







最后
Python崛起并且风靡,因为优点多、应用领域广、被大牛们认可。学习 Python 门槛很低,但它的晋级路线很多,通过它你能进入机器学习、数据挖掘、大数据,CS等更加高级的领域。Python可以做网络应用,可以做科学计算,数据分析,可以做网络爬虫,可以做机器学习、自然语言处理、可以写游戏、可以做桌面应用…Python可以做的很多,你需要学好基础,再选择明确的方向。这里给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
👉Python所有方向的学习路线👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

👉Python必备开发工具👈
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

👉Python全套学习视频👈
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

👉实战案例👈
学python就与学数学一样,是不能只看书不做题的,直接看步骤和答案会让人误以为自己全都掌握了,但是碰到生题的时候还是会一筹莫展。
因此在学习python的过程中一定要记得多动手写代码,教程只需要看一两遍即可。

👉大厂面试真题👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
基本可以用于除加密解密算法外的大多数工程应用
9.2.1 随机种子——seed(a=None)
(1)相同种子会产生相同的随机数
(2)如果不设置随机种子,以系统当前时间为默认值
from random import \*
seed(10)
print(random())
seed(10)
print(random())
0.5714025946899135
0.5714025946899135
print(random())
0.4288890546751146
9.2.2 产生随机整数
(1)randint(a, b)——产生[a, b]之间的随机整数
numbers = [randint(1,10) for i in range(10)]
numbers
[3, 5, 6, 3, 8, 4, 8, 10, 7, 1]
(2)randrange(a)——产生[0, a)之间的随机整数 注意是开区间
numbers = [randrange(10) for i in range(10)]
numbers
[6, 3, 0, 0, 7, 4, 9, 1, 8, 1]
(3)randrange(a, b, step)——产生[a, b)之间以setp为步长的随机整数
numbers = [randrange(0, 10, 2) for i in range(10)]
numbers
[2, 6, 8, 4, 8, 2, 0, 0, 6, 2]
9.2.3 产生随机浮点数
(1)random()——产生[0.0, 1.0)之间的随机浮点数
numbers = [random() for i in range(10)]
numbers
[0.9819392547566425,
0.19092611184488173,
0.3486810954900942,
0.9704866291141572,
0.4456072691491385,
0.6807895695768549,
0.14351321471670841,
0.5218569500629634,
0.8648825892767497,
0.26702706855337954]
(2)uniform(a, b)——产生[a, b]之间的随机浮点数
numbers = [uniform(2.1, 3.5) for i in range(10)]
numbers
[2.523598043850906,
3.0245903649048116,
3.4202356766870463,
2.344031169179946,
2.3465252151503173,
3.181989084829388,
2.5592895031615703,
2.413131937436849,
2.8627907782614415,
2.16114212173462]
9.2.4 序列用函数
(1)choice(seq)——从序列类型中随机返回一个元素
choice(['win', 'lose', 'draw'])
'draw'
choice("python")
'h'
(2)choices(seq,weights=None, k)——对序列类型进行k次重复采样,可设置权重
