







学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
Spark为结构化数据处理引入了一个称为Spark SQL的编程模块。它提供了一个称为DataFrame(数据框)的编程抽象,DF的底层仍然是RDD,并且可以充当分布式SQL查询引擎。
1、SparkSQL的由来
SparkSQL的前身是Shark。在Hadoop发展过程中,为了给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,Hive应运而生,是当时唯一运行在hadoop上的SQL-on-Hadoop工具。但是,MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,运行效率较低。
后来,为了提高SQL-on-Hadoop的效率,大量的SQL-on-Hadoop工具开始产生,其中表现较为突出的是:
1)MapR的Drill
2)Cloudera的Impala
3)Shark
其中Shark是伯克利实验室Spark生态环境的组件之一,它基于Hive实施了一些改进,比如引入缓存管理,改进和优化执行器等,并使之能运行在Spark引擎上,从而使得SQL查询的速度得到10-100倍的提升。
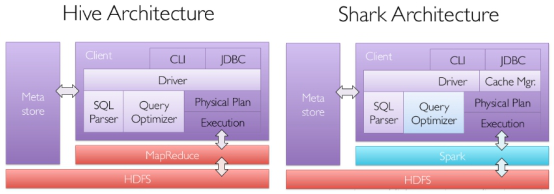
但是,随着Spark的发展,对于野心勃勃的Spark团队来说,Shark对于hive的太多依赖(如采用hive的语法解析器、查询优化器等等),制约了Spark的One Stack rule them all的既定方针,制约了spark各个组件的相互集成,所以提出了sparkSQL项目。
SparkSQL抛弃原有Shark的代码,汲取了Shark的一些优点,如内存列存储(In-Memory Columnar Storage)、Hive兼容性等,重新开发了SparkSQL代码。
由于摆脱了对hive的依赖性,SparkSQL无论在数据兼容、性能优化、组件扩展方面都得到了极大的方便。
2014年6月1日,Shark项目和SparkSQL项目的主持人Reynold Xin宣布:停止对Shark的开发,团队将所有资源放SparkSQL项目上,至此,Shark的发展画上了句话。
2、SparkSql特点
1)引入了新的RDD类型SchemaRDD,可以像传统数据库定义表一样来定义SchemaRDD。
2)在应用程序中可以混合使用不同来源的数据,如可以将来自HiveQL的数据和来自SQL的数据进行Join操作。
3)内嵌了查询优化框架,在把SQL解析成逻辑执行计划之后,最后变成RDD的计算。
二、列存储相关
===========
为什么sparkSQL的性能会得到怎么大的提升呢?
主要sparkSQL在下面几点做了优化:
1、内存列存储(In-Memory Columnar Storage)
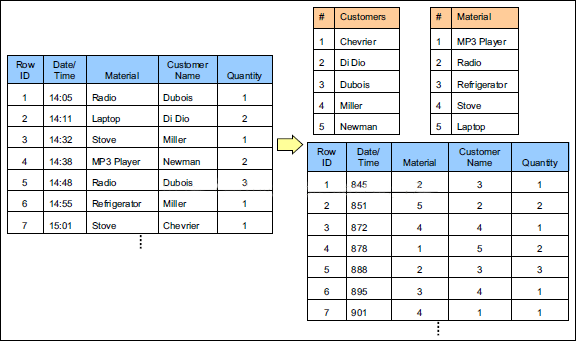
SparkSQL的表数据在内存中存储不是采用原生态的JVM对象存储方式,而是采用内存列存储,如下图所示。
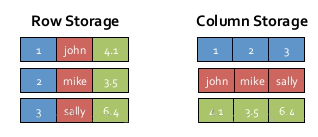
该存储方式无论在空间占用量和读取吞吐率上都占有很大优势。
对于原生态的JVM对象存储方式,每个对象通常要增加12-16字节的额外开销(toString、hashcode等方法),如对于一个270MB的电商的商品表数据,使用这种方式读入内存,要使用970MB左右的内存空间(通常是2~5倍于原生数据空间)。
另外,使用这种方式,每个数据记录产生一个JVM对象,如果是大小为200GB的数据记录,堆栈将产生1.6亿个对象,这么多的对象,对于GC来说,可能要消耗几分钟的时间来处理(JVM的垃圾收集时间与堆栈中的对象数量呈线性相关。显然这种内存存储方式对于基于内存计算的spark来说,很昂贵也负担不起)
2、SparkSql的存储方式
对于内存列存储来说,将所有原生数据类型的列采用原生数组来存储,将Hive支持的复杂数据类型(如array、map等)先序化后并接成一个字节数组来存储。
此外,基于列存储,每列数据都是同质的,所以可以数据类型转换的CPU消耗。此外,可以采用高效的压缩算法来压缩,是的数据更少。比如针对二元数据列,可以用字节编码压缩来实现(010101)
这样,每个列创建一个JVM对象,从而可以快速的GC和紧凑的数据存储;额外的,还可以使用低廉CPU开销的高效压缩方法(如字典编码、行长度编码等压缩方法)降低内存开销;更有趣的是,对于分析查询中频繁使用的聚合特定列,性能会得到很大的提高,原因就是这些列的数据放在一起,更容易读入内存进行计算。
3、行存储VS列存储
目前大数据存储有两种方案可供选择:行存储(Row-Based)和列存储(Column-Based)。 业界对两种存储方案有很多争持,集中焦点是:谁能够更有效地处理海量数据,且兼顾安全、可靠、完整性。从目前发展情况看,关系数据库已经不适应这种巨大的存储量和计算要求,基本是淘汰出局。在已知的几种大数据处理软件中,Hadoop的HBase采用列存储,MongoDB是文档型的行存储,Lexst是二进制型的行存储。
1.列存储
什么是列存储?
