B%2528h%252Cw%2529%255Cepsilon%2520%255Cleft%2520%255B%2520-%255Calpha%2520H%253A%255Calpha%2520H%252C%2520-%255Calpha%2520W%253A%255Calpha%2520W%2520%255Cright%2520%255D%257D&pos_id=img-ufj0OXMW-1713134648980) )为二元掩码,它控制要交换的振幅谱内的低频分量的比例,其中心区域的值为1,而0在其他地方。 将λ表示为调整由)和)贡献的分布信息量的内插比,生成的新振幅谱相互作用分布为 本地客户端k和外部客户端n表示为:
)为二元掩码,它控制要交换的振幅谱内的低频分量的比例,其中心区域的值为1,而0在其他地方。 将λ表示为调整由)和)贡献的分布信息量的内插比,生成的新振幅谱相互作用分布为 本地客户端k和外部客户端n表示为:
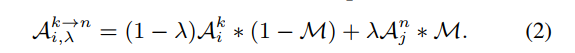
在获得内插的幅度谱 )之后,我们将其与原始相位谱组合起来,以通过傅立叶逆变换
)之后,我们将其与原始相位谱组合起来,以通过傅立叶逆变换 )生成变换后的图像,如下所示:
)生成变换后的图像,如下所示:

4.实验
====
我们在两种医学图像分割任务上广泛评估了我们的方法,即在视网膜眼底图像上进行视盘和杯状分割[40],以及在T2加权MRI上进行前列腺分割[31]。 我们首先与可以纳入联邦范例中的DG方法进行比较,然后提供深入的消融研究以分析我们的方法。
4.1、数据集和评估指标
我们采用来自公共数据集[52、10、40]的4个不同临床中心的视网膜眼底图像进行视盘和杯分割。为了进行预处理,我们将这些数据均匀地裁剪为800×800的磁盘区域,然后将裁剪区域的大小调整为384×384作为网络输入。我们进一步从公共数据集[2、21、31、33]划分的6个不同数据源中收集前列腺T2加权MRI图像,以进行前列腺MRI分割任务。对所有数据进行预处理,以使前列腺区域具有相似的视野,并在轴向平面中将其大小调整为384×384。然后,我们将数据分别归一化为强度值的零均值和单位方差。请注意,对于这两个任务,由于成像条件的变化,从不同临床中心获取的数据呈现出不同的分布。每个数据源的示例情况和样本数量如图3所示。在两个任务中采用了随机旋转,缩放和翻转的数据增强。为了进行评估,我们采用了两个常用的指标:骰子系数(Dice)和Hausdorff距离(HD),分别对整个物体区域和表面形状的分割结果进行定量评估。
4.2、实施细节
在联合学习过程中,所有客户都使用相同的超参数设置,并且使用Adam优化器对本地模型进行了训练,批处理大小为5,Adam动量分别为0.9和0.99。元步长和学习率都设置为1e-3。频率空间中的插值比λ在[0.0,1.0]内随机采样,我们将在消融研究中研究此参数。将超参数α根据经验设置为0.01,以避免在变换后的图像上出现伪像。对来自最后两个反卷积层的激活图进行插值和级联,以提取边界区域周围的语义特征,并且将温度参数τ凭经验设置为0.05。在两个任务中将权重γ设置为0.1和0.5,以平衡训练目标的大小。当全局模型稳定收敛时,我们总共训练了100轮联邦回合,并且每个联邦回合中的本地纪元E都设置为1。该框架由Pytorch库实现,并在两个NVIDIA TitanXp GPU上进行了训练。

图3.眼底图像分割和前列腺MRI分割任务中每个数据源的示例案例和切片编号。
4.3、与DG方法的比较
实验设置:在我们的实验中,我们遵循领域通用化文献中的实践,采用了留一域的策略,即在K-1分布式源域上进行培训,并在一个遗漏的看不见的目标域上进行测试。 这导致眼底图像分割任务的四个通用设置和前列腺MRI分割任务的六个设置。
我们与没有数据集中化并且可以并入联邦范式的本地学习过程的最新技术DG方法进行了比较,包括:JiGen [3]一种有效的自我监督学习方法,可以通过以下方法学习一般表示形式: 解决拼图游戏; BigAug [60]一种执行大量数据转换以规范化通用表示学习的方法。 Epi-FCR [25]一种在域之间定期交换部分模型(分类器或特征提取器)以使模型学习暴露于域移位的方案; RSC [17]一种方法 会随机丢弃主要功能以促进健壮的模型优化。 对于实施,我们遵循其公共代码或书面文件,并在联合设置中进行建立。 我们还将与基准设置进行比较,即使用基本FedAvg [36]算法学习全局模型,而无需使用任何泛化技术。