choices(['win', 'lose', 'draw'], k=5)
['draw', 'lose', 'draw', 'draw', 'draw']
choices(['win', 'lose', 'draw'], [4,4,2], k=10)
['lose', 'draw', 'lose', 'win', 'draw', 'lose', 'draw', 'win', 'win', 'lose']
中间的就是权重
(3)shuffle(seq)——将序列类型中元素随机排列,返回打乱后的序列
numbers = ["one", "two", "three", "four"]
shuffle(numbers)
numbers
['four', 'one', 'three', 'two']
(4)sample(pop, k)——从pop类型中随机选取k个元素,以列表类型返回
sample([10, 20, 30, 40, 50], k=3)
[20, 30, 10]
5、概率分布——以高斯分布为例
gauss(mean, std)——生产一个符合高斯分布的随机数
number = gauss(0, 1)
number
0.6331522345532208
多生成几个
import matplotlib.pyplot as plt
res = [gauss(0, 1) for i in range(100000)]
plt.hist(res, bins=1000)
plt.show()
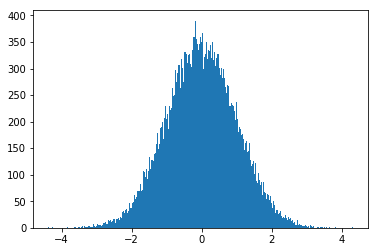
【例1】用random库实现简单的微信红包分配
import random
def red\_packet(total, num):
for i in range(1, num):
per = random.uniform(0.01, total/(num-i+1)\*2) # 保证每个人获得红包的期望是total/num
total = total - per
print("第{}位红包金额: {:.2f}元".format(i, per))
else:
print("第{}位红包金额: {:.2f}元".format(num, total))
red_packet(10, 5)
第1位红包金额: 1.85元
第2位红包金额: 3.90元
第3位红包金额: 0.41元
第4位红包金额: 3.30元
第5位红包金额: 0.54元
import random
import numpy as np
def red\_packet(total, num):
ls = []
for i in range(1, num):
per = round(random.uniform(0.01, total/(num-i+1)\*2), 2) # 保证每个人获得红包的期望是total/num
ls.append(per)
total = total - per
else:
ls.append(total)
return ls
# 重复发十万次红包,统计每个位置的平均值(约等于期望)
res = []
for i in range(100000):
ls = red_packet(10,5)
res.append(ls)
res = np.array(res)
print(res[:10])
np.mean(res, axis=0)
[[1.71 1.57 0.36 1.25 5.11]
[1.96 0.85 1.46 3.29 2.44]
[3.34 0.27 1.9 0.64 3.85]
[1.99 1.08 3.86 1.69 1.38]
[1.56 1.47 0.66 4.09 2.22]
[0.57 0.44 1.87 5.81 1.31]
[0.47 1.41 3.97 1.28 2.87]
[2.65 1.82 1.22 2.02 2.29]
[3.16 1.2 0.3 3.66 1.68]
[2.43 0.16 0.11 0.79 6.51]]
array([1.9991849, 2.0055725, 2.0018144, 2.0022472, 1.991181 ])
【例2】生产4位由数字和英文字母构成的验证码
import random
import string
print(string.digits)
print(string.ascii_letters)
s=string.digits + string.ascii_letters
v=random.sample(s,4)
print(v)
print(''.join(v))
0123456789
abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
['n', 'Q', '4', '7']
nQ47
9.3 collections库——容器数据类型
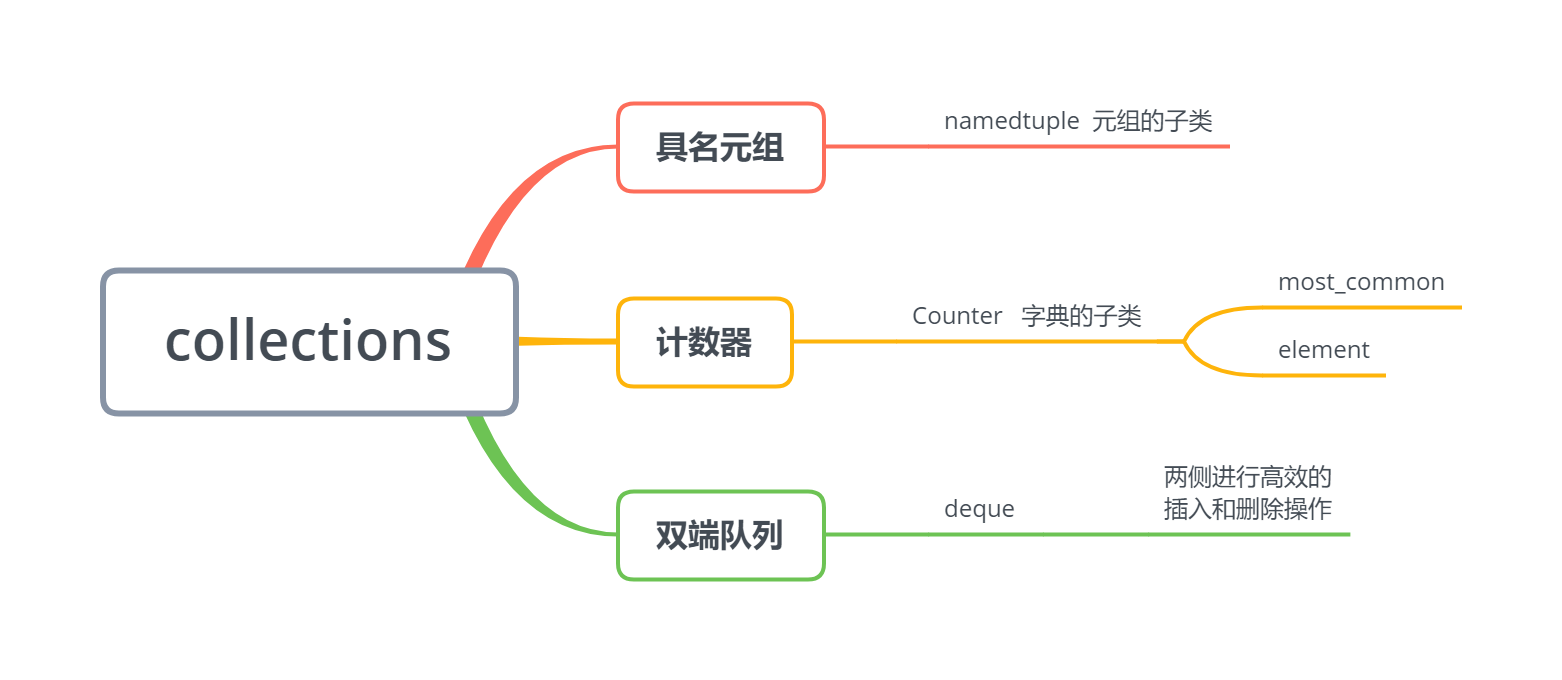
import collections
9.3.1 namedtuple——具名元组
- 点的坐标,仅看数据,很难知道表达的是一个点的坐标
p = (1, 2)
- 构建一个新的元组子类
定义方法如下:typename 是元组名字,field_names 是域名
collections.namedtuple(typename, field_names, \*, rename=False, defaults=None, module=None)
Point = collections.namedtuple("Point", ["x", "y"])
p = Point(1, y=2)
p
Point(x=1, y=2)
- 可以调用属性
print(p.x)
print(p.y)
1
2
- 有元组的性质
print(p[0])
print(p[1])
x, y = p
print(x)
print(y)
1
2
1
2
- 确实是元组的子类
print(isinstance(p, tuple))
True
【例】模拟扑克牌
Card = collections.namedtuple("Card", ["rank", "suit"])
ranks = [str(n) for n in range(2, 11)] + list("JQKA")
suits = "spades diamonds clubs hearts".split()
print("ranks", ranks)
print("suits", suits)
cards = [Card(rank, suit) for rank in ranks
for suit in suits]
cards
ranks ['2', '3', '4', '5', '6', '7', '8', '9', '10', 'J', 'Q', 'K', 'A']
suits ['spades', 'diamonds', 'clubs', 'hearts']
[Card(rank='2', suit='spades'),
Card(rank='2', suit='diamonds'),
Card(rank='2', suit='clubs'),
Card(rank='2', suit='hearts'),
Card(rank='3', suit='spades'),
Card(rank='3', suit='diamonds'),
Card(rank='3', suit='clubs'),
Card(rank='3', suit='hearts'),
Card(rank='4', suit='spades'),
Card(rank='4', suit='diamonds'),
Card(rank='4', suit='clubs'),
Card(rank='4', suit='hearts'),
Card(rank='5', suit='spades'),
Card(rank='5', suit='diamonds'),
Card(rank='5', suit='clubs'),
Card(rank='5', suit='hearts'),
Card(rank='6', suit='spades'),
Card(rank='6', suit='diamonds'),
Card(rank='6', suit='clubs'),
Card(rank='6', suit='hearts'),
Card(rank='7', suit='spades'),
Card(rank='7', suit='diamonds'),
Card(rank='7', suit='clubs'),
Card(rank='7', suit='hearts'),
Card(rank='8', suit='spades'),
Card(rank='8', suit='diamonds'),
Card(rank='8', suit='clubs'),
Card(rank='8', suit='hearts'),
Card(rank='9', suit='spades'),
Card(rank='9', suit='diamonds'),
Card(rank='9', suit='clubs'),
Card(rank='9', suit='hearts'),
Card(rank='10', suit='spades'),