列式存储(column-based)是相对于传统关系型数据库的行式存储(Row-basedstorage)来说的。简单来说两者的区别就是如何组织表:
Row-based storage stores atable in a sequence of rows.
Column-based storage storesa table in a sequence of columns.
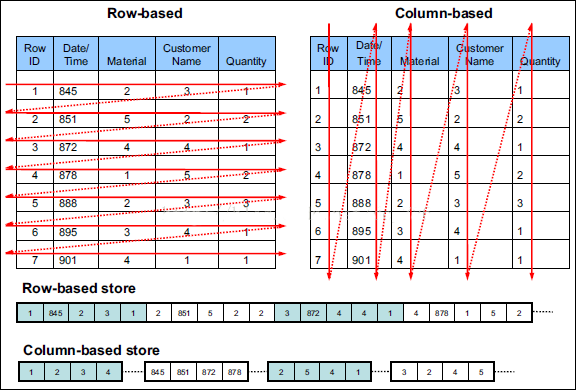
从上图可以很清楚地看到,行式存储下一张表的数据都是放在一起的,但列式存储下都被分开保存了。所以它们就有了如下这些优缺点对比:
1>在数据写入上的对比
1)行存储的写入是一次完成。如果这种写入建立在操作系统的文件系统上,可以保证写入过程的成功或者失败,数据的完整性因此可以确定。
2)列存储由于需要把一行记录拆分成单列保存,写入次数明显比行存储多(意味着磁头调度次数多,而磁头调度是需要时间的,一般在1ms~10ms),再加上磁头需要在盘片上移动和定位花费的时间,实际时间消耗会更大。所以,行存储在写入上占有很大的优势。
3)还有数据修改,这实际也是一次写入过程。不同的是,数据修改是对磁盘上的记录做删除标记。行存储是在指定位置写入一次,列存储是将磁盘定位到多个列上分别写入,这个过程仍是行存储的列数倍。所以,数据修改也是以行存储占优。
2>在数据读取上的对比
1)数据读取时,行存储通常将一行数据完全读出,如果只需要其中几列数据的情况,就会存在冗余列,出于缩短处理时间的考量,消除冗余列的过程通常是在内存中进行的。
2)列存储每次读取的数据是集合的一段或者全部,不存在冗余性问题。
3) 两种存储的数据分布。由于列存储的每一列数据类型是同质的,不存在二义性问题。比如说某列数据类型为整型(int),那么它的数据集合一定是整型数据。这种情况使数据解析变得十分容易。相比之下,行存储则要复杂得多,因为在一行记录中保存了多种类型的数据,数据解析需要在多种数据类型之间频繁转换,这个操作很消耗CPU,增加了解析的时间。所以,列存储的解析过程更有利于分析大数据。
4)从数据的压缩以及更性能的读取来对比
2.优缺点
显而易见,两种存储格式都有各自的优缺点:
1)行存储的写入是一次性完成,消耗的时间比列存储少,并且能够保证数据的完整性,缺点是数据读取过程中会产生冗余数据,如果只有少量数据,此影响可以忽略;数量大可能会影响到数据的处理效率。
2)列存储在写入效率、保证数据完整性上都不如行存储,它的优势是在读取过程,不会产生冗余数据,这对数据完整性要求不高的大数据处理领域,比如互联网,犹为重要。
两种存储格式各自的特性都决定了它们的使用场景。
4、列存储的适用场景
1)一般来说,一个OLAP类型的查询可能需要访问几百万甚至几十亿个数据行,且该查询往往只关心少数几个数据列。例如,查询今年销量最高的前20个商品,这个查询只关心三个数据列:时间(date)、商品(item)以及销售量(sales amount)。商品的其他数据列,例如商品URL、商品描述、商品所属店铺,等等,对这个查询都是没有意义的。
而列式数据库只需要读取存储着“时间、商品、销量”的数据列,而行式数据库需要读取所有的数据列。因此,列式数据库大大地提高了OLAP大数据量查询的效率
OLTP OnLine Transaction Processor 在线联机事务处理系统(比如Mysql,Oracle等产品)
OLAP OnLine Analaysier Processor 在线联机分析处理系统(比如Hive Hbase等)

2)很多列式数据库还支持列族(column group,Bigtable系统中称为locality group),即将多个经常一起访问的数据列的各个值存放在一起。如果读取的数据列属于相同的列族,列式数据库可以从相同的地方一次性读取多个数据列的值,避免了多个数据列的合并。列族是一种行列混合存储模式,这种模式能够同时满足OLTP和OLAP的查询需求。