比较结果:表1给出了视网膜眼底分割的定量结果。我们看到,不同的DG方法可以比FedAvg或多或少地改善整体泛化性能。这归因于它们对本地学习的正则化作用以提取一般表示。与这些方法相比,我们的ELCFS在Dice和 HD既可用于光盘分割,也可用于杯分割。这得益于我们的频率空间插值机制,该机制向本地客户端提供了多域分布。具体来说,对于其他DG方法,他们的本地学习仍然只能访问单个分布,并且无法针对多样化分布空间中的域不变性对特征进行正则化。相反,我们的方法使局部学习能够充分利用多源分布的优势,并显着增强模糊边界区域周围特征的域不变性。此外,我们的ELCFS在所有看不见的域设置上都实现了对FedAvg的持续改进,Dice的整体性能提高了2.02%,HD的整体性能提高了2.86。相对边缘的。我们的ELCFS在六个未见的站点中获得最高的骰子,在大多数站点中获得高清。总体而言,我们的方法将Dice的FedAvg值从85.57%提高到87.39%,将HD值从12.42提高到10.88,优于其他DG方法。图4显示了分割结果,其中有两种情况来自于看不见的领域,无法完成每项任务。可以看出,我们的方法可以准确地分割结构并在未知分布的图像中描绘边界,而其他方法有时则无法做到。

图4.对眼底图像分割(上两行)和前列腺MRI分割(下两束)中不同方法的泛化结果进行定性比较。
4.4、我们方法的消融分析
=============
我们进行消融研究,以研究关于ELCFS的四个关键问题:1)每个组件对模型性能的贡献; 2)插值运算的好处和λ的选择; 3)边界区域周围的语义特征空间如何受我们方法的影响,以及4)参与客户的数量如何影响我们方法的效果。每个组成部分的贡献:我们首先通过从我们的方法中将它们删除以观察模型性能,来验证我们方法中两个关键组成部分的影响,即连续频率空间插值(CFSI)和边界定向情境学习(BEL)。如图5所示,

图5.消融结果,以分析我们方法中两个组件(即CFSI和BEL)的影响。
删除这两个部分中的任何一个都将导致针对这两个任务在不同的看不见的域设置中的泛化性能下降。这是合理的,并且反映了这两个组件如何对我们的方法的性能发挥互补作用,即CFSI生成的分布为学习BEL打下了基础,而BEL则反过来为有效利用生成的分布提供了保证。连续插值在频率空间中的重要性:为了分析ELCFS中连续插值机制的效果,我们使用t-SNE [34]来可视化眼底图像分割中生成图像的分布。如图6(a)所示,

图6.(a)可视化的t-SNE [34],用于在本地客户端(粉红色点)嵌入原始眼底图像以及来自不同客户端(绿色,黄色和蓝色点)的振幅频谱的相应转换图像; (b)在不同的插值比λ设置下,采用固定值或在不同范围内连续采样(带有三个独立运行的误差条)对光盘分割的综合性能。
粉红色的点表示客户端的本地数据,其他点表示使用来自不同客户端的幅度谱生成的转换后的数据。似乎固定λ(左)将导致几个不同的分布,而连续插值机制(右)可以平滑地桥接不同的分布以丰富已建立的多域分布。这促进了局部学习以在预定的密集分布空间中实现域不变性。 然后,我们分析选择λ对模型性能的影响,为此,我们以0.0到1.0的固定值(步长为0.2)进行实验,并在[0.0,0.5],[0.5,1.0]范围内进行连续采样和[0.0,1.0]。如图6(b)所示,与不传输任何分布信息(即λ= 0)相比,将λ> 0设置为固定值可以始终提高模型性能。此外,连续采样可以进一步提高性能,并且[0.0,1.0]的采样范围可产生最佳结果,这反映出连续分布空间对于域泛化的好处。

图7.(a)边界相关特征和背景相关特征之间的余弦距离; (b)我们的方法在有或没有面向边界的元目标的情况下的泛化性能。
模棱两可的边界区域的可辨性:我们绘制了边界相关特征和背景相关特征之间的余弦距离,即E [hi bd hi bg],以分析边界空间周围的语义特征空间如何受到我们方法的影响。在图7(a)中,两条绿线分别表示从训练源域中抽取的样本的ELCFS和FedAvg基线中特征距离的增长。我们可以看到,ELCFS产生了更长的特征距离,表明边界和周围背景区域的特征可以在我们的方法中更好地分离。对于两条黄线,样本特征是从看不见的区域中绘制的。不出所料,该距离不如源域高,但是我们的方法也比FedAvg具有更高的裕度。我们还定量分析了Lboundary对模型性能的影响。从图7(b)中可以看出,从元优化中删除此目标会导致不同任务中的泛化性能出现一致的性能下降。 参与客户数量的影响:我们进一步分析了当参加联合学习的医院数量不同时,我们的方法和FedAvg的泛化性能将受到怎样的影响。

最后
🍅 硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
🍅 技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
🍅 面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
🍅 知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
*
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)
[外链图片转存中…(img-5cGIg0uv-1713134630679)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