Card(rank='10', suit='diamonds'),
Card(rank='10', suit='clubs'),
Card(rank='10', suit='hearts'),
Card(rank='J', suit='spades'),
Card(rank='J', suit='diamonds'),
Card(rank='J', suit='clubs'),
Card(rank='J', suit='hearts'),
Card(rank='Q', suit='spades'),
Card(rank='Q', suit='diamonds'),
Card(rank='Q', suit='clubs'),
Card(rank='Q', suit='hearts'),
Card(rank='K', suit='spades'),
Card(rank='K', suit='diamonds'),
Card(rank='K', suit='clubs'),
Card(rank='K', suit='hearts'),
Card(rank='A', suit='spades'),
Card(rank='A', suit='diamonds'),
Card(rank='A', suit='clubs'),
Card(rank='A', suit='hearts')]
from random import \*
# 洗牌
shuffle(cards)
cards
[Card(rank='J', suit='hearts'),
Card(rank='A', suit='hearts'),
Card(rank='3', suit='hearts'),
Card(rank='8', suit='hearts'),
Card(rank='K', suit='hearts'),
Card(rank='7', suit='spades'),
Card(rank='5', suit='hearts'),
Card(rank='A', suit='spades'),
Card(rank='10', suit='spades'),
Card(rank='J', suit='diamonds'),
Card(rank='K', suit='clubs'),
Card(rank='4', suit='spades'),
Card(rank='2', suit='diamonds'),
Card(rank='Q', suit='spades'),
Card(rank='A', suit='clubs'),
Card(rank='A', suit='diamonds'),
Card(rank='6', suit='hearts'),
Card(rank='7', suit='diamonds'),
Card(rank='5', suit='diamonds'),
Card(rank='10', suit='clubs'),
Card(rank='8', suit='clubs'),
Card(rank='9', suit='clubs'),
Card(rank='6', suit='clubs'),
Card(rank='6', suit='diamonds'),
Card(rank='5', suit='clubs'),
Card(rank='3', suit='diamonds'),
Card(rank='4', suit='hearts'),
Card(rank='3', suit='clubs'),
Card(rank='7', suit='hearts'),
Card(rank='2', suit='spades'),
Card(rank='J', suit='clubs'),
Card(rank='9', suit='spades'),
Card(rank='J', suit='spades'),
Card(rank='10', suit='hearts'),
Card(rank='2', suit='clubs'),
Card(rank='8', suit='diamonds'),
Card(rank='6', suit='spades'),
Card(rank='10', suit='diamonds'),
Card(rank='9', suit='hearts'),
Card(rank='3', suit='spades'),
Card(rank='8', suit='spades'),
Card(rank='Q', suit='clubs'),
Card(rank='Q', suit='hearts'),
Card(rank='5', suit='spades'),