3)此外,由于同一个数据列的数据重复度很高,因此,列式数据库压缩时有很大的优势。
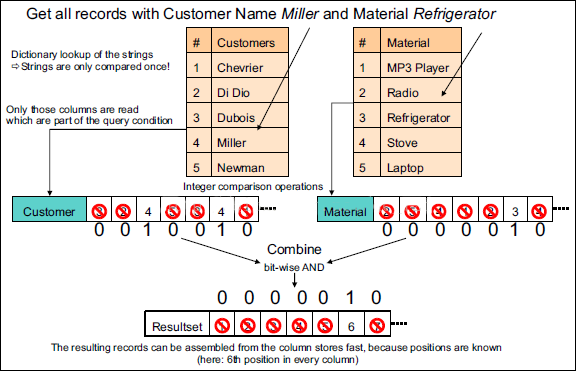
例如,Google Bigtable列式数据库对网页库压缩可以达到15倍以上的压缩率。另外,可以针对列式存储做专门的索引优化。比如,性别列只有两个值,“男”和“女”,可以对这一列建立位图索引:
如下图所示
“男”对应的位图为100101,表示第1、4、6行值为“男”
“女”对应的位图为011010,表示第2、3、5行值为“女”
如果需要查找男性或者女性的个数,只需要统计相应的位图中1出现的次数即可。另外,建立位图索引后0和1的重复度高,可以采用专门的编码方式对其进行压缩。

当然,如果每次查询涉及的数据量较小或者大部分查询都需要整行的数据,列式数据库并不适用。
5、总结
1.行存储特性
传统行式数据库的特性如下:
①数据是按行存储的。
②没有索引的查询使用大量I/O。比如一般的数据库表都会建立索引,通过索引加快查询效率。
③建立索引和物化视图需要花费大量的时间和资源。
④面对查询需求,数据库必须被大量膨胀才能满足需求。
2.列存储特性
列式数据库的特性如下:
①数据按列存储,即每一列单独存放。
②数据即索引。
③只访问查询涉及的列,可以大量降低系统I/O。
④每一列由一个线程来处理,即查询的并发处理性能高。
⑤数据类型一致,数据特征相似,可以高效压缩。比如有增量压缩、前缀压缩算法都是基于列存储的类型定制的,所以可以大幅度提高压缩比,有利于存储和网络输出数据带宽的消耗。
三、SparkSQL入门
================
SparkSql将RDD封装成一个DataFrame对象,这个对象类似于关系型数据库中的表。
1、创建DataFrame对象
DataFrame就相当于数据库的一张表。它是个只读的表,不能在运算过程再往里加元素。
RDD.toDF(“列名”)
scala> val rdd = sc.parallelize(List(1,2,3,4,5,6))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at :21
scala> rdd.toDF(“id”)
res0: org.apache.spark.sql.DataFrame = [id: int]
scala> res0.show#默认只显示20条数据
±–+
| id|
±–+
| 1|
| 2|
| 3|
| 4|
| 5|
| 6|
±–+
scala> res0.printSchema #查看列的类型等属性
root
|-- id: integer (nullable = true)
创建多列DataFrame对象
DataFrame就相当于数据库的一张表。
scala> sc.parallelize(List( (1,“beijing”),(2,“shanghai”) ) )
res3: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[5] at parallelize at :22
scala> res3.toDF(“id”,“name”)
res4: org.apache.spark.sql.DataFrame = [id: int, name: string]
scala> res4.show
±–±-------+
| id| name|
±–±-------+
| 1| beijing|
| 2|shanghai|
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
去网上找其他的知识资源进行进阶。
(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 815
815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