Card(rank='7', suit='clubs'),
Card(rank='4', suit='clubs'),
Card(rank='2', suit='hearts'),
Card(rank='K', suit='diamonds'),
Card(rank='K', suit='spades'),
Card(rank='Q', suit='diamonds'),
Card(rank='4', suit='diamonds'),
Card(rank='9', suit='diamonds')]
# 随机抽一张牌
choice(cards)
Card(rank='4', suit='hearts')
# 随机抽多张牌
sample(cards, k=5)
[Card(rank='4', suit='hearts'),
Card(rank='2', suit='clubs'),
Card(rank='Q', suit='diamonds'),
Card(rank='9', suit='spades'),
Card(rank='10', suit='hearts')]
9.3.2 Counter——计数器工具
from collections import Counter
s = "牛奶奶找刘奶奶买牛奶"
colors = ['red', 'blue', 'red', 'green', 'blue', 'blue']
cnt_str = Counter(s)
cnt_color = Counter(colors)
print(cnt_str)
print(cnt_color)
Counter({'奶': 5, '牛': 2, '找': 1, '刘': 1, '买': 1})
Counter({'blue': 3, 'red': 2, 'green': 1})
- 是字典的一个子类
print(isinstance(Counter(), dict))
True
- 最常见的统计——most_commom(n)
提供 n 个频率最高的元素和计数
cnt_color.most_common(2)
[('blue', 3), ('red', 2)]
- 元素展开——elements()
list(cnt_str.elements())
['牛', '牛', '奶', '奶', '奶', '奶', '奶', '找', '刘', '买']
- 其他一些加减操作
c = Counter(a=3, b=1)
d = Counter(a=1, b=2)
c+d
Counter({'a': 4, 'b': 3})
【例】从一副牌中抽取10张,大于10的比例有多少
cards = collections.Counter(tens=16, low_cards=36)
seen = sample(list(cards.elements()), k=10)
print(seen)
['tens', 'low_cards', 'low_cards', 'low_cards', 'tens', 'tens', 'low_cards', 'low_cards', 'low_cards', 'low_cards']
seen.count('tens') / 10
0.3
9.3.3 deque——双向队列
列表访问数据非常快速
插入和删除操作非常慢——通过移动元素位置来实现
特别是 insert(0, v) 和 pop(0),在列表开始进行的插入和删除操作
双向队列可以方便的在队列两边高效、快速的增加和删除元素
from collections import deque
d = deque('cde')
d
deque(['c', 'd', 'e'])
d.append("f") # 右端增加
d.append("g")
d.appendleft("b") # 左端增加
d.appendleft("a")
d
deque(['a', 'b', 'c', 'd', 'e', 'f', 'g'])
d.pop() # 右端删除
d.popleft() # 左端删除
d
deque(['b', 'c', 'd', 'e', 'f'])
deque 其他用法可参考官方文档
9.4 itertools库——迭代器
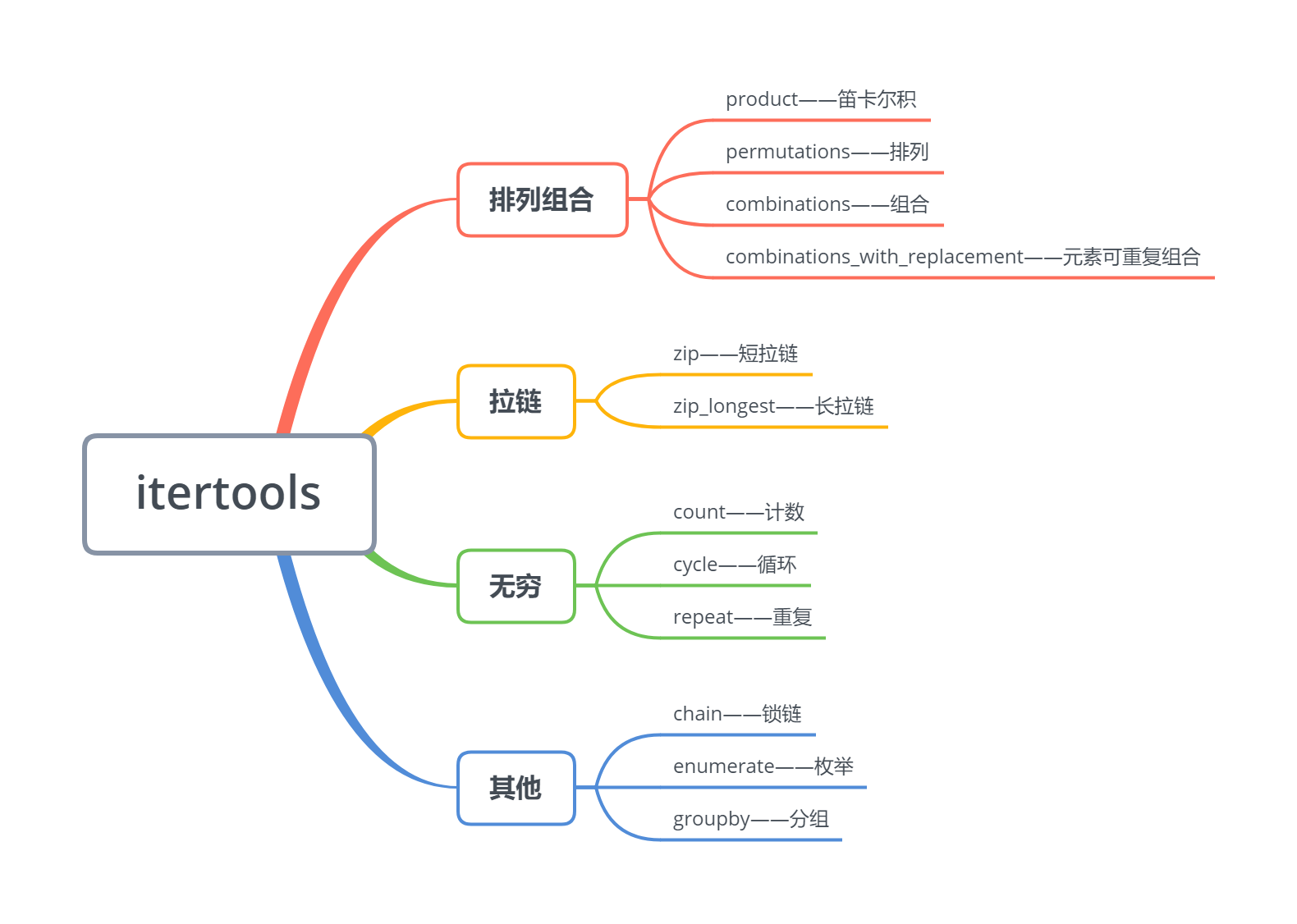
9.4.1 排列组合迭代器
(1)product——笛卡尔积
import itertools
for i in itertools.product('ABC', '01'):
print(i)
('A', '0')
('A', '1')
('B', '0')
('B', '1')
('C', '0')
('C', '1')
for i in itertools.product('ABC', repeat=3): # 相当于3组ABC的笛卡尔积
print(i)
('A', 'A', 'A')
('A', 'A', 'B')
('A', 'A', 'C')
('A', 'B', 'A')
('A', 'B', 'B')
('A', 'B', 'C')
('A', 'C', 'A')
('A', 'C', 'B')
('A', 'C', 'C')
('B', 'A', 'A')
('B', 'A', 'B')
('B', 'A', 'C')
('B', 'B', 'A')
('B', 'B', 'B')
('B', 'B', 'C')
('B', 'C', 'A')
('B', 'C', 'B')
('B', 'C', 'C')
('C', 'A', 'A')
('C', 'A', 'B')
('C', 'A', 'C')
('C', 'B', 'A')
('C', 'B', 'B')
('C', 'B', 'C')
('C', 'C', 'A')
('C', 'C', 'B')
('C', 'C', 'C')
(2) permutations——排列
for i in itertools.permutations('ABCD', 3): # 3 是排列的长度
print(i)
('A', 'B', 'C')
('A', 'B', 'D')
('A', 'C', 'B')
('A', 'C', 'D')
('A', 'D', 'B')
('A', 'D', 'C')
('B', 'A', 'C')
('B', 'A', 'D')
('B', 'C', 'A')
('B', 'C', 'D')
('B', 'D', 'A')
('B', 'D', 'C')
('C', 'A', 'B')
('C', 'A', 'D')
('C', 'B', 'A')
('C', 'B', 'D')
('C', 'D', 'A')
('C', 'D', 'B')
('D', 'A', 'B')
('D', 'A', 'C')
('D', 'B', 'A')
('D', 'B', 'C')
('D', 'C', 'A')
('D', 'C', 'B')
for i in itertools.permutations(range(3)):
print(i)
(0, 1, 2)
(0, 2, 1)
(1, 0, 2)
(1, 2, 0)
(2, 0, 1)
(2, 1, 0)
(3)combinations——组合 其结果元素不能重复
for i in itertools.combinations('ABCD', 2): # 2是组合的长度
print(i)
('A', 'B')
('A', 'C')
('A', 'D')
('B', 'C')
('B', 'D')
('C', 'D')
for i in itertools.combinations(range(4), 3):
print(i)
(0, 1, 2)
(0, 1, 3)
(0, 2, 3)
(1, 2, 3)
(4)combinations_with_replacement——元素可重复组合
for i in itertools.combinations_with_replacement('ABC', 2): # 2是组合的长度
print(i)
('A', 'A')
('A', 'B')
('A', 'C')
('B', 'B')
('B', 'C')
('C', 'C')
for i in itertools.product('ABC',repeat=2):
print(i)
('A', 'A')
('A', 'B')
('A', 'C')
('B', 'A')
('B', 'B')
('B', 'C')
('C', 'A')
('C', 'B')
('C', 'C')
9.4.2 拉链
(1)zip——短拉链
把相同位置上的元素组合在一起
for i in zip("ABC", "012", "xyz"):
print(i)
('A', '0', 'x')
('B', '1', 'y')
('C', '2', 'z')
长度不一时,执行到最短的对象处,就停止
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典


简历模板
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 183
183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









